
前序(Prelude)
本系列文章总共四篇,主要帮助大家理解 Go 语言中一些语法结构和其背后的设计原则,包括指针、栈、堆、逃逸分析和值/指针传递。这是第二篇,主要介绍堆和逃逸分析。
以下是本系列文章的索引:
介绍(Introduction)
在四部分系列的第一部分,我用一个将值共享给 goroutine 栈的例子介绍了指针结构的基础。而我没有说的是值存在栈之上的情况。为了理解这个,你需要学习值存储的另外一个位置:堆。有这个基础,就可以开始学习逃逸分析。
逃逸分析是编译器用来决定你的程序中值的位置的过程。特别地,编译器执行静态代码分析,以确定一个构造体的实例化值是否会逃逸到堆。在 Go 语言中,你没有可用的关键字或者函数,能够直接让编译器做这个决定。只能够通过你写代码的方式来作出这个决定。
堆(Heaps)
堆是内存的第二区域,除了栈之外,用来存储值的地方。堆无法像栈一样能自清理,所以使用这部分内存会造成很大的开销(相比于使用栈)。重要的是,开销跟 GC(垃圾收集),即被牵扯进来保证这部分区域干净的程序,有很大的关系。当垃圾收集程序运行时,它会占用你的可用 CPU 容量的 25%。更有甚者,它会造成微秒级的 “stop the world” 的延时。拥有 GC 的好处是你可以不再关注堆内存的管理,这部分很复杂,是历史上容易出错的地方。
在 Go 中,会将一部分值分配到堆上。这些分配给 GC 带来了压力,因为堆上没有被指针索引的值都需要被删除。越多需要被检查和删除的值,会给每次运行 GC 时带来越多的工作。所以,分配算法不断地工作,以平衡堆的大小和它运行的速度。
共享栈(Sharing Stacks)
在 Go 语言中,不允许 goroutine 中的指针指向另外一个 goroutine 的栈。这是因为当栈增长或者收缩时,goroutine 中的栈内存会被一块新的内存替换。如果运行时需要追踪指针指向其他的 goroutine 的栈,就会造成非常多需要管理的内存,以至于更新指向那些栈的指针将使 “stop the world” 问题更严重。
