
上一篇博文 我们看了看用 Terraform 创建容器引擎集群。在本篇博文里,我们看看使用容器引擎和 Kubernetes 部署容器到集群里。
Kubernetes
首先,什么是 Kubernetes ? Kubernetes 是一个开源的、管理容器的框架。与平台无关,就是说着你可以在你本机上,在 AWS 或者 Google Cloud,任何其他的平台运行它。(Kubernetes)能让你通过使用声明的配置内容,控制一组容器,和容器的网络规则。
你只需要写个 yaml/json 文件,描述下需要在哪运行哪个容器。定义你的网络规则,比如端口转发。它就会帮你管理服务发现。
Kubernetes 是云场景的重要补充,而且现在正迅速成为云容器管理实际选择。因此了解下是比较好的。
那么我们开始吧!
首先,确保你已经在本地安装了 kubectl cli:
$ gcloud components install kubectl
现在确保你连接到集群,并且认证正确。第一步,我们登录进去,确保已被认证。第二步我们设置下项目配置,确保我们使用正确的项目 ID 和可访问区域。
$ echo "This command will open a web browser, and will ask you to login
$ gcloud auth application-default login
$ gcloud config set project shippy-freight
$ gcloud config set compute/zone eu-west2-a
$ echo "Now generate a security token and access to your KB cluster"
$ gcloud container clusters get-credentials shippy-freight-cluster
在上面的命令中,你可以将 compute/zone 替换成你选的任何区域,你的项目 id 和集群名称也可以和我的不一样。
下面是个概括描述...
$ echo "This command will open a web browser, and will ask you to login
$ gcloud auth application-default login
$ gcloud config set project <project-id>
$ gcloud config set compute/zone <availability-zone>
$ echo "Now generate a security token and access to your KB cluster"
$ gcloud container clusters get-credentials <cluster-name>
点这你可以看到项目 ID...

现在找下我们的项目 ID...
集群区域 region/zone 和集群名称可以点菜单左上角的 'ComputeEngine',然后选 'VM Instances' 就找到了。 你能看到你的 Kubernetes VM,点进去看更多细节,这能看见和你集群相关的每个内容。
如果你运行下...
$ kubectl get pods
你会看到 ... No resources found.。没关系,我们还没有部署任何内容。我们可以想想我们需要实际部署些什么。我们需要一个 Mongodb 实例。一般来说,我们会部署一个 mongodb 实例,或者为了完全分离,将数据库实例和每个服务放一起。但是这个例子里,我们耍点小聪明,就用一个中心化的实例。这是个单一故障点,但是在实际应用场景中,你要考虑下将数据库实例分开部署,和服务保持一致。不过我们这种方法也可以。
然后我需要部署服务了,vessel 服务,user 服务,consignment 服务和 email 服务。好了,很简单!
从 Mongodb 实例开始吧。因为它不属于一个单独的服务,而且这是的平台整体的一部分,我们把这些部署放在 shippy-infrastructure 仓库下。这个仓库我提交到了 Github ,因为包含了很多敏感数据,但是我可以给你们所有的部署文件。
首先,我们需要一个配置创建一个 ssd,用于长期存储。这样当我们重启容器的时候就不会丢失数据。
// shippy-infrastructure/deployments/mongodb-ssd.yml
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
然后是我们的部署文件(我们通过本文来深入更多细节)...
// shippy-infrastructure/deployments/mongodb-deployment.yml
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: mongo
spec:
serviceName: "mongo"
replicas: 3
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
role: mongo
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mongo
image: mongo
command:
- mongod
- "--replSet"
- rs0
- "--smallfiles"
- "--noprealloc"
- "--bind_ip"
- "0.0.0.0"
ports:
- containerPort: 27017
volumeMounts:
- name: mongo-persistent-storage
mountPath: /data/db
- name: mongo-sidecar
image: cvallance/mongo-k8s-sidecar
env:
- name: MONGO_SIDECAR_POD_LABELS
value: "role=mongo,environment=test"
volumeClaimTemplates:
- metadata:
name: mongo-persistent-storage
annotations:
volume.beta.kubernetes.io/storage-class: "fast"
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
然后是 service 文件...
