
序言
我是 Prometheus 和 Grafana 的忠实粉丝。作为一个前 Google 公司 SRE, 我一直以来都知道良好的监控的重要性, Prometheus 和 Grafana 的组合是我多年的最爱。我用他们来监控我的个人服务器(黑盒和白盒都有), Euskal Encounter 内外部事件以及我服务的专业客户。Prometheusa 让编写定制的数据导出器变得非常简单, 而且你能够找到很多现成的满足你要求的导出器。比如说,我们使用 sql_exporter 来为 Encounter 会议的与会者数据做了一个监控面板。
既然我们能够很容易地把 node_exporter 部署到任意的机器上并且用 Prometheus 实例去读取机器的基础数据维度(CPU,内存,网络,磁盘,文件系统使用等), 那我为什么不同时监控我的笔记本呢?我有一个蓝天"游戏"本充当我的主工作站,主要在家里被当做台式机使用,同时也会被我带去参加一个大型活动比如 Chaos Communication Congress。由于我已经在这台笔记本和一台部署了 Prometheus 的服务器之间有一个 VPN 通道了,我可以使用 emerge prometheus-node_exporter 命令来启动服务,让我的 Prometheus 实例指向这个服务。这个命令会为这台笔记本自动设置警报,每当我打开了太多 Chrome 页面用完了 32G 内存的时候,我的手机就会发出很大的声音来提醒我。完美!
问题浮现
这一切看起来很完美,但是,在我完成这些设置后仅仅一小时,我的手机接收到一条信息: 我新添加的目标不可访问。但是,我能够通过 SSH 连到我的笔记本,所以它肯定是启动了的,只是 node_exporter 崩溃了。
fatal error: unexpected signal during runtime execution
[signal SIGSEGV: segmentation violation code=0x1 addr=0xc41ffc7fff pc=0x41439e]
goroutine 2395 [running]:
runtime.throw(0xae6fb8, 0x2a)
/usr/lib64/go/src/runtime/panic.go:605 +0x95 fp=0xc4203e8be8 sp=0xc4203e8bc8 pc=0x42c815
runtime.sigpanic()
/usr/lib64/go/src/runtime/signal_unix.go:351 +0x2b8 fp=0xc4203e8c38 sp=0xc4203e8be8 pc=0x443318
runtime.heapBitsSetType(0xc4204b6fc0, 0x30, 0x30, 0xc420304058)
/usr/lib64/go/src/runtime/mbitmap.go:1224 +0x26e fp=0xc4203e8c90 sp=0xc4203e8c38 pc=0x41439e
runtime.mallocgc(0x30, 0xc420304058, 0x1, 0x1)
/usr/lib64/go/src/runtime/malloc.go:741 +0x546 fp=0xc4203e8d38 sp=0xc4203e8c90 pc=0x411876
runtime.newobject(0xa717e0, 0xc42032f430)
/usr/lib64/go/src/runtime/malloc.go:840 +0x38 fp=0xc4203e8d68 sp=0xc4203e8d38 pc=0x411d68
github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus.NewConstMetric(0xc42018e460, 0x2, 0x3ff0000000000000, 0xc42032f430, 0x1, 0x1, 0x10, 0x9f9dc0, 0x8a0601, 0xc42032f430)
/var/tmp/portage/net-analyzer/prometheus-node_exporter-0.15.0/work/prometheus-node_exporter-0.15.0/src/github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus/value.go:165 +0xd0 fp=0xc4203e8dd0 sp=0xc4203e8d68 pc=0x77a980
和很多 Prometheus 组件一样, node_exporter 是用 Go 语言写的。 Go 是一个相对安全的语言:尽管如果你愿意的话,你可以用它来“射自己的脚”, 它也没有像 Rust 那样强大的安全性保证,但是要想用 Go 语言写出一个段错误来仍然不容易。更不用提, node_exporter 是一个相对简单的 Go 应用, 只用到了纯 Go 的依赖。因此, 这是一个很罕见的崩溃。 尤其是这次崩溃是在 mallocgc 中发生的,这也是在正常情况下不会发生的。
当我重启 node_exporter 几次之后,更有趣的事情发生了:
2017/11/07 06:32:49 http: panic serving 172.20.0.1:38504: runtime error: growslice: cap out of range
goroutine 41 [running]:
net/http.(*conn).serve.func1(0xc4201cdd60)
/usr/lib64/go/src/net/http/server.go:1697 +0xd0
panic(0xa24f20, 0xb41190)
/usr/lib64/go/src/runtime/panic.go:491 +0x283
fmt.(*buffer).WriteString(...)
