
内存管理
在开始探索 Go 调优技术和工具之前,我们需要先了解一下 Go 内存模型,它可以帮助我们理解内存是如何使用的。
Go 实现的是 并行的 标记-清除垃圾回收器。在 传统的 标记-清除模型中,垃圾回收器会先让程序停下来(也就是,“stop the world”),然后查找已经失效的对象,并把这些对象清理掉(也就是,释放内存)。因为程序在运行中会移动引用(references),导致垃圾的识别和清理出现困难。同时,垃圾回收也会导致延迟和其他的问题。在 Go 语言中 GC 是并发执行的,所以 GC 执行时,用户可能不会注意到暂停或者延迟。
调优方式
要监控程序性能,有下面几种方式:
- Timers: 计时器,用于基准测试,比较程序 修改前 与 修改后 的差异。
- Profilers: 专业的调优工具,用于更高级的程序验证。
工具矩阵
| 优点 | 缺点 | |
|---|---|---|
| ReadMemStats | - 简单、快速、易用。 - 仅描述内存使用情况。 |
- 需要改代码。 |
| pprof | - 详述CPU和内存使用情况。 - 可以远程分析。 - 可以生成图像。 |
- 需要改代码。 - 需调用API。 |
| trace | - 帮助分析过程数据。 - 强大的调试界面。 - 易实现问题区域的可视化。 |
- 需要改代码。 - UI界面复杂。 - 理解需要一点时间。 |
分析步骤
无论你用哪一种分析工具,有一个通用的原则:
- 识别更高层面的瓶颈
- 例如,你可能发现了一个长时间运行的函数。
- 减少操作量
- 找出可替换的方法,减少时间消耗, 或者调用次数。
- 找出可替换的方法,减少内存分配量。
- 向下挖掘数据
- 使用工具,找出更低层、更细节的数据。
思考性能更好的算法或者数据结构;找到更简单的处理方式;从实效角度审视你的代码。
基本用例
我们看一段简单的程序,它是用 Go 1.9.2 编写的:
package main
import (
"log"
)
// bigBytes 函数分配了大约 100 MB 内存
func bigBytes() *[]byte {
s := make([]byte, 100000000)
return &s
}
func main() {
for i := 0; i < 10; i++ {
s := bigBytes()
if s == nil {
log.Println("oh noes")
}
}
}
执行这个程序大概用了 0.2s。
这个程序运行的不算慢,我们仅仅用它来衡量内存使用情况。
ReadMemStats
关于内存分配的情况,最简单的方式是利用 runtime 包的 MemStats。
在下面的代码片段中,我们调整了 main 函数,打印出详细的内存统计信息。
func main() {
var mem runtime.MemStats
fmt.Println("memory baseline...")
runtime.ReadMemStats(&mem)
log.Println(mem.Alloc)
log.Println(mem.TotalAlloc)
log.Println(mem.HeapAlloc)
log.Println(mem.HeapSys)
for i := 0; i < 10; i++ {
s := bigBytes()
if s == nil {
log.Println("oh noes")
}
}
fmt.Println("memory comparison...")
runtime.ReadMemStats(&mem)
log.Println(mem.Alloc)
log.Println(mem.TotalAlloc)
log.Println(mem.HeapAlloc)
log.Println(mem.HeapSys)
}
运行程序,可以看到下面的结果:
memory baseline…
2017/10/29 08:51:56 56480
2017/10/29 08:51:56 56480
2017/10/29 08:51:56 56480
2017/10/29 08:51:56 786432
memory comparison...