这里有一个栈被替换好几次的例子。看输出的第 2 和第 6 行。你会看到 main 函数中的栈的字符串地址值改变了两次。https://play.golang.org/p/pxn5u4EBSI
逃逸机制(Escape Mechanics)
任何时候,一个值被分享到函数栈帧范围之外,它都会在堆上被重新分配。这是逃逸分析算法发现这些情况和管控这一层的工作。(内存的)完整性在于确保对任何值的访问始终是准确、一致和高效的。
通过查看这个语言机制了解逃逸分析。https://play.golang.org/p/Y_VZxYteKO
清单 1
package main
type user struct {
name string
email string
}
func main() {
u1 := createUserV1()
u2 := createUserV2()
println("u1", &u1, "u2", &u2)
}
//go:noinline
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
//go:noinline
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
我使用 go:noinline 指令,阻止在 main 函数中,编译器使用内联代码替代函数调用。内联(优化)会使函数调用消失,并使例子复杂化。我将在下一篇博文介绍内联造成的副作用。
在表 1 中,你可以看到创建 user 值,并返回给调用者的两个不同的函数。在函数版本 1 中,返回值。
清单 2
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
我说这个函数返回的是值是因为这个被函数创建的 user 值被拷贝并传递到调用栈上。这意味着调用函数接收到的是这个值的拷贝。
你可以看下第 17 行到 20 行 user 值被构造的过程。然后在第 23 行,user 值的副本被传递到调用栈并返回给调用者。函数返回后,栈看起来如下所示。
