
介绍
在过去的几个月里,我在几个项目上使用过 Go,尽管我还算不上专家,但是还是有几件事我要感谢 Go:首先,它有一个清晰而简单的语法,我不止一次注意到 Github 开发人员的风格非常接近于旧 C 程序中使用的风格,从理论上讲,Go 似乎吸收了世界上所有语言最好的特性:它有着高级语言的力量,明确的规则使得更简单,即使这些特性有时有一点点的约束力--就是可以给代码强加一个坚实的逻辑。这是命令式的简单,由大小以位为单位的原始类型组成。但是没有像把字符串当成字符数组那样操作的乏味。然而,我认为这两个非常有用和有趣的功能是 goroutine 和 channels。

前言
为了理解 Go 为什么能更好地处理并发性,首先需要知道什么是并发性 1。并发性是独立执行计算的组成部分:是一种更好地编写与现实世界进行良好交互的干净的代码的方法。通常,即使并发不等同于并行,人们也会将并发的概念与并行的概念混淆:是,尽管它能够实现并行性。所以,如果你只有一个处理器,你的程序仍然可以并发,但不能并行。另一方面,良好的并发程序可以在多处理器上并行运行 2。这一特性是非常重要的。让我们来谈谈 Go 如何让程序利用在多处理器 / 多线程环境中运行的优势。或者说,Go 提供了什么工具来编写并发程序,因为它不是关于线程或核心的:它是关于 routine 的。
Goroutine
假设我们调用一个函数 f(s):这样的写法就是通常的调用方式,同步运行。如果要在 goroutine 中调用这个函数,使用 go f(s) 即可。这个新 goroutine 将和调用它的 goroutine 并发执行。但是... 什么是 goroutine 呢?这是一个独立执行的函数,由 go 语句启动。它有自己的调用堆栈,这个堆栈可以根据需要增长和缩减,而且非常节省空间。拥有数千甚至数十万个 goroutine 是实际存在的,但它不是线程。事实上,在一个有数千个 goroutine 的程序中可能只有一个线程。相反,goroutines 会根据需要动态复用到线程上,以保持所有的 goroutine 运行。如果你把它当成一种便宜的线程,也不会差太多。
package main
import "fmt"
func f(from string) {
for i := 0; i < 3; i++ {
fmt.Println(from, ":", i)
}
}
func main() {
// Suppose we have a function call `f(s)`. Here's how
// we'd call that in the usual way, running it
// synchronously.
f("direct")
// To invoke this function in a goroutine, use
// `go f(s)`. This new goroutine will execute
// concurrently with the calling one.
go f("goroutine")
// You can also start a goroutine for an anonymous
// function call.
go func(msg string) {
fmt.Println(msg)
}("going")
// Our two function calls are running asynchronously in
// separate goroutines now, so execution falls through
// to here. This `Scanln` code requires we press a key
// before the program exits.
var input string
fmt.Scanln(&input)
fmt.Println("done")
}
更多细节 3
正如我所说的,coroutine 背后的想法是复用独立执行的函数--coroutines--在一组线程上。当一个 coroutine 阻塞的时候,比如通过调用一个阻塞的系统调用, run-time 会自动地将同一个操作系统线程上的其他 coroutines 移动到一个不同的,可运行的线程上,这样它们就不会被阻塞。这些 coroutines 被称为 goroutines,非常便宜。它们的堆栈内存很少,只有几千字节。此外,为了使堆栈变小,Go 的 run-time 使用可调整大小的有界堆栈。新建的 goroutine 有几千字节,这个大小几乎总是足够的。当空间不够时,run-time 会自动增长(缩小)用于存储堆栈的内存,从而允许许多 goroutines 生存在适量的内存中。每个函数调用的 CPU 开销平均需要大约三个廉价的指令,所以在相同的地址空间中创建数十万个 goroutine 是很实际的。如果 goroutines 只是线程,那么系统资源将会用得更少。
好吧,真的很酷,但... 为什么?为什么我们要编写并发程序?要更快地完成我们的工作(即使编写正确的并发程序可能花费的时间比在并行环境中运行任务的时间长 XD)典型的线程情况包括分配一些共享内存并将其位置存储在 p 中的主线程。主线程启动 n 个工作线程,将指针 p 传递给他们,工作线程可以使用 p 来处理 p 指向的数据。但是如果线程开始更新相同的内存地址呢?我是说,这是计算机科学中最难的一个。好吧,让我们从简考虑:从操作系统的角度来看,一些原子系统调用让你锁定对共享内存区域的访问(我是指信号量,消息队列,锁等)。从语言角度来看,通常有一组原语,调用所需的系统调用,并让你将访问权限同步到共享内存区域(我是指像多处理,多线程,池等的包)。下面,我们来谈谈 Go 的一个工具,它可以帮助您处理 goroutine 之间的并发通信:channels。
Channels