2017/10/29 08:51:56 200074312
2017/10/29 08:51:56 1000144520
2017/10/29 08:51:56 200074312
2017/10/29 08:51:56 200704000
这样我们可以看到,程序在启动时和在结束时(也就是通过 bigBytes 函数分配了大量内存后),内存分配上的差异。TotalAlloc 和 HeapAlloc 是我们最关心的两项。
总体内存分配(total allocations)指的是累计的内存分配总量(这个值在内存释放后 不会 变小)。堆内存分配(heap allocations)指的是在观测时,实时的内存分配情况,包括可达和不可达的对象(例如,垃圾回收器还没有释放的对象)。要意识到,观测后实际在用内存(in use)可能会更少。
更多信息可参考MemStats docs,(包含 Mallocs 或者 Frees)。
Pprof
Pprof是一款可视化的性能分析工具。用于确定应用程序运行过程中的 CPU 和内存使用情况。
可以通过下面的方式安装:
go get github.com/google/pprof
我们先理解性能概要(profile)的定义:
性能概要(profile)是由多个堆栈跟踪组成的。堆栈跟踪能提供特殊事件(比如,内存分配)的调用顺序。包(Packages)可以创建、维护各自的性能概要信息。最常见的用途就是追踪资源的使用,而这些资源使用后必须被明确的关闭(closed),比如文件的操作、网络连接的关闭。– pkg/runtime/pprof
使用这个工具,有下面几种方式:
- 开发时在程序中加入指令代码,生成分析用的
.profile文件。 - 通过 web server 远程分析程序(不明确生产
.profile文件)。
注意: 性能概要文件不一定带有
.profile后缀名 (文件类型可以自己定义)
在开发时生成 .profile
在这一段,我们研究一下性能分析,涵盖 CPU 和内存的分配情况。从 CPU 性能分析开始。
CPU 分析
在下面的例子中,我们导入了 "runtime/pprof" 包,并增加了相关的 API 调用,目的是记录 CPU 的数据:
package main
import (
"log"
"os"
"runtime/pprof"
)
// bigBytes 函数每次分配 100 MB 内存
func bigBytes() *[]byte {
s := make([]byte, 100000000)
return &s
}
func main() {
pprof.StartCPUProfile(os.Stdout)
defer pprof.StopCPUProfile()
for i := 0; i < 10; i++ {
s := bigBytes()
if s == nil {
log.Println("oh noes")
}
}
}
注意:为了简单明了,我们使用了
os.Stdout(不在程序中创建文件)而是利用 shell 重定向输出,用于创建性能概要文件。
然后编译、运行,将性能数据保存到文件:
go build -o app && time ./app > cpu.profile
最后,使用 go tool 命令,以交互的方式检查数据:
go tool pprof cpu.profile
可以看到交互提示符 (pprof),执行 top 命令,输出如下信息:
(pprof) top
Showing nodes accounting for 180ms, 100% of 180ms total
flat flat% sum% cum cum%
180ms 100% 100% 180ms 100% runtime.memclrNoHeapPointers /.../src/runtime/memclr_amd64.s
0 0% 100% 180ms 100% main.bigBytes /.../code/go/profiling/main.go (inline)
0 0% 100% 180ms 100% main.main /.../code/go/profiling/main.go
0 0% 100% 180ms 100% runtime.(*mheap).alloc /.../src/runtime/mheap.go
0 0% 100% 180ms 100% runtime.largeAlloc /.../src/runtime/malloc.go
0 0% 100% 180ms 100% runtime.main /.../src/runtime/proc.go
0 0% 100% 180ms 100% runtime.makeslice /.../src/runtime/slice.go
0 0% 100% 180ms 100% runtime.mallocgc /.../src/runtime/malloc.go
0 0% 100% 180ms 100% runtime.mallocgc.func1 /.../src/runtime/malloc.go
0 0% 100% 180ms 100% runtime.systemstack /.../src/runtime/asm_amd64.s
这表示 runtime.memclrNoHeapPointers 占用了最多的CPU时间。
我们一行一行的分解程序,可以更准确地观察 CPU 的使用情况。
使用 list 命令,通过 main.main 可以看到主函数 main 。
让我们列出 main 名称空间下的所有函数:
(pprof) list main\.