图 1
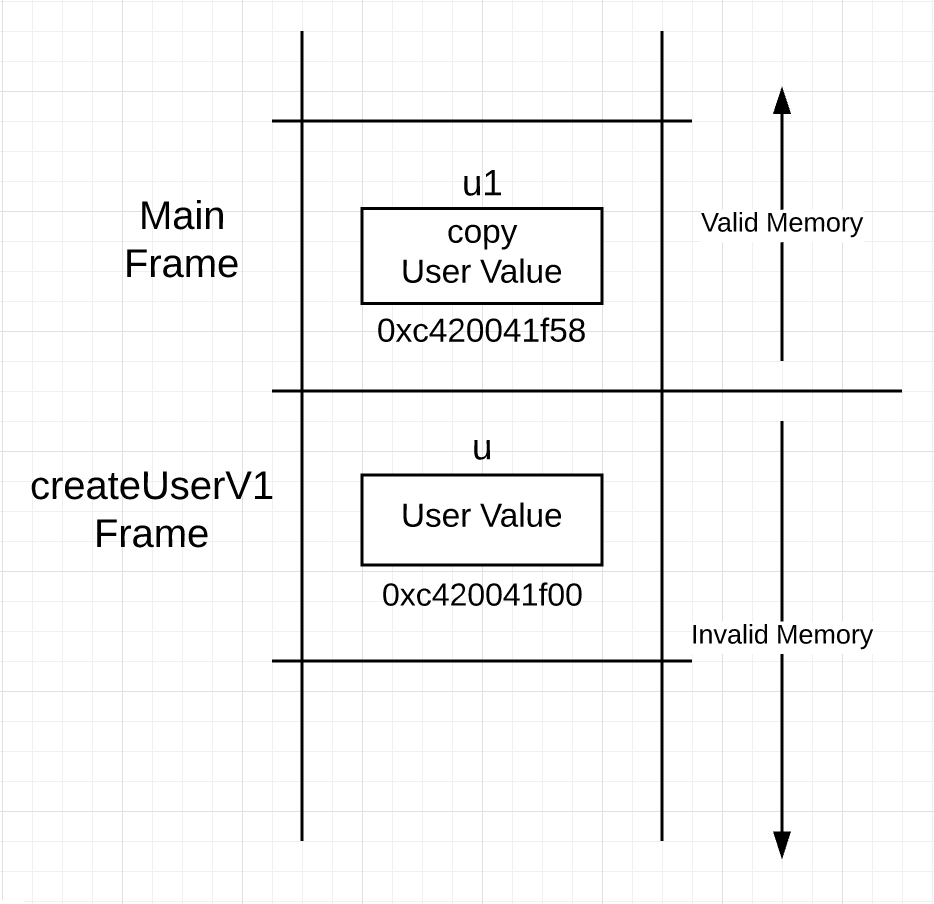
你可以看到图 1 中,当调用完 createUserV1 ,一个 user 值同时存在(两个函数的)栈帧中。在函数版本 2 中,返回指针。
清单 3
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
我说这个函数返回的是指针是因为这个被函数创建的 user 值通过调用栈被共享了。这意味着调用函数接收到一个值的地址拷贝。
你可以看到在第 28 行到 31 行使用相同的字段值来构造 user 值,但在第 34 行返回时却是不同的。不是将 user 值的副本传递到调用栈,而是将 user 值的地址传递到调用栈。基于此,你也许会认为栈在调用之后是这个样子。
图 2
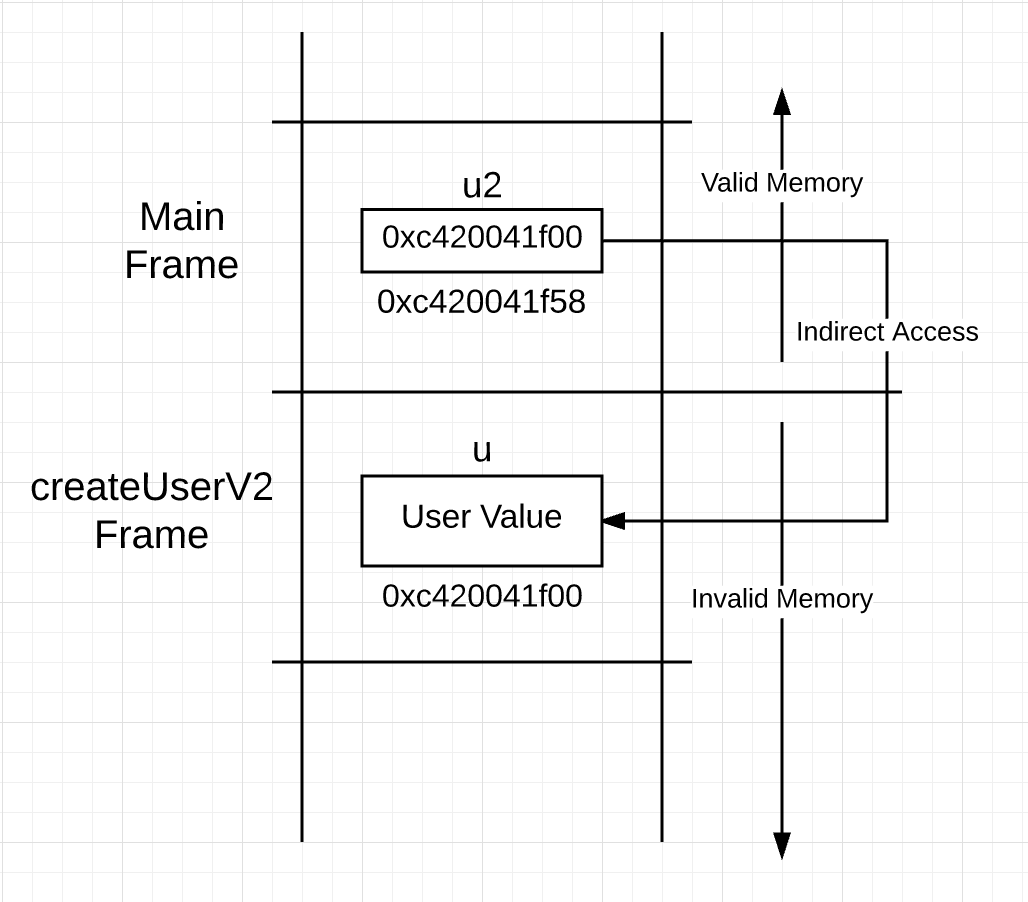
如果看到的图 2 真的发生的话,你将遇到一个问题。指针指向了栈下的无效地址空间。当 main 函数调用下一个函数,指向的内存将重新映射并将被重新初始化。
这就是逃逸分析将开始保持完整性的地方。在这种情况下,编译器将检查到,在 createUserV2 的(函数)栈中构造 user 值是不安全的,因此,替代地,会在堆中构造(相应的)值。这(个分析并处理的过程)将在第 28 行构造时立即发生。
可读性(Readability)
在上一篇博文中,我们知道一个函数只能直接访问它的(函数栈)空间,或者通过(函数栈空间内的)指针,通过跳转访问(函数栈空间外的)外部内存。这意味着访问逃逸到堆上的值也需要通过指针跳转。
记住 createUserV2 的代码的样子:
清单 4
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
语法隐藏了代码中真正发生的事情。第 28 行声明的变量 u 代表一个 user 类型的值。Go 代码中的类型构造不会告诉你值在内存中的位置。所以直到第 34 行返回类型时,你才知道值需要逃逸(处理)。这意味着,虽然 u 代表类型 user 的一个值,但对该值的访问必须通过指针进行。