Channels 是一个输入管道,你可以通过通道操作符 <- 发送和接收值。这就是全部:D. 你只需要知道当一个 main 函数执行 <-c 时,它将等待一个值被发送。同样,当 goroutined 函数执行 c<-value 值时,它等待接收器准备就绪。发送者和接收者都必须准备好,来在通信中发挥作用。否则,我们要等到它们准备好:你不必处理信号量,锁等等:channels 可以同时实现通信和同步。记住和理解这一点非常重要,也是 Go 和我所知道的其他语言之间最大的区别之一。
package main
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // send sum to c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x+y)
}
更多细节 4
正如官方文档所述,channel 提供了一种机制,用于通过发送和接收指定元素类型的值来并发执行函数来进行通信。这很简单。我还没有说的是,一个 channel 作为一种类型,不同于它承载的信息类型:
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType
可选的 <- 运算符指定通道方向,发送或接收. 如果没有方向,通道是双向的。channel 可能仅限于发送或仅通过转换或分配接收。
chan T // can be used to send and receive values of type T
chan<- float64 // can only be used to send float64s
<-chan int // can only be used to receive ints
为了帮助您解决某些特定的同步问题,您还可以使用 make(make(chan int,100)) 函数创建一个 buffered channel. 容量, 也就是按元素数量,设置 channel 中缓冲区的大小。如果容量为零或不存在,则只有在发送方和接收方都准备好的情况下,channel 才能无缓存,并且通信成功。否则,如果缓冲区未满(发送)或不空闲(接收),则 channel 被缓冲并且通信成功而不阻塞。 一个零 channel 永远不会准备好通讯:我发现通过使用缓冲 channel,可以隐式地设置在运行时要使用的最大程序数量,这对于我的基准测试是非常有用的。
总结
总而言之,你可以在 goroutine 中调用一个函数,甚至是匿名函数, 然后把结果放在一个 channel 中,默认情况下,发送和接收阻塞,直到另一端准备好。所有这些特性都允许 goroutine 在没有显式锁定或条件变量的情况下进行同步。好吧,但是... 他们表现地怎么样呢?
Go vs Python
好吧,我是一个 Python 爱好者-我想,因为它在标题中,我不记得. md 各自的源代码在哪里. 所以我决定做一个比较,看看这些神奇的 Go 巧妙的语句如何真正执行。为此,我编写了一个简单的 go-py 程序(这里 是代码),它完成了对随机整数列表的合并排序,可以在单核环境或多核环境中运行。或者,在单个例程或多个例程_环境中:这是因为,正如我所说的,go-routine 是一个在 Python 中不可用的概念,比线程更深入。请记住,不止一个 go-routine 可以属于一个单独的线程。相反,从 Python 的角度来看,你只能使用进程,线程以及信号量,锁定,锁等等,但不可能重现完全相同的计算。我的意思是,这是正常的,他们是不同的语言,但他们最后都调用一组系统调用。无论如何,我认为当你运行这种并发性实验时,你可以做的是尽可能地重现一个在逻辑上的等价性的计算。我们从 Go 版本开始。
Go 合并排序
Go 和 Python 版本的程序都提供了两个功能:
- 单 routine;
- 多个前缀数的 routine;
简单的 Go 版本
好吧,我不会讲太多关于单 routine 的方法:这很简单。下面你可以看到我能够考虑的最优化版本的代码(就 io 操作而言), Github 上的评论版本:
func msort_sort(a []int) []int {
if len(a) <= 1 {
return a
}
m := int(math.Floor(float64(len(a)) / 2))
return msort_merge(msort_sort(a[0:m]), msort_sort(a[m:]))
}
func msort_merge(l []int, r []int) []int {
a := []int{}
for len(l) > 0 || len(r) > 0 {
if len(l) == 0 {
a = append(a, r[len(r)-1])
if len(r) > 1 {
r = r[:len(r)-1]
} else {
r = []int{}
}
} else {
if len(r) == 0 || (l[len(l)-1] > r[len(r)-1]) {
a = append(a, l[len(l)-1])
if len(l) > 1 {
l = l[:len(l)-1]
} else {
l = []int{}
}
} else {
if len(r) > 0 {
a = append(a, r[len(r)-1])
if len(r) > 1 {
r = r[:len(r)-1]
} else {
r = []int{}
}
}
}
}
}
return reverse(a)
}
我不认为这需要解释:如果您有任何问题,请不要犹豫在评论中写下意见!我会尽快回答。
并发的 Go 版本