Total: 180ms
ROUTINE ======================== main.bigBytes in /.../go/profiling/main.go
0 180ms (flat, cum) 100% of Total
. . 6: "runtime/pprof"
. . 7:)
. . 8:
. . 9:// bigBytes allocates 10 sets of 100 megabytes
. . 10:func bigBytes() *[]byte {
. 180ms 11: s := make([]byte, 100000000)
. . 12: return &s
. . 13:}
. . 14:
. . 15:func main() {
. . 16: pprof.StartCPUProfile(os.Stdout)
ROUTINE ======================== main.main in /.../code/go/profiling/main.go
0 180ms (flat, cum) 100% of Total
. . 15:func main() {
. . 16: pprof.StartCPUProfile(os.Stdout)
. . 17: defer pprof.StopCPUProfile()
. . 18:
. . 19: for i := 0; i < 10; i++ {
. 180ms 20: s := bigBytes()
. . 21: if s == nil {
. . 22: log.Println("oh noes")
. . 23: }
. . 24: }
. . 25:}
好了,我们可以看到 180ms 都花费在 bigBytes 函数。在 bigBytes 函数中,绝大部分时间花费在分配内存命令上 make([]byte, 100000000)。
内存分析
在进入后面的主题前,我们看一下如何收集内存使用信息。
我们要稍微调整一下程序,把 StartCPUProfile 替换为 WriteHeapProfile(并把这个调用移到 main 函数的底部,如果在 main 函数的顶部调用,内存分配还没有开始),并且删掉 StopCPUProfile 调用。(通过快照的方式记录堆的使用情况,而不是像 CPU 性能分析那样,是一个持续运行的过程):
package main
import (
"log"
"os"
"runtime/pprof"
)
// bigBytes allocates 10 sets of 100 megabytes
func bigBytes() *[]byte {
s := make([]byte, 100000000)
return &s
}
func main() {
for i := 0; i < 10; i++ {
s := bigBytes()
if s == nil {
log.Println("oh noes")
}
}
pprof.WriteHeapProfile(os.Stdout)
}
再一次,我们编译、执行程序,并重定向 stdout 到文件(为简单起见),如果你愿意,也可以在程序中动态创建一个文件:
go build -o app && time ./app > memory.profile
现在我们就可以运行 pprof ,以交互的方式查看内存分析数据:
go tool pprof memory.profile
运行 top 命令,可以看到下面的输出:
(pprof) top
Showing nodes accounting for 95.38MB, 100% of 95.38MB total
flat flat% sum% cum cum%
95.38MB 100% 100% 95.38MB 100% main.bigBytes /...ain.go (inline)
0 0% 100% 95.38MB 100% main.main /.../profiling/main.go
0 0% 100% 95.38MB 100% runtime.main /.../runtime/proc.go
因为是个简单的示例程序,可以很清晰地看出主要的内存分配发生在 main.bigBytes 函数中。
如果想看一些更详细的数据,可以执行list main.:
(pprof) list main.
Total: 95.38MB
ROUTINE ======================== main.bigBytes in /.../go/profiling/main.go
95.38MB 95.38MB (flat, cum) 100% of Total
. . 6: "runtime/pprof"
. . 7:)
. . 8:
. . 9:// bigBytes allocates 10 sets of 100 megabytes
. . 10:func bigBytes() *[]byte {
95.38MB 95.38MB 11: s := make([]byte, 100000000)
. . 12: return &s
. . 13:}
. . 14:
. . 15:func main() {
. . 16: for i := 0; i < 10; i++ {
ROUTINE ======================== main.main in /.../code/go/profiling/main.go
0 95.38MB (flat, cum) 100% of Total
. . 12: return &s
. . 13:}
. . 14:
. . 15:func main() {
. . 16: for i := 0; i < 10; i++ {
. 95.38MB 17: s := bigBytes()
. . 18: if s == nil {
. . 19: log.Println("oh noes")
. . 20: }
. . 21: }
. . 22:
逐行指出内存的分配情况。
通过 Web 服务器远程分析
在下面的例子中修改了代码,我们建立了一个 Web 服务,并导入 "net/http/pprof" 包 (https://golang.org/pkg/net/http/pprof/),以实现自动分析。
注意:如果你的程序已经使用了 Web 服务器,你不必再新建一个。pprof 包会挂载到 web 服务的多路复用器(multiplexer)。
package main
import (
"fmt"
"log"
"net/http"
_ "net/http/pprof"
"sync"
)
// bigBytes allocates 10 sets of 100 megabytes