你可以在函数调用之后,看到堆栈就像(图 3)这样。
图 3
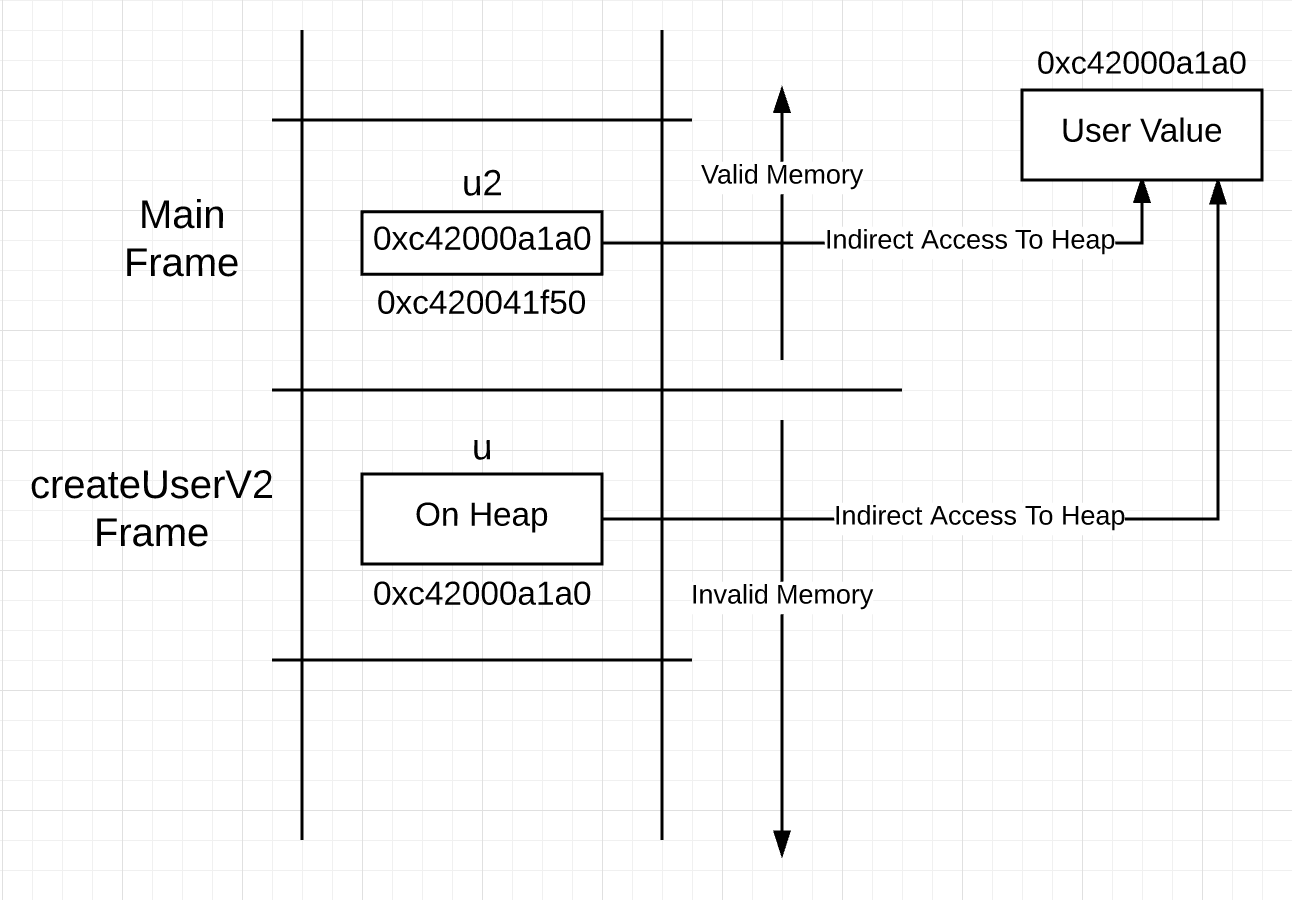
在 createUserV2 函数栈中,变量 u 代表的值存在于堆中,而不是栈。这意味着用 u 访问值时,使用指针访问而不是直接访问。你可能想,为什么不让 u 成为指针,毕竟访问它代表的值需要使用指针?
清单 5
27 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
如果你这样做,将使你的代码缺乏重要的可读性。(让我们)离开整个函数一秒,只关注 return。
清单 6
34 return u
35 }
这个 return 告诉你什么了呢?它说明了返回 u 值的副本给调用栈。然而,当你使用 & 操作符,return 又告诉你什么了呢?
清单 7
34 return &u
35 }
多亏了 & 操作符,return 告诉你 u 被分享给调用者,因此,已经逃逸到堆中。记住,当你读代码的时候,指针是为了共享,& 操作符对应单词 "sharing"。这在提高可读性的时候非常有用,这(也)是你不想失去的部分。
清单 8
01 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
为了让其可以工作,你一定要通过共享指针变量(的方式)给(函数) json.Unmarshal。json.Unmarshal 调用时会创建 user 值并将其地址赋值给指针变量。https://play.golang.org/p/koI8EjpeIx
代码解释:
01:创建一个类型为 user,值为空的指针。
02:跟函数 json.Unmarshal 函数共享指针。
03:返回 u 的副本给调用者。
这里并不是很好理解,user值被 json.Unmarshal 函数创建,并被共享给调用者。
如何在构造过程中使用语法语义来改变可读性?