/usr/lib64/go/src/fmt/print.go:82
fmt.(*fmt).padString(0xc42053a040, 0xc4204e6800, 0xc4204e6850)
/usr/lib64/go/src/fmt/format.go:110 +0x110
fmt.(*fmt).fmt_s(0xc42053a040, 0xc4204e6800, 0xc4204e6850)
/usr/lib64/go/src/fmt/format.go:328 +0x61
fmt.(*pp).fmtString(0xc42053a000, 0xc4204e6800, 0xc4204e6850, 0xc400000073)
/usr/lib64/go/src/fmt/print.go:433 +0x197
fmt.(*pp).printArg(0xc42053a000, 0x9f4700, 0xc42041c290, 0x73)
/usr/lib64/go/src/fmt/print.go:664 +0x7b5
fmt.(*pp).doPrintf(0xc42053a000, 0xae7c2d, 0x2c, 0xc420475670, 0x2, 0x2)
/usr/lib64/go/src/fmt/print.go:996 +0x15a
fmt.Sprintf(0xae7c2d, 0x2c, 0xc420475670, 0x2, 0x2, 0x10, 0x9f4700)
/usr/lib64/go/src/fmt/print.go:196 +0x66
fmt.Errorf(0xae7c2d, 0x2c, 0xc420475670, 0x2, 0x2, 0xc420410301, 0xc420410300)
/usr/lib64/go/src/fmt/print.go:205 +0x5a
发生在 Sprintf 中的崩溃,这就更神奇了。
runtime: pointer 0xc4203e2fb0 to unallocated span idx=0x1f1 span.base()=0xc4203dc000 span.limit=0xc4203e6000 span.state=3
runtime: found in object at *(0xc420382a80+0x80)
object=0xc420382a80 k=0x62101c1 s.base()=0xc420382000 s.limit=0xc420383f80 s.spanclass=42 s.elemsize=384 s.state=_MSpanInUse
<snip>
fatal error: found bad pointer in Go heap (incorrect use of unsafe or cgo?)
runtime stack:
runtime.throw(0xaee4fe, 0x3e)
/usr/lib64/go/src/runtime/panic.go:605 +0x95 fp=0x7f0f19ffab90 sp=0x7f0f19ffab70 pc=0x42c815
runtime.heapBitsForObject(0xc4203e2fb0, 0xc420382a80, 0x80, 0xc41ffd8a33, 0xc400000000, 0x7f0f400ac560, 0xc420031260, 0x11)
/usr/lib64/go/src/runtime/mbitmap.go:425 +0x489 fp=0x7f0f19ffabe8 sp=0x7f0f19ffab90 pc=0x4137c9
runtime.scanobject(0xc420382a80, 0xc420031260)
/usr/lib64/go/src/runtime/mgcmark.go:1187 +0x25d fp=0x7f0f19ffac90 sp=0x7f0f19ffabe8 pc=0x41ebed
runtime.gcDrain(0xc420031260, 0x5)
/usr/lib64/go/src/runtime/mgcmark.go:943 +0x1ea fp=0x7f0f19fface0 sp=0x7f0f19ffac90 pc=0x41e42a
runtime.gcBgMarkWorker.func2()
/usr/lib64/go/src/runtime/mgc.go:1773 +0x80 fp=0x7f0f19ffad20 sp=0x7f0f19fface0 pc=0x4580b0
runtime.systemstack(0xc420436ab8)
/usr/lib64/go/src/runtime/asm_amd64.s:344 +0x79 fp=0x7f0f19ffad28 sp=0x7f0f19ffad20 pc=0x45a469
runtime.mstart()
/usr/lib64/go/src/runtime/proc.go:1125 fp=0x7f0f19ffad30 sp=0x7f0f19ffad28 pc=0x430fe0
这次是 GC 出现了崩溃,又是一个新的问题。
通常在这时,有两个常见的可能:要么我的笔记本出现了一个严重的硬件问题,要么可执行文件中有严重的内存泄露。刚开始时我认为前者可能性不大因为这台笔记本承载了很大的工作量但是之前并没有出现看起来像是硬件问题的 bug(它曾经出现过软件问题,但是绝不会是随机的)。由于 node_exporter 这样的 Go 二进制文件是静态链接的且不依赖于其他库,我可以下载官方发布的二进制版本来尝试一下,这可以用来判断是否是我的系统出现了问题。结果是,我替换二进制文件后,仍然出现了崩溃情况。
unexpected fault address 0x0
fatal error: fault
[signal SIGSEGV: segmentation violation code=0x80 addr=0x0 pc=0x76b998]
goroutine 13 [running]:
runtime.throw(0xabfb11, 0x5)
/usr/local/go/src/runtime/panic.go:605 +0x95 fp=0xc420060c40 sp=0xc420060c20 pc=0x42c725
runtime.sigpanic()
/usr/local/go/src/runtime/signal_unix.go:374 +0x227 fp=0xc420060c90 sp=0xc420060c40 pc=0x443197
github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_model/go.(*LabelPair).GetName(...)