func bigBytes() *[]byte {
s := make([]byte, 100000000)
return &s
}
func main() {
var wg sync.WaitGroup
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
for i := 0; i < 10; i++ {
s := bigBytes()
if s == nil {
log.Println("oh noes")
}
}
wg.Add(1)
wg.Wait() // 为了 pprof 分析的正常运行,阻止 `main` 函数退出
}
编译、运行这个程序,通过路径 /debug/pprof/ 可以访问性能分析数据,完整路径:
http://localhost:6060/debug/pprof/
你应该可以看到类似下面的内容:
profiles:
0 block
4 goroutine
5 heap
0 mutex
7 threadcreate
full goroutine stack dump
/debug/pprof/
这里的 block,goroutine,heap,mutex,threadcreate 都链接到相应的数据,这些链接对应不同的 .profile 文件。处理 .profile 文件还需要其他工具。
首先,先认识一下这五个分析文件的含义:
- block: 同步原语引起阻塞的跟踪信息;
- goroutine: 所有当前 go 协程的跟踪信息;
- heap: 堆内存分配情况;
- mutex: 竞争互斥的跟踪信息;
- threadcreate: 创建操作系统线程的跟踪信息;
web 服务器也可以产生 30s 的 CPU 性能分析文件,访问地址http://localhost:6060/debug/pprof/profile(这个文件不能在浏览器中展示,但可以下载到你的本地系统中)
在访问 /debug/pprof/ 时,看不到 CPU 性能分析的链接。因为做 CPU 性能分析需要调用特殊的 API(也就是,StartCPUProfile 和 StopCPUProfile 函数),只有调用后才产生输出流,最终下载到你的文件系统。
web 服务器可以产生“追踪”文件,访问地址http://localhost:6060/debug/pprof/trace?seconds=5(与 CPU 性能分析一样的原因,都没有列出来,调用后才产生输出数据,然后下载到你的文件系统)。这个“追踪”文件需要用 go tool trace 进行解析(后面的章节会讲解 go tool trace )。
注意:pprof 的选项信息可以参考:golang.org/pkg/net/http/pprof/
如果使用了定制的 URL 路由,你需要注册单独的 pprof 端点(endpoint):
package main
import (
"net/http"
"net/http/pprof"
)
func message(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello World"))
}
func main() {
r := http.NewServeMux()
r.HandleFunc("/", message)
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
http.ListenAndServe(":8080", r)
}
理论上,你需要在命令行使用 go tool pprof。这样以交互的方式,更容易解释和查询数据。
为了这样做,先要运行二进制文件,然后在 shell 中执行:
go tool pprof http://localhost:6060/debug/pprof/<.profile>
例如,我们要看一下堆内存分析数据:
go tool pprof http://localhost:6060/debug/pprof/heap
在这你可以看到交互提示符:
Fetching profile over HTTP from http://localhost:6060/debug/pprof/heap
Saved profile in /.../pprof.alloc_objects.alloc_space.inuse_objects.inuse_space.005.pb.gz
Type: inuse_space
Time: Oct 27, 2017 at 10:01am (BST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
注意:“type” 设定为
inuse_space(表示在用的内存数量)
你可以输入 help 或者 o 查看可用的操作,如上所示。
这里是一些有用的命令:
top: 以文本形式输出最前面的记录topK: K 代表具体数字 (例如, top2 显示前两条记录)list: 以文本形式输出记录
例如,执行 top 后,可以看到下面的输出:
Showing nodes accounting for 95.38MB, 100% of 95.38MB total
flat flat% sum% cum cum%
95.38MB 100% 100% 95.38MB 100% main.bigBytes /...ain.go (inline)
0 0% 100% 95.38MB 100% main.main /.../profiling/main.go
0 0% 100% 95.38MB 100% runtime.main /.../runtime/proc.go
对于一个简单的应用程序,可以很好指出哪个函数最耗内存(在本例中, main.bigBytes 函数分配内存最多)
如果做更精确的分析,可以用 list main.main:
Total: 95.38MB
ROUTINE ======================== main.main in /.../profiling/main.go
95.38MB 95.38MB (flat, cum) 100% of Total
. . 8: "sync"
. . 9:)
. . 10:
. . 11:// bigBytes allocates 10 sets of 100 megabytes
. . 12:func bigBytes() *[]byte {
95.38MB 95.38MB 13: s := make([]byte, 100000000)
. . 14: return &s
. . 15:}
. . 16:
. . 17:func main() {
. . 18: fmt.Println("starting...")