我们来谈谈并发版本。我们可以拆分数组,并从主例程调用子例程,但是我们如何控制并发执行 go-routine 或工作数的最大数量?那么,限制 Go 中的并发的一种方法 5 是使用缓冲通道(信号量)。正如我所说的,当你创建一个具有固定维度的通道或缓冲,如果缓冲区未满(发送)或不为空(接收),通信成功而不会阻塞,所以你根据你想拥有的并发单元的数量,实现一个信号量来轻松地阻止执行。真的很酷,但是... 有一个问题:一个 channel 是一个 channel,即使有缓冲,频道上的基本发送和接收也被阻止。幸运的是,Go 非常棒,让你创建明确的非阻塞通道, 使用 select 语句 6 :因此,您可以使用 select with default 子句来实现无阻塞的发送,接收,甚至是非阻塞的多路选择。还有一些其他的声明来解释,在我的前缀最大数量的并发 goroutine 版本的合并排序:
// Returns the result of a merge sort - the sort part - over the passed list
func merge_sort_multi(s []int, sem chan struct{}) []int {
// return ordered 1 element array
if len(s) <= 1 {
return s
}
// split length
n := len(s) / 2
// create a wait group to wait for both goroutine call before final merge step
wg := sync.WaitGroup{}
wg.Add(2)
// result of goroutine
var l []int
var r []int
// check if passed buffered channel is full
select {
// check if you can acquire a slot
case sem <- struct{}{}:
// call another goroutine worker over the first half
go func() {
l = merge_sort_multi(s[:n], sem)
// free a slot
<-sem
// unlock one semaphore
wg.Done()
}()
default:
l = msort_sort(s[:n])
wg.Done()
}
// the same over the second half
select {
case sem <- struct{}{}:
go func() {
r = merge_sort_multi(s[n:], sem)
<-sem
wg.Done()
}()
default:
r = msort_sort(s[n:])
wg.Done()
}
// wait for go subroutine
wg.Wait()
// return
return msort_merge(l, r)
}
正如你所看到的,在我的默认选择操作中,我编写了一个调用单 routined 版本的合并排序。但是,代码中还有一个有趣的工具:它是由 sync 包提供的 WaitGroup 对象。从官方文档 7 来看 ,WaitGroup 等待一系列 goroutines 完成。main goroutine 调用 Add 来设置要等待的 goroutines 的数量。然后,每个 goroutine 程序运行并完成后调用 Done。同时,Wait 可以用来阻塞,直到所有的 goroutines 都完成了。
Python 合并排序
好吧,在这里,如果你到了这里,我会诚实的说:我不是一个并发专家,实际上我真的讨厌并发,但是写这篇文章和测试 Go channel 让我学到了很多关于这个主题的知识:在 Python 中尽可能复制一个在逻辑上大部分相同的计算真的很难。
简单的 Py 版本
def msort_sort(array):
n = len(array)
if n <= 1:
return array
left = array[:n / 2]
right = array[n / 2:]
return msort_merge(msort_sort(left), msort_sort(right))
def msort_merge(*args):
left, right = args[0] if len(args) == 1 else args
a = []
while left or right:
if not left:
a.append(right.pop())
elif not right or left[-1] > right[-1]:
a.append(left.pop())
else:
a.append(right.pop())
a.reverse()
return a
并发 Py 版本
我不得不为这个并发版本想很多:首先,我想使用一个线程 / 进程数组,并启动 / 加入他们,但是,后来我意识到这与我的 Go 版本不太一样。首先,因为对多于一个线程 / 进程的调用只能在原始数据的一个分区上完成一次, 最终以并行合并的方式合并:这不完全是我的 Go 版本的行为,递归调用一个并发例程,直到信号量接受新的并发例程,最后调用排序方法的单例程实例。所以我想 “我简直不可能在 Python 中使用简单的一次性分裂方法来实现我的合并排序的多例程(线程或进程),因为它不是计算上等同的”。出于这个原因,我尝试的第一件事是使用 Python 中的信号量原语重新表示 Channel 和 WaitGroup 的完全相同的行为。经过几天的工作,我得到了它。让我们看看代码:
def merge_sort_parallel_golike(array, bufferedChannel, results):
# if array length is 1, is ordered : return
if len(array) <= 1:
return array
# compute length
n = len(array) / 2
# append thread for subroutine
ts = []