/go/src/github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_model/go/metrics.pb.go:85
github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus.(*Desc).String(0xc4203ae010, 0xaea9d0, 0xc42045c000)
/go/src/github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus/desc.go:179 +0xc8 fp=0xc420060dc8 sp=0xc420060c90 pc=0x76b998
又是一个完全不同的崩溃。这时我认为 node_exporter 或者它的依赖出问题的可能性变大了,因此我在 Github 上提了一个 issue。也许开发者以前见过这个情况?无论如何,问一下他们是否有解决方案是没错的。
不简短的硬件排查
不出所料, 开发者首先想到的是硬件问题。这是合理的,毕竟我只在一台机器上碰到这个问题。我的所有其他机器上的 node_exporter 都运行得很好。尽管我没有任何有关硬件不稳定的证据,我也没有任何关于为什么 node_exporter 会只在那台机器上崩溃的解释。我尝试使用 Memtest86+ 看一下内存使用情况,出现了下面的情况:
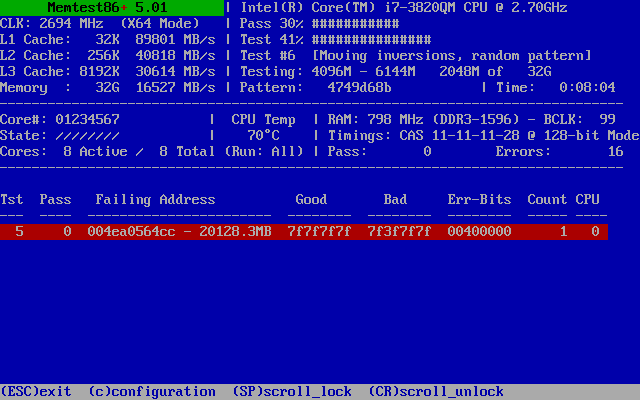
损坏的内存!更具体的说,一比特损坏的内存。完整地跑了一遍测试之后,我只发现了这一个坏掉的比特,和一些误报的内存损坏。
之后的测试显示 Memtest86+ test #5 在 SMP 模式下能够快速地发现这个错误,但通常不是第一次就能测出。出错的永远是相同的比特。这提醒我们问题在于一个内存单元的损坏。具体来说,是一个和天气一起变坏的内存比特。这听上去是很合理的:高温导致了内存单元的泄露,也因此让一个比特翻转更有可能发生。
总结来说,274,877,906,944 比特中的一个坏掉了。这算起来其实是一个很优秀的出错率。硬盘和闪存的出错率可比这个数字要高多了 - 只不过这些设备把损坏的存储块做了标记并且在用户不知情的情况下就废弃了这些存储块,它们还可以把新发现的弱存储块标记为坏的且将它们重定向到一个空的区块。然而,内存受限于容量,不会做这么奢侈的操作,所以一个坏掉的比特会一直留在那。
但是,这不可能是我的 node_exporter 崩溃的原因。 它使用很少的内存,所以它使用到这个坏掉的比特的概率很小。这种问题在大多数情况下是可以忽略的,也许会导致图像上一个像素显示错误,一段文字中的某一个字母错误,一个大概率不会执行的指令的崩溃,但是如果程序中重要的内容恰好使用到了这个比特,它就会导致不常见的段错误发生。总结来说,内存上的存储单元损坏确实会引起长期的可靠性问题,这也是一些要求高可靠性的服务器和设备必须要使用 ECC RAM 来纠正这类型的错误。
我不能奢侈到在笔记本上使用 ECC RAM。但是我可以把这个它损坏的内存块标记成坏的并且让操作系统不要再使用它。这是 GRUB 2 一个比较隐蔽的功能,可以允许你修改当前运行的内核的内存映射表。 为了一个坏掉的比特重新买一个内存是不值得的(尤其是 DDR3 已经快过时了,更不用说新买的内存很可能也会出现同样的问题),因此上述方案是一个不错的选择。
但是,我还可以做另外一件事。既然这个问题会因为温度变高而更严重。那如果我加热内存的话会发生什么呢?