这样可以“逐行”指出内存使用情况。
前面有提到,堆内存分析的默认“类型”是“在用内存”。还有一种“类型”,表示程序在整个生命周期分配的内存总量,可以使用 -alloc_space 标识切换到这种模式:
go tool pprof -alloc_space http://localhost:6060/debug/pprof/heap
执行 list 命令,我们看一下区别:
(pprof) list main.bigBytes
Total: 954.63MB
ROUTINE ======================== main.bigBytes in /.../go/profiling/main.go
953.75MB 953.75MB (flat, cum) 99.91% of Total
. . 7: "sync"
. . 8:)
. . 9:
. . 10:// bigBytes allocates 10 sets of 100 megabytes
. . 11:func bigBytes() *[]byte {
953.75MB 953.75MB 12: s := make([]byte, 100000000)
. . 13: return &s
. . 14:}
. . 15:
. . 16:func main() {
. . 17: var wg sync.WaitGroup
注意:如果指明要查看“在用内存”,可以采用如下命令:
go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap
可以根据自己的需要,选择 -inuse_space 或者 -alloc_space 标签。例如,在考察垃圾回收的性能时,你需要的就是 -alloc_space。
注意:要考察生成对象的数量,可以用
-inuse_objects和-alloc_objects标签。
生成图像
要生成分析图像可以使用 -png、-gif 或 -svg 标签,重定向 stdout 到“文件”:
go tool pprof -png http://localhost:6060/debug/pprof/heap > data.png
产生类似于下面的图片(注意看方框的大小,方框越大表示消耗的资源越多,你可以马上识别出潜在的问题区域):
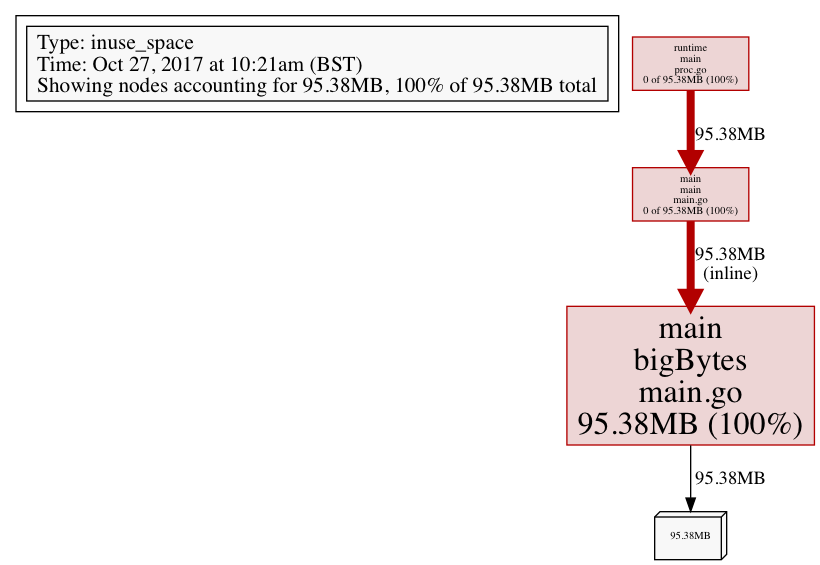
注意:可以用
Web UI 界面
不久后,pprof 分析会新增一个交互式的 web 界面(大概在 2017 年 11 月份)。
更多信息请参考这篇文章
简言之,你可以从 GitHub 获取最新的 pprof 工具,使用的时候加入 -http 标签(例如,-http=:8080)
Trace 跟踪
Trace 是一款可视化的工具,用于分析跟踪(trace)数据。它适用于分析程序在各时点的行为,而不是提供一个总体信息。
注意:如果要追查执行慢的函数或者占用 CPU 时间最多的代码,你还是要用
go tool pprof命令。
要使用 Trace ,先要对程序进行调整:
func main() {
trace.Start(os.Stdout)
defer trace.Stop()
for i := 0; i < 10; i++ {
s := bigBytes()
if s == nil {
log.Println("oh noes")
}
}
var wg sync.WaitGroup
wg.Add(1)
var result []byte
go func() {
result = make([]byte, 500000000)
log.Println("done here")
wg.Done()
}()
wg.Wait()
log.Printf("%T", result)
}
要用 trace 追踪功能,你只要导入 "runtime/trace",然后调用 trace.Start 和 trace.Stop 函数。(为了追踪程序的所有内容,在 trace.Stop 函数前加入 defer)
此外,我们创建了一个 go 协程,在其中创建了一个 500MB 的切片。等待 go 协程执行完成,然后记录 result 的类型。这样做可以看到更多的直观数据。
现在重新编译程序,用 trace 打开产生的追踪数据:
$ go build -o app
$ time ./app > app.trace
$ go tool trace app.trace
注意:使用
-pprof标签,可以生成 pprof 兼容的文件(比如要动态地检查数据时)。更多信息请参考go documentation。
这里是执行 go tool trace app.trace 的输出内容:
2017/10/29 09:30:40 Parsing trace...