清单 9
01 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
代码解释:
01:创建一个类型为 user,值为空的变量。
02:跟函数 json.Unmarshal 函数共享 u。
03:跟调用者共享 u。
这里非常好理解。第 02 行共享 user 值到调用栈中的 json.Unmarshal,在第 03 行 user 值共享给调用者。这个共享过程将会导致 user 值逃逸。
在构建一个值时,使用值语义,并利用 & 操作符的可读性来明确值是如何被共享的。
编译器报告(Compiler Reporting)
想查看编译器(关于逃逸分析)的决定,你可以让编译器提供一份报告。你只需要在调用 go build 的时候,打开 -gcflags 开关,并带上 -m 选项。
实际上总共可以使用 4 个 -m,(但)超过 2 个级别的信息就已经太多了。我将使用 2 个 -m 的级别。
清单 10
$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
你可以看到编译器报告是否需要逃逸处理的决定。编译器都说了什么呢?请再看一下引用的 createUserV1 和 createUserV2 函数。
清单 13
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
从报告中的这一行开始。
清单 14
./main.go:22: createUserV1 &u does not escape
这是说在函数 createUserV1 调用 println 不会造成 user 值逃逸到堆。这是必须检查的,因为它将会跟函数 println 共享(u)。
接下来看报告中的这几行。
清单 15
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
这几行是说,类型为 user,并在第 31 行被赋值的 u 的值,因为第 34 行的 return 逃逸。最后一行是说,跟之前一样,在 33 行调用 println 不会造成 user 值逃逸。
阅读这些报告可能让人感到困惑,(编译器)会根据所讨论的变量的类型是基于值类型还是指针类型而略有变化。
将 u 改为指针类型的 *user,而不是之前的命名类型 user。
清单 16
27 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
再次生成报告。
清单 17
./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
现在报告说在 28 行赋值的指针类型 *user,u 引用的 user 值,因为 34 行的 return 逃逸。
结论
值在构建时并不能决定它将存在于哪里。只有当一个值被共享,编译器才能决定如何处理这个值。当你在调用时,共享了栈上的一个值时,它就会逃逸。在下一篇中你将探索一个值逃逸的其他原因。
这些文章试图引导你选择给定类型的值或指针的指导原则。每种方式都有(对应的)好处和(额外的)开销。保持在栈上的值,减少了 GC 的压力。但是需要存储,跟踪和维护不同的副本。将值放在堆上的指针,会增加 GC 的压力。然而,也有它的好处,只有一个值需要存储,跟踪和维护。(其实,)最关键的是如何保持正确地、一致地以及均衡(开销)地使用。
via: https://www.ardanlabs.com/blog/2017/05/language-mechanics-on-escape-analysis.html
作者:William Kennedy 译者:gogeof 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





好文。只是内联在此处并没有本质的影响,似乎没必要『禁止内联』
@alex_023 在这里禁止内联,我觉得应该是作者为了降低分析和描述的复杂化,专注于一个问题,更有利于读者理解.
DCL l(31) . . . . . NAME-main.err a(true) g(5) l(31) x(0) class(PAUTO) f(1) tc(1) used error
请问这种怎么看呢? 我加了4个 -m , a,g,l,x,class,f,tc都啥意思呢? 有啥参考资料吗? 谢谢🙏
好文,Go 的这个设定有点意思; 当你读代码的时候,指针是为了共享,
&操作符对应单词 "sharing" 这句应是本文的核心主题吧.清单8和清单9中json.Unmarshal([]byte(r), &u)的传值中,一个是u的指针,一个是指向指针的指针。不会有问题么?
请问下为什么golang中的栈在增长或者收缩时位置会发生变化呢?
感觉内容写错了吧,&的作用是用来共享变量,而你上面V2取了地址了,为什么还要取一层地址,不是什么地址拷贝吧。看来你对golang的&不理解。
createUserV2函数返回的就是共享变量的一个地址了.
基于你的例子改写的 https://play.golang.org/p/SK8bidoK5TY
此文分析的说了半天,实在搞不懂跟逃逸分析 有什么关系,就一个&把变量地址共享,还牵出逃逸分析
可能是习惯了,几乎很少在 return 之前才去加&, 文中说到的 “好理解”,没什么感觉
没觉得是高大上的分析,但是觉得是对汇编知识的扭曲!每种语言的对象到底存在哪里真的说不准,每个版本都不一样!分析这些东西最好说明版本,对于会汇编的我来说,几乎本文没有任何价值,甚至是在扭曲或者增加go程序员的负担!建议读者不必太重视这个,因为上层软件师即使学精了这方面,也仅仅是对go某个版本的内存开辟有了解,但并不是每个版本的内存开辟都有差异!
“但并不是每个版本的内存开辟都有差异!” 看到这句笑死我了
确实,我也经常看到卧躺在街边的大佬傻笑。。呵呵!
这里禁止内联,是因为,如果编译器优化成内联的话,就没有调用函数栈这个过程了,也就没有帧边界的事了,所以最后就不会发生逃逸了