# try to acquire channel
if bufferedChannel.acquire(blocking=False):
# if yes, setup call on the first half
ts.append(Thread(target=merge_sort_parallel_golike, args=(array[:n], bufferedChannel, results,)))
else:
# else call directly the merge sort over the first halft
results.append(msort_sort(array[:n]))
# the same, in the second half
if bufferedChannel.acquire(blocking=False):
ts.append(Thread(target=merge_sort_parallel_golike, args=(array[n:], bufferedChannel, results,)))
else:
results.append(msort_sort(array[n:]))
# start thread
for t in ts:
t.start()
# wait for finish
for t in ts:
t.join()
# append results
results.append(msort_merge(results.pop(0), results.pop(0)))
# unlock the semaphore for another threads for next call to merge_sort_parallel_golike
# try is to prevent arise of exception in the end
try:
bufferedChannel.release()
except:
pass
if __name__ == "__main__":
# manager to handle routine response
manager = Manager()
responses = manager.list()
sem = BoundedSemaphore(routinesNumber)
merge_sort_parallel_golike(a, sem, responses)
a = responses.pop(0)
好吧,让我们从 manager 开始。在主体中初始化的 Manager 对象提供了一个结构来放置调用的响应 - 或多或少类似于 Queue。BoundedSemaphore 扮演着我之前谈到的有界 channel 信号量的角色。信号量是一个比简单的锁更高级的锁机制:它有一个内部的计数器而不是一个锁定标志,并且只有当超过给定数量的线程试图持有信号才会阻塞它。根据信号量的初始化方式,这允许多个线程同时访问相同的代码段:幸运的是,如果你失败了,你可以尝试获得锁定并继续执行--这起到了前面提到的在 Go 版本中使用的 select 技巧, 通过使用 blocking = False 作为 (bufferedChannel.acquire(blocking = False)) 的参数。有了 join,我模拟了 WaitGroup 的行为,因为我认为这是在继续最后的合并步骤之前同步这两个线程并等待它们结束的标准方式。这里有任何问题么?
你想知道"它的表现怎么样"好吧,它逊爆了。我的意思是:非常逊。所以我试图寻找更有效率的东西... 我找到了这个. 类似于我想到的第一个解决方案,但使用 Pool 对象。
def merge_sort_parallel_fastest(array, concurrentRoutine, threaded):
# create a pool of concurrent threaded or process routine
if threaded:
pool = ThreadPool(concurrentRoutine)
else:
pool = Pool(concurrentRoutine)
# size of partitions
size = int(math.ceil(float(len(array)) / concurrentRoutine))
# partitioning
data = [array[i * size:(i + 1) * size] for i in range(concurrentRoutine)]
# mapping each partition to one worker, using the standard merge sort
data = pool.map(msort_sort, data)
# go ahead until the number of partition are reduced to one (workers end respective ordering job)
while len(data) > 1:
# extra partition if there's a odd number of worker
extra = data.pop() if len(data) % 2 == 1 else None
# prepare couple of ordered partition for merging
data = [(data[i], data[i + 1]) for i in range(0, len(data), 2)]
# use the same number of worker to merge partitions
data = pool.map(msort_merge, data) + ([extra] if extra else [])
# return result
return data[0]
而且这个表现更好。问题是使用线程或进程更好?那么,看看我的比较图!