我用一个温度为 130℃ 的加热枪同时加热了两个内存模块(我的笔记本一共有四个 SODIMM 插槽,另外两个在背壳后面)。我按照模块顺序来检查,陆续发现了另外三个只能在高温环境下才能检测到的坏比特,它们分布在三个笔记本的三个内存条上。
我还发现这些错误的地址很一致,即使在我交换这些模块之后。地址的高位比特都是相同的。这是因为内存是交错的,数据会分布在四个内存条上。这很方便,因为我可以把所有可能出错的内存比特地址都划到一个范围内,不用担心我可能在将来交换内存条搞错了掩码。我发现划掉一个相邻的 128KiB 区域就可以覆盖所有已知的损坏比特,为了保险,我最后划掉了相邻的 1MiB。所以我把三个 1MiB 对齐的内存块标记为坏内存块(其中一个包含了两个坏比特,加起来共有四个):
- 0x36a700000 – 0x36a7fffff
- 0x460e00000 – 0x460efffff
- 0x4ea000000 – 0x4ea0fffff
这个功能可以通过使用 GRUB 的 address/mask 语法来实现:
GRUB_BADRAM="0x36a700000,0xfffffffffff00000,0x460e00000,0xfffffffffff00000,0x4ea000000,0xfffffffffff00000"
然后会用 grub-mkconfig 命令,我就少了 3MiB 的内存和四个坏掉的比特。这不是 ECC RAM, 但是这也能提高我的民用级别内存的可靠性,因为我知道了剩下的内存至少在一百度的时候不会出问题。
当然,node_exporter 仍然会崩溃,我们也明白这不是真正的问题所在。
深度挖掘
这类 bug 最让人恼火的就是,我们可以肯定它是某一部分内存损坏导致的。这让它很难被调试,因为我们无法预测哪部分代码会遇上这个问题,所以我们无法直接定位到问题根源。
首先我对可以找到的 node_exporter 版本做了一个基本的二分排查,分别启动/关闭不同的收集器,但是这并没有凑效。我还试了在 strace 下运行一个实例。这看起来解决了崩溃的问题,但是它又引发了一个条件竞争的问题。strace 通常会通过拦截所有线程上的的系统调用在一定程度上包装应用的序列执行。我之后同样发现了 strace 也崩溃了,但是这花了很长时间。因为这看起来像是一个多线程的问题,我尝试着设置 GOMAXPROCS=1, 这会让 Go 单线程地执行程序代码。这同样解决了崩溃的问题,所以这又暗示了这是一个多线程的问题。
现在为止,我已经收集了相当多的崩溃日志,我也从中发现了一些规律。尽管每次发生的崩溃的地点和原因都不一样,但是最终这些错误信息都可以被分类到不同类型中去并且其中一些错误出现了不止一次。所以我开始在网上搜索这些错误,然后我就发现了 Go issue #20427。这是一个在 Go 语言中看起来无关的部分的问题,但是引起了相同的段错误和随机的崩溃。这个 issue 在 Go 1.9 上无法重现,被关闭了。没有人知道引起这个 issue 的根本原因是什么。
我从那个 issue 中下载了 重现代码 在我的电脑上运行。果然,它很快就崩溃了,我们有了一个很快的重现方法。
但是这并没有能够帮我从 Go 语言中找到解决这个问题的方法,只是给了我们一个更快的重现方式。我们现在尝试换一个角度。
二分机器调试
我知道这个问题会发生在我的笔记本上,但是不会发生在我的其他机器上。我试着在所有机器上跑上文中下载的重现代码,也没有重现崩溃的错误。这告诉我是笔记本上的特殊环境导致了这个错误。因为 Go 静态链接二进制文件,所以用户空间不会导致什么问题。我们就能把范围缩小到以下两个方面:硬件和内核。
我没有条件在不同的硬件上测试我的代码,但是我可以把关注点放在内核上。首先我们想知道的是:node_exporter 是否会在虚拟机上崩溃呢?