2017/10/29 09:30:40 Serializing trace...
2017/10/29 09:30:40 Splitting trace...
2017/10/29 09:30:40 Opening browser
默认的浏览器会自动打开下面的地址:http://127.0.0.1:60331
注意:最好用 Chrome 浏览器,因为兼容性最好。
浏览器的页面上会有如下的链接:
- View trace
- Goroutine analysis
- Network blocking profile
- Synchronization blocking profile
- Syscall blocking profile
- Scheduler latency profile
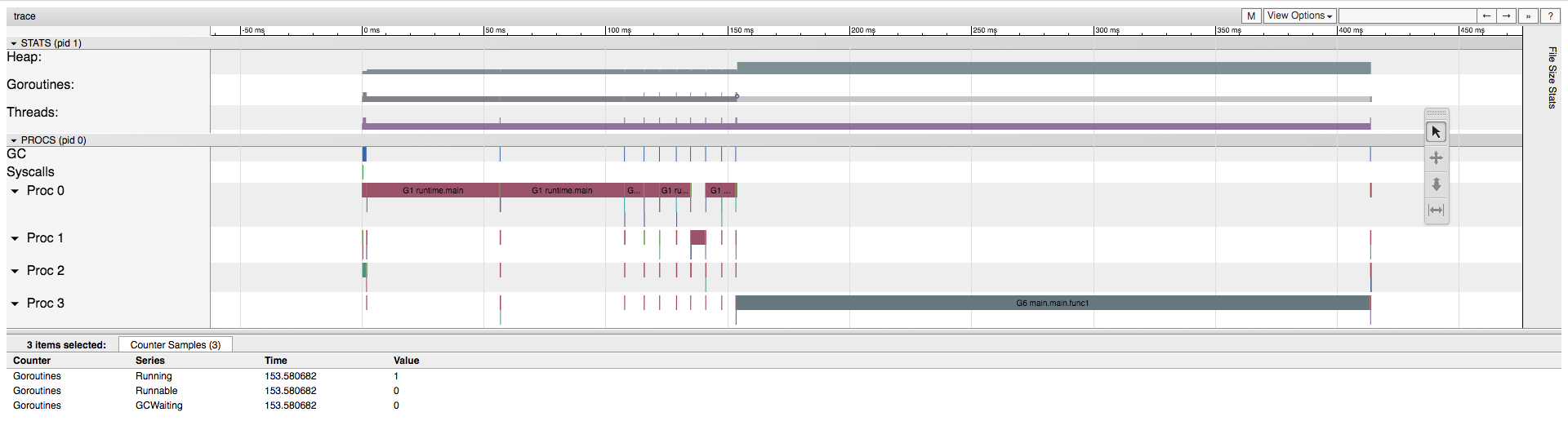
这些选项链接可以帮助我们更深入理解程序的行为,但我们最关注的是“view trace”(查看追踪信息)。 点击链接出现一个交互图形,它是应用程序行为的一个完整概览。
注意:按
出现快捷键,比如,w和s分别表示放大和缩小。
Go 协程
如果图形放大到足够大,你可以看到 “goroutines”(go 协程)这一部分,它由两种颜色构成:浅绿色(可运行 go 协程)和深绿色(正在运行的 go 协程)。如果你点击图形,在屏幕下方的预览中,可以看到样例的明细。有趣的是,在任何特定的时刻,会有多个 go 协程存在,但它们不一定同时运行。
在我们的例子中,可以看到程序的变化:从一个准备运行的 go 协程,其并没有真正运行(也就是 “runnable” 可运行状态),继续向前看到有两个 go 协程在运行。(也就是,两个都处在 “running” 运行状态,没有 go 协程处于 “runnable” 状态)
有趣的是,在图中还可以看到,运行中的 go 协程数量与底层操作系统所创建的线程数量之间的关系。
线程
同样的,放大图片你也可以看到 “threads”(线程)这一部分,它由两种颜色构成:浅紫色(syscalls 系统调用)和深紫色(running threads运行中的线程)。
