通过一周左右的研究,对规则引擎有了一定的了解。现在写点东西跟大家一起交流,本文主要针对RETE算法进行描述。我的文笔不太好,如果有什么没讲明白的或是说错的地方,请给我留言。
首先申明,我的帖子借鉴了网上很流行的一篇帖子,好像是来自CSDN;还有一点,我不想做太多的名词解释,因为我也不是个研究很深的人,定义的不好怕被笑话。
好现在我们开始。
首先介绍一些网上对于规则引擎比较好的帖子。
1、 来自JAVA视频网
http://forum.javaeye.com/viewtopic.php?t=7803&postdays=0&postorder=asc&start=0
2、 RETE算法的最原始的描述,我不知道在哪里找到的,想要的人可以留下E-mail
3、 CMU的一位博士生的毕业论文,个人觉得非常好,我的很多观点都是来自这里的,要的人也可以给我发mail mailto:ipointer@163.com
接着统一一下术语,很多资料里的术语都非常混乱。
1、 facts 事实,我们实现的时候,会有一个事实库。用F表示。
2、 patterns 模板,事实的一个模型,所有事实库中的事实都必须满足模板中的一个。用P表示。
3、 conditions 条件,规则的组成部分。也必须满足模板库中的一条模板。用C表示。我们可以这样理解facts、patterns、conditions之间的关系。Patterns是一个接口,conditions则是实现这个接口的类,而facts是这个类的实例。
4、 rules 规则,由一到多个条件构成。一般用and或or连接conditions。用R表示。
5、 actions 动作,激活一条rule执行的动作。我们这里不作讨论。
6、 还有一些术语,如:working-memory、production-memory,跟这里的概念大同小异。
7、 还有一些,如:alpha-network、beta-network、join-node,我们下面会用到,先放一下,一会讨论。
引用一下网上很流行的例子,我觉得没讲明白,我在用我的想法解释一下。
假设在规则记忆中有下列三条规则
if A(x) and B(x) and C(y) then add D(x)
if A(x) and B(y) and D(x) then add E(x)
if A(x) and B(x) and E(x) then delete A(x)
RETE算法会先将规则编译成下列的树状架构排序网络
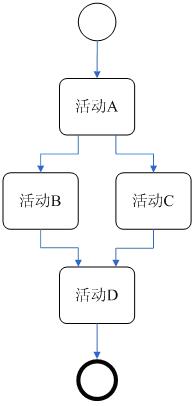
而工作记忆内容及顺序为{A(1),A(2),B(2),B(3),B(4),C(5)},当工作记忆依序进入网络后,会依序储存在符合条件的节点中,直到完全符合条件的推论规则推出推论。以上述例子而言, 最后推得D(2)。
让我们来分析这个例子。
模板库:(这个例子中只有一个模板,算法原描述中有不同的例子, 一般我们会用tuple,元组的形式来定义facts,patterns,condition)
P: (?A , ?x) 其中的A可能代表一定的操作,如例子中的A,B,C,D,E ; x代表操作的参数。看看这个模板是不是已经可以描述所有的事实。
条件库:(这里元组的第一项代表实际的操作,第二项代表形参)
C1: (A , <x>)
C2: (B , <x>)
C3: (C , <y>)
C4: (D , <x>)
C5: (E , <x>)
C6: (B , <y>)
事实库:(第二项代表实参)
F1: (A,1)
F2: (A,2)
F3: (B,2)
F4: (B,3)
F5: (B,4)
F6: (C,5)
规则库:
R1: c1^c2^c3
R2: c1^c2^c4
R3: c1^c2^c5
有人可能会质疑R1: c1^c2^c3,没有描述出,原式中:
if A(x) and B(x) and C(y) then add D(x),A=B的关系。但请仔细看一下,这一点已经在条件库中定义出来了。
下面我来描述一下,规则引擎中RETE算法的实现。
首先,我们要定一些规则,根据这些规则,我们的引擎可以编译出一个树状结构,上面的那张图中是一种简易的表现,其实在实现的时候不是这个样子的。
这就是beta-network出场的时候了,根据rules我们就可以确定beta-network,下面,我就画出本例中的beta-network,为了描述方便,我把alpha-network也画出来了。
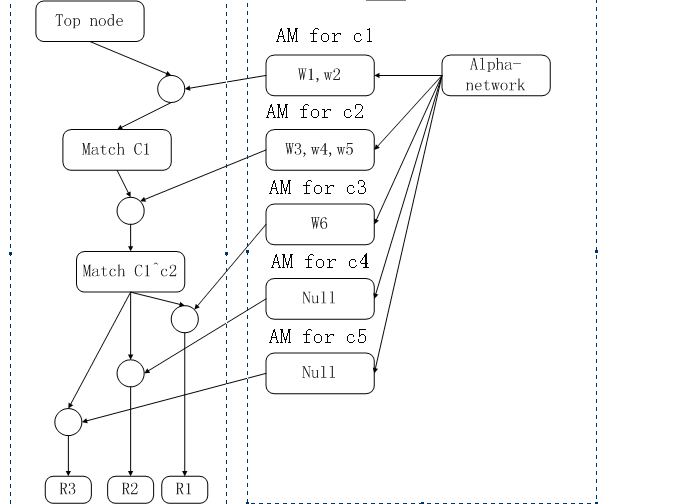
上图中,左边的部分就是beta-network,右边是alpha-network,圆圈是join-node.
从上图中,我们可以验证,在beta-network中,表现出了rules的内容,其中r1,r2,r3共享了许多BM和join-node,这是由于这些规则中有共同的部分,这样能加快match的速度。
右边的alpha-network是根据事实库构建的,其中除alpha-network节点的节点都是根据每一条condition,从事实库中match过来的,这一过程是静态的,即在编译构建网络的过程中已经建立的。只要事实库是稳定的,即没有大幅度的变化,RETE算法的执行效率应该是非常高的,其原因就是已经通过静态的编译,构建了alpha-network。我们可以验证一下,满足c1的事实确实是w1,w2。
下面我们就看一下,这个算法是怎么来运行的,即怎么来确定被激活的rules的。从top-node往下遍历,到一个join-node,与AM for c1的节点汇合,运行到match c1节点。此时,match c1节点的内容就是:w1,w2。继续往下,与AM for c2汇合(所有可能的组合应该是w1^w3,w1^w4,w1^w5,w2^w3,w2^w4,w2^w5),因为c1^c2要求参数相同,因此,match c1^c2的内容是:w2^w3。再继续,这里有一个扇出(fan-out),其中只有一个join-node可以被激活,因为旁边的AM只有一个非空。因此,也只有R1被激活了。
解决扇出带来的效率降低的问题,我们可以使用hashtable来解决这个问题。
RETE算法还有一些问题,如:facts库变化,我们怎么才能高效的重建alpha-network,同理包括rules的变化对beta-network的影响。这一部分我还没细看,到时候再贴出来吧。
有疑问加站长微信联系(非本文作者)