为了测试这个情况,我安装了一个精简版的文件系统来在 QEMU 虚拟机上运行我的重现代码。我的文件系统是用 Linux 的 scripts/gen_initramfs_list.sh,它包含了下面的文件:
dir /dev 755 0 0
nod /dev/console 0600 0 0 c 5 1
nod /dev/null 0666 0 0 c 1 3
dir /bin 755 0 0
file /bin/busybox busybox 755 0 0
slink /bin/sh busybox 755 0 0
slink /bin/true busybox 755 0 0
file /init init.sh 755 0 0
file /reproducer reproducer 755 0 0
/init 是 Linux 文件系统的入口。在我的文件系统中,它就是一个简单的 shell 脚本来启动测试和计算时间:
#!/bin/sh
export PATH=/bin
start=$(busybox date +%s)
echo "Starting test now..."
/reproducer
ret=$?
end=$(busybox date +%s)
echo "Test exited with status $ret after $((end-start)) seconds"
/bin/busybox 是 BusyBox 的静态链接版本,经常被用在我们这样的精简系统中来提供基本的 Linux shell 工具。
这个文件系统可以使用下面的命令编译运行:
scripts/gen_initramfs_list.sh -o initramfs.gz list.txt
然后 QEMU 可以直接启动内核和文件系统:
qemu-system-x86_64 -kernel /boot/vmlinuz-4.13.9-gentoo -initrd initramfs.gz -append 'console=ttyS0' -smp 8 -nographic -serial mon:stdio -cpu host -enable-kvm
执行以后发现 console 上面没有输出。然后我意识到我根本没有把 8250 串端口支持编译进我笔记本的内核。虚拟机没有物理串端口,所以我重新变异了带串端口支持的内核,这次我终于可以运行我的重现代码了。
它崩溃了吗?是的,这意味着这个问题在我的笔记本的虚拟机上也能运行。我试着在我的另外一台机器上运行同样内核的虚拟机并且运行重现代码,崩溃又发生了。这表明,这是一个内核问题,而不是一个硬件问题。
内核调试
这时,我知道我将要编译很多内核来尝试找出问题根源了。所以,我换了一台性能更好的电脑:一台古老的 12 核,24 线程的 XEON。我把已知会发生崩溃的内核代码放到那台机器上编译并且运行,但是它并没有发生崩溃。
经过一些思考之后,我确认最早的二进制版本会崩溃。所以这是一个硬件问题?我编译的机器会不会对结果产生影响?我试着在我的家庭服务器上编译这个内核,这个内核很快就发生了重现代码崩溃。在两台机器上编译相同的内核导致了崩溃,在第三台机器上却没有。它们有什么区别?
这三台机器都使用了 Gentoo 发行版。但我的笔记本和家庭服务器使用的是 amd64(unstable), 而我的 Xeon 服务器是 amd64(stable) 的。这意味着它们的 GCC 是不同的。我的笔记本和家庭服务器用的是 gcc (Gentoo Hardened 6.4.0 p1.0) 6.4.0,而我的 Xeon 服务器用的是 gcc (Gentoo Hardened 5.4.0-r3 p1.3, pie-0.6.5) 5.4.0。
但是我的家庭服务器的内核(和我的笔记本的内核基本相同),是使用同一个版本的 GCC 编译的而且并没有重现崩溃。所以我只能猜测用来编译内核的编译器和内核(或者配置)本身都是影响是否能重现这个崩溃的变量因素。
为了进一步缩小范围,我在我的家庭服务器上编译了和我的笔记本一样的内核,这个内核确实会发生崩溃。接着我从我的家庭服务器上拷贝了 .config 文件重新编译了这个内核,发现这次并不能重现崩溃。这意味着我们可以把范围缩小到内核配置差异和编译器差异:
- linux-4.13.9-gentoo + gcc 5.4.0-r3 p1.3 + laptop .config - no crash
- linux-4.13.9-gentoo + gcc 6.4.0 p1.0 + laptop .config - crash
- linux-4.13.9-gentoo + gcc 6.4.0 p1.0 + server .config - no crash
两个 .config 文件,一个好,一个坏。是时候看它们的区别了。当然,这两个文件差别很大(因为我修改过配置文件让它仅仅包含我所必须的驱动),所以我只能不停地重新编译内核来尝试定位问题。
我决定从确定有问题的 .config 文件入手删除一些不必要的配置。因为我们能很快地重现崩溃,所以比起“不会崩溃”,我们能更快地确认“仍然会崩溃”。经过 22 次内核编译之后,我成功地把配置文件简化到让内核不支持网络,文件系统,块设备内核甚至是 PCI(仍然能在虚拟机中成功运行)。我的内核现在编译只需要不到 60 秒并且大小只有正常大小的四分之一。
然后我又回到了已知是好的 .config 文件上来,在确保它不会引发重现代码崩溃的情况下删除了一些不必要的模块。我曾有一些错误的尝试,让重现代码重现了崩溃,但我错误地认定它们不会崩溃,所以当我发现了崩溃以后我不得不回溯到之前的内核重新确认哪些修改引入了崩溃。我最终通过 7 次内核编译完成了这件事。
最终,我将问题定位到了几个 .config 文件中的选项上。其中一个 CONFIG_OPTIMIZE_INLINING 引起了我的注意。经过仔细的测试之后我发现,这个选项就是元凶。把它关掉就会编译出会使重现代码崩溃的内核,而把它打开就不会。选项在打开时,会允许 GCC 更好地决定哪个内联函数确实必须被内联,而不是强制将所有的内联函数内联。这也解释了它和 GCC 版本的关联:内联行为很可能会根据版本而改变。
/*
* Force always-inline if the user requests it so via the .config,
* or if gcc is too old.