在界面中 “heap” 部分有意思的内容是,因为 go 垃圾回收是并发执行,所以我们看到应用程序在堆上从未分配超过 100mb 的内存(go 垃圾回收在不同的进程/线程上运行)。程序运行中,无用的内存就被清理掉了。
这是可以理解的,因为在我们的程序中分配了 100mb 的内存给变量 s,这个变量仅在 loop 循环中有效。 一旦 loop 完成一次迭代,s 变量就不引用任何地址,所以 GC(垃圾回收)就可以清理掉这块内存。
堆
随着程序继续运行,我们最终会看到一些有冲突的地方,整体的内存分配会变成 200mb ,然后反复在 100mb 和 200mb 之间变化(因为 GC 并不是一直在运行)。当运行到程序的结尾时,我们看到 500mb 的分配尖峰,整体内存分配量达到 600mb 。
但是在这一点时,如果点击堆内存尖峰,在下方的预览窗口,我们可以看到 “NextGC” 在运行,表明全部内存分配会被清零(因为已经运行到程序的结尾了)。
进程
在界面中 “procs” 部分,可以看到,在分配 500mb 内存时,Proc 3(进程 3)上有一个新的 go 协程在运行 main.main.func1 函数(在我们的程序中,这个函数负责内存分配工作)
如果在 “View Options”(查看选项)中选择 “Flow events”(流事件),你可以看到一个箭头从 main.main 函数指向 main.main.func1 函数,main.main.func1 是运行在一个独立的进程/线程上。(箭头不容易看到,但确实有)
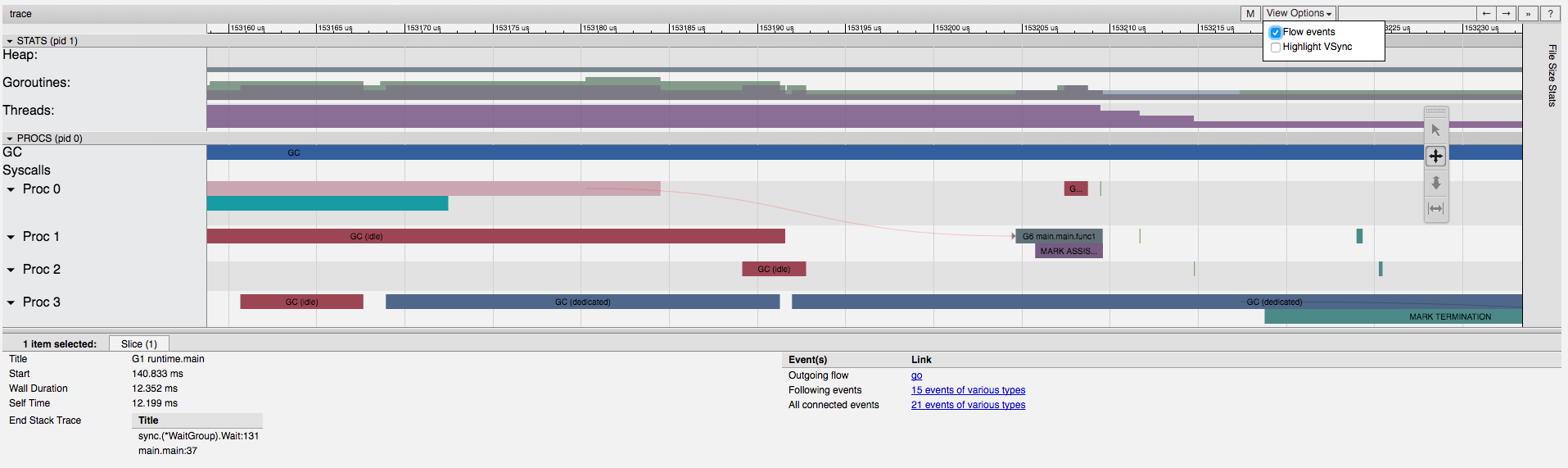
通过图形界面,不但可直观的见到 main.main.func1 协程运行与内存分配的对应关系,而且能够看到程序的因果关系(也就是,什么 触发了新的 go 协程的运行)
结尾
在这个过程中,我们体验了各种各样的 Go 代码调优工具。更多信息可以参考我以前的文章,关于 Python 性能调优的内容。
via: http://www.integralist.co.uk/posts/profiling-go/
作者:Mark McDonnell 译者:pbix2020 校对:rxcai polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





赞👍
写的很好,赞一个!