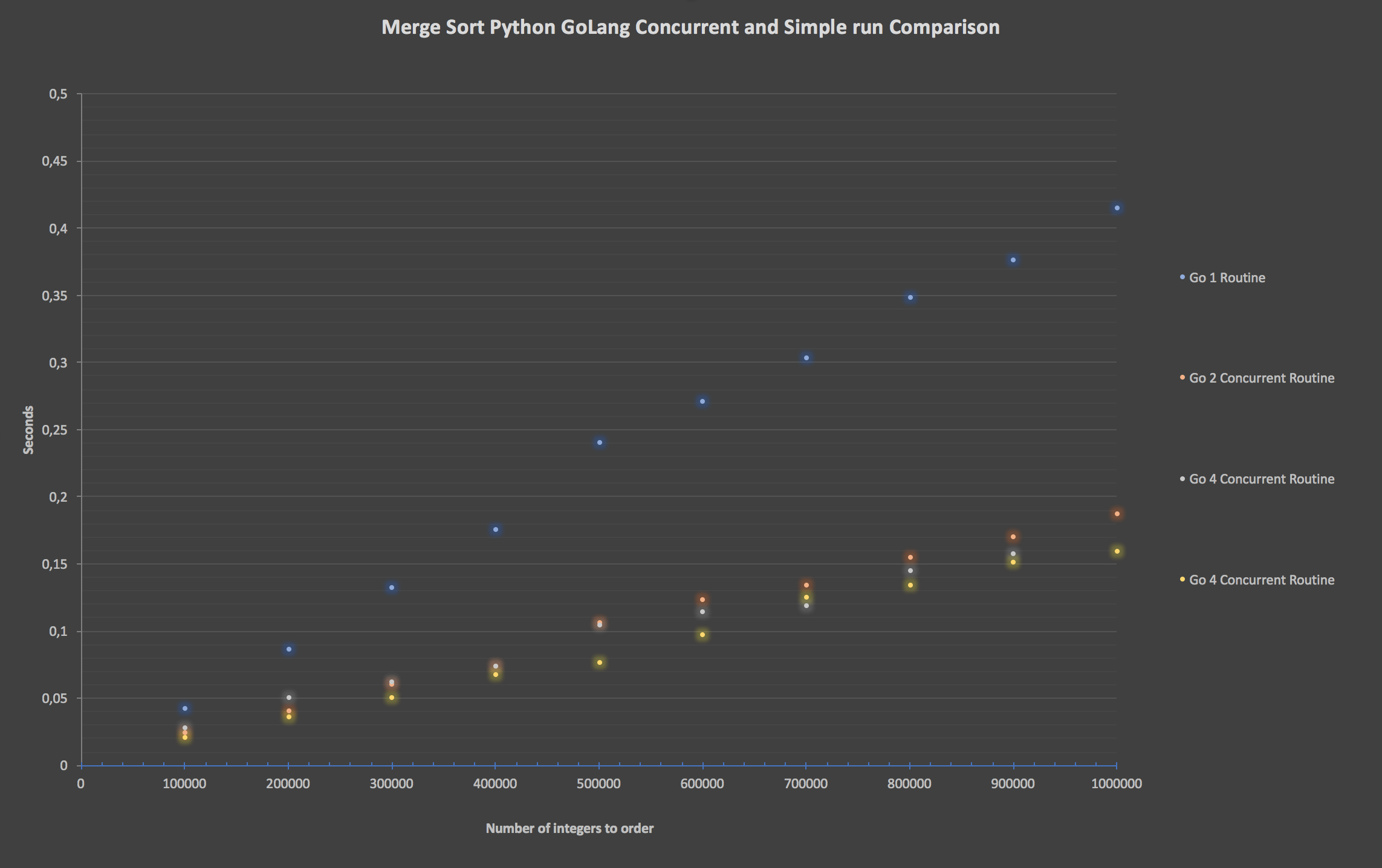
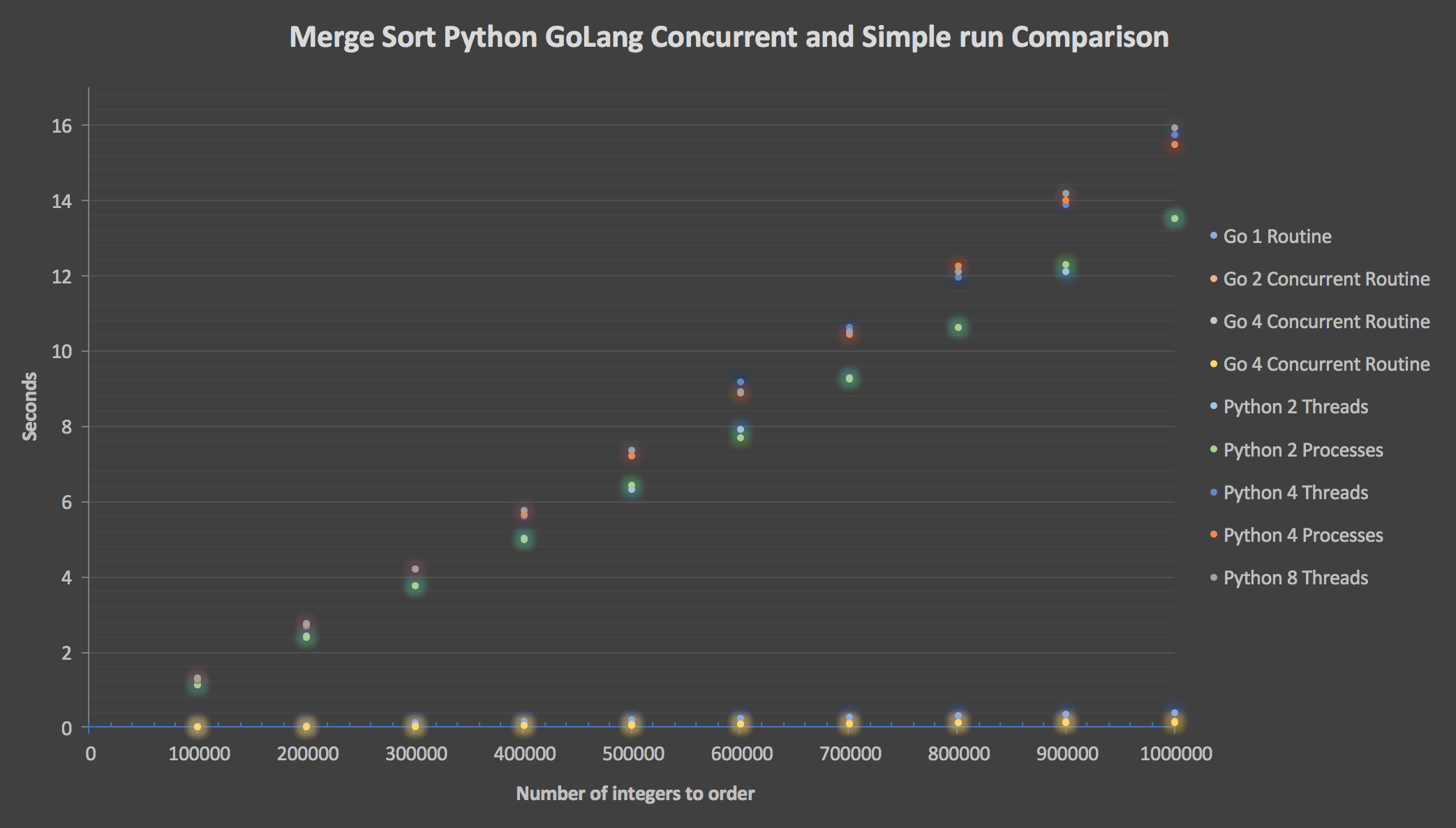 好吧,因为 Python 版本不太好,这是一个只有 Go 系列的图表
好吧,因为 Python 版本不太好,这是一个只有 Go 系列的图表
结论
Python 糟透了。 Go 完胜。对不起,Python:我爱你。完整的代码可以在这里找到:go-py-benchmark。
谢谢大家的阅读!
1 这里可以在线获得很多关于 Go talk 的 幻灯片!
2. Rob Pike 的课程:并发不是并行的。
3. 直接来源官方 FAQ 页面。
4. 更多信息在 这里。
5. 来源 在这
6. 看看 这里
7. 这里更多关于 WaitGroup 的信息
via: https://made2591.github.io/posts/go-py-benchmark
作者:Matteo Madeddu 译者:Titanssword 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