* GCC does not warn about unused static inline functions for
* -Wunused-function. This turns out to avoid the need for complex #ifdef
* directives. Suppress the warning in clang as well by using "unused"
* function attribute, which is redundant but not harmful for gcc.
*/
#if !defined(CONFIG_ARCH_SUPPORTS_OPTIMIZED_INLINING) || \
!defined(CONFIG_OPTIMIZE_INLINING) || (__GNUC__ < 4)
#define inline inline __attribute__((always_inline,unused)) notrace
#define __inline__ __inline__ __attribute__((always_inline,unused)) notrace
#define __inline __inline __attribute__((always_inline,unused)) notrace
#else
/* A lot of inline functions can cause havoc with function tracing */
#define inline inline __attribute__((unused)) notrace
#define __inline__ __inline__ __attribute__((unused)) notrace
#define __inline __inline __attribute__((unused)) notrace
#endif
那么接下来呢?我们知道 CONFIG_OPTIMIZE_INLINING 会引发问题,但是这个选项会改变内核中所有的内联函数的行为。如何才能精确定位问题所在呢?
Hash-based 差异编译
现在我们要把内核分开,一部分在打开 CONFIG_OPTIMIZE_INLINING 选项时编译,另一部分在这个选项关闭的时候编译。 通过测试编译完的内核是否会崩溃,我们可以进一步缩小可能出错的 object 文件的范围。
为了避免遍历所有的 object 文件并且做一些二分查找,我决定使用一个基于哈希的算法。我用这个算法写了一个脚本:
#!/bin/bash
args=("$@")
doit=
while [ $# -gt 0 ]; do
case "$1" in
-c)
doit=1
;;
-o)
shift
objfile="$1"
;;
esac
shift
done
extra=
if [ ! -z "$doit" ]; then
sha="$(echo -n "$objfile" | sha1sum - | cut -d" " -f1)"
echo "${sha:0:8} $objfile" >> objs.txt
if [ $((0x${sha:0:8} & (0x80000000 >> $BIT))) = 0 ]; then
echo "[n]" "$objfile" 1>&2
else
extra=-DCONFIG_OPTIMIZE_INLINING
echo "[y]" "$objfile" 1>&2
fi
fi
exec gcc $extra "${args[@]}"
这个脚本使用 SHA-1 算法计算每个 object 文件的哈希值,然后在前 32 位比特中任取一位,如果这个比特是 0, 就关闭 CONFIG_OPTIMIZE_INLINING 来编译。如果这个比特是 1,就打开CONFIG_OPTIMIZE_INLINING 来编译。我观察到现在的内核大概有 685 个 object 文件(我之前的最小化内核工作取得了成效),这写文件可能需要十个比特位来编号。这个方法还有一个好处是:我只需要关注会崩溃的内核,这可比证明一个内核不会崩溃简单多了。
我以 SHA-1 哈希串前缀中的每一个比特位为标志位,花29分钟编译了 32 个内核。然后我开始测试他们是否会崩溃,每次我测试出一个会崩溃的内核,我就用一个正则表达式来表达可能的 SHA-1 值(在指定位数是 0 的值)。经过八次崩溃之后,我已经能锁定到 4 个 object 文件了。当我测试到第十次崩溃时,就只有一个匹配的 object 文件了。
$ grep '^[0246][012389ab][0189][014589cd][028a][012389ab][014589cd]' objs_0.txt
6b9cab4f arch/x86/entry/vdso/vclock_gettime.o
vDSO
这个内核的 vDSO 并不是真正的内核代码。它是内核放在每个进程地址空间的小共享库,能够允许应用在不离开用户态的情况下进行一些系统调用。这样做不仅能显著地提高性能,还可以允许内核在需要时改变一些系统调用的实现。
换句话说, vDSO 是 GCC 在编译内核时编译的代码,和所有的用户态应用链接,是用户态的代码。这解释了为什么内核和内核的编译器会影响这个 bug:因为根源是一个内核提供的共享库,而不是内核本身。Go 出于性能考虑使用了 vDSO 库。Go 恰好还有一个重写标准库的策略,所以它不会用任何 Linux 官方的 glibc 代码来调用 vDSO,而是会使用自己的代码。
所以开关 CONFIG_OPTIMIZE_INLINING 这个选项到底会对 vDSO 造成什么影响呢?让我们来看看它的汇编代码。
在 CONFIG_OPTIMIZE_INLINING=n 的情况下:
arch/x86/entry/vdso/vclock_gettime.o.no_inline_opt: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <vread_tsc>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 90 nop
5: 90 nop
6: 90 nop
7: 0f 31 rdtsc
9: 48 c1 e2 20 shl $0x20,%rdx
d: 48 09 d0 or %rdx,%rax
10: 48 8b 15 00 00 00 00 mov 0x0(%rip),%rdx # 17 <vread_tsc+0x17>
17: 48 39 c2 cmp %rax,%rdx
1a: 77 02 ja 1e <vread_tsc+0x1e>
1c: 5d pop %rbp
1d: c3 retq
1e: 48 89 d0 mov %rdx,%rax
21: 5d pop %rbp
22: c3 retq
23: 0f 1f 00 nopl (%rax)
26: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
2d: 00 00 00
0000000000000030 <__vdso_clock_gettime>:
30: 55 push %rbp
31: 48 89 e5 mov %rsp,%rbp
34: 48 81 ec 20 10 00 00 sub $0x1020,%rsp
3b: 48 83 0c 24 00 orq $0x0,(%rsp)
40: 48 81 c4 20 10 00 00 add $0x1020,%rsp
47: 4c 8d 0d 00 00 00 00 lea 0x0(%rip),%r9 # 4e <__vdso_clock_gettime+0x1e>
4e: 83 ff 01 cmp $0x1,%edi
51: 74 66 je b9 <__vdso_clock_gettime+0x89>
53: 0f 8e dc 00 00 00 jle 135 <__vdso_clock_gettime+0x105>
59: 83 ff 05 cmp $0x5,%edi
5c: 74 34 je 92 <__vdso_clock_gettime+0x62>
5e: 83 ff 06 cmp $0x6,%edi
61: 0f 85 c2 00 00 00 jne 129 <__vdso_clock_gettime+0xf9>
[...]
在 CONFIG_OPTIMIZE_INLINING=y 的情况下:
arch/x86/entry/vdso/vclock_gettime.o.inline_opt: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <__vdso_clock_gettime>:
0: 55 push %rbp
1: 4c 8d 0d 00 00 00 00 lea 0x0(%rip),%r9 # 8 <__vdso_clock_gettime+0x8>
8: 83 ff 01 cmp $0x1,%edi
b: 48 89 e5 mov %rsp,%rbp
e: 74 66 je 76 <__vdso_clock_gettime+0x76>
10: 0f 8e dc 00 00 00 jle f2 <__vdso_clock_gettime+0xf2>
16: 83 ff 05 cmp $0x5,%edi
19: 74 34 je 4f <__vdso_clock_gettime+0x4f>
1b: 83 ff 06 cmp $0x6,%edi
1e: 0f 85 c2 00 00 00 jne e6 <__vdso_clock_gettime+0xe6>
[...]
Interestingly, CONFIG_OPTIMIZE_INLINING=y, which is supposed to allow GCC to inline less, actually resulted in it inlining more: vread_tsc is inlined in that version, while not in the CONFIG_OPTIMIZE_INLINING=n version. But vread_tsc isn’t marked inline at all, so GCC is perfectly within its right to behave like this, as counterintuitive as it may be.
But who cares if a function is inlined? Where’s the actual problem? Well, looking closer at the non-inline version…
30: 55 push %rbp
31: 48 89 e5 mov %rsp,%rbp
34: 48 81 ec 20 10 00 00 sub $0x1020,%rsp
3b: 48 83 0c 24 00 orq $0x0,(%rsp)
40: 48 81 c4 20 10 00 00 add $0x1020,%rsp
有趣的是,当 CONFIG_OPTIMIZE_INLINING=y 时,应该是允许 GCC 内联更少的代码,但是实际上却导致 GCC 内联了更多的代码:vread_tsc 在这时候被内联,但是在 CONFIG_OPTIMIZE_INLINING=y 时候并没有被内联。更有趣的是,vread_tsc 在代码中根本没有被标记为内联,所以 GCC 做了一个很奇怪的操作。
但是谁会介意一个函数是否被内联呢?真正的问题在哪里?让我们再仔细看看无内联的版本:
30: 55 push %rbp
31: 48 89 e5 mov %rsp,%rbp
34: 48 81 ec 20 10 00 00 sub $0x1020,%rsp
3b: 48 83 0c 24 00 orq $0x0,(%rsp)
40: 48 81 c4 20 10 00 00 add $0x1020,%rsp
为什么 GCC 会分配超过 4KiB 的栈呢?这不是一个栈空间分配,这是一个栈空间嗅探,或者具体的说是 GCC 的功能 -fstack-check 的结果。
Gentoo Linux 默认打开了 -fstack-check 这个选项。这是针对 Stack Clash 问题的一个解决方案。但是 -fstack-check 是 GCC 的一个老功能,而且初衷并不是来做这个,只是恰巧它能有效缓解 Stack Clash 问题。但是这个选项有一个副作用,它会导致一些很愚蠢的行为,比如说每个非叶节点函数(有函数调用的的函数)会根据栈指针向前嗅探 4 KiB。换句话说,-fstack-check 打开时编译的代码,如果不是叶节点函数的话,至少需要 4KiB 的栈空间(或者是一个所有函数调用都被内联的函数)。
但是 Go 大量使用了空间很小的栈。
TEXT runtime·walltime(SB),NOSPLIT,$16
// Be careful. We're calling a function with gcc calling convention here.
// We're guaranteed 128 bytes on entry, and we've taken 16, and the
// call uses another 8.
// That leaves 104 for the gettime code to use. Hope that's enough!
看起来 104 字节对我的内核来说并不够大。
值得注意的是, vDSO 文档中并没有指明最大栈空间的保证,所以这很明显是 Go 做了一个错误的假设。
结论
我们的发现完美地解释了所有的现象。栈嗅探是一个 orq 指令(与 0 的逻辑或)。这是一个空指令, 但是能够有效地嗅探到目标地址(如果地址不存在,就会出现段错误)。但是我们并没有在 vDSO 代码中看到段错误,所以为什么它会导致 Go 程序崩溃呢?原因是,与 0 的逻辑与并不真的是一个空指令。因为 orq 不是一个原子操作。所以真实情况是 CPU 读了内存地址又把它写了回来。这导致了一个竞争的状况。如果有其他线程在其他核上运行,orq 可能会撤销一次同时发生的内存写操作。因为这个写操作超出了栈的边界,它可能是写在了其他线程的栈上或者是随机数据上,然后又撤销了一次写操作。这也是为什么 GOMAXPROCS=1 的时候不会发生崩溃,在这种情况下不会有同时运行的 Go 语言代码。
那怎么修复这个问题呢?我把它留给了 Go 的开发者。他们最终的解决方案是在调用 vDSO 函数时 分配更大的栈空间。这会导致一个细微的纳秒级的速度损失,但这是可接受的。在用修复过的 Go 编译 node_exporter 之后,一切恢复了正常。
via: https://marcan.st/2017/12/debugging-an-evil-go-runtime-bug/
作者:Hector Martin 译者:QueShengyao 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




大坑啊
根本看不懂,唉〜〜〜〜
这样的一查到底的精神,非常值得我们学习。。给作者和译者一个大大的赞。
瑟瑟发抖
瑟瑟发抖看不懂
读起来怎么感觉像是翻译的国外的文章,而不是原创的内容
最后不是写着吗?原作者、翻译人、校对者
我在使用了go1.11.10的版本后,依然存在该问题。 最早使用的早期版本反而没有该问题,但是早期版本不能使用一些新特性。 查看了一些资料,有人建议升级Linux内核版本,目前内核版本为3.16.0,该问题未能避免。 虽然本文作者探索精神令人折服,但是并没有有效的解决方式。 期待大神提供解决方法。