apiVersion: v1
kind: Service
metadata:
name: mongo
labels:
name: mongo
spec:
ports:
- port: 27017
targetPort: 27017
clusterIP: None
selector:
role: mongo
还有很多,现在对你来说可能没什么意义。那么我们试试理清一些 Kubernetes 的关键概念。
Nodes
Nodes 是你的物理机或者 VM,你的容器通过 node 做集群,服务通过运行在不同 node/pod 上的一组组容器互相访问。
Pods
Pod 是一组相关的容器。比如,一个 pod 可以包含你的认证服务容器,用户数据库容器,登陆注册用户接口等等。这些容器都是明显有相关性的。Pod 允许你将他们组合在一起,这样他们能互相访问,并且运行在相同的即时网络环境下,你可以把他们当做一个整体。这很酷啊!Pod 是 Kubernetes 里非常不容易理解的特性。
Deployment
Deployment 是用来控制状态的,一个 deployment 就是最终要输出和要保持的状态的描述文件。一个 deployment 是 Kubernetes 的介绍,比如说,我想要三个容器,运行在三个端口,用某些环境变量。Kubernetes 会确保维持这个状态。如果一个容器崩溃了,剩下两个容器,它会再启动一个满足三个容器的需求。
StatefulSet
stateful set 和 deployment 有相似的地方,除了它会用一些存储方式,保持容器相关的状态。比如分布存储的概念。
实际情况里,Mongodb 将数据写入二进制数据存储格式,很多数据库都是这样做的。创建一个可回收的数据库实例,比如 docker 容器。如果容器重启数据会丢失。一般来说你需要在容器启动的时候使用分卷装载数据/文件。
你可以在 Kubernetes 上做这些部署。但是 StatefulSets,在相关的集群点有一些额外的自动化操作。因此这个对 mongodb 容器天然的合适。
Service
服务是一组网络相关的规则,比如端口转发和 DNS 规则,在网络层面上连接你的 pod,控制谁和谁可以通信,谁可以被外部访问。
有两种服务你可能会遇到,一是 load balancer,一是 node port。
load balancer,是一个轮询的负载均衡器,可以给你选的 node 节点创建一个 IP 地址给代理。通过代理把服务暴露给外部。
node port 将 pod 暴露给上层的网络环境,这样他们可以被其他服务, 内部的pod/实例访问。这样对暴露 node 给其他的 pod 来说是有用的。这就是你能用来允许服务和其他服务通信的方式。这就是服务发现的本质。至少是一部分。
现在我们刚看了一点点 Kubernetes 的内容,我们来再多谈些,再挖掘挖掘。值得注意的是,如果你是个在本机上使用 docker ,比如如果你用的是 mac/windows 上的 docker 的 edge 版本,你可以把 Kubernetes 集群钉在本机上。测试时候很有用。
那么我们已经创建了三个文件,一个用于存储,一个用于 stateful set,一个用于我们的服务。最后结果是有 mongodb 容器的副本,stateful 存储和通过 pod 保留给数据存储的服务。我们继续看看,创建,按正确的顺序,因为有些操作是需要依赖前面创建的内容。
echo "shippy-infrastructure"
$ kubectl create -f ./deployments/mongodb-ssd.yml
$ kubectl create -f ./deployments/mongodb-deployment.yml
$ kubectl create -f ./deployments/mongodb-service.yml
等几分钟,你可以查下 mongodb 容器的状态,运行:
$ kubectl get pods
你可能注意到你的 pod 状态是'pending'。如果运行 $ kubectl describe node 你会看到关于 CPU 不足的错误。很尴尬,有些集群管理和 Kubernetes 工具对 CPU 很敏感。所以一台 node 可能不够,mongo 的实例也一样。
那么我们给集群打开自动扩容,默认是一个池。为了达到目的,需要到 Google Cloud Console,选择 Kubernetes 引擎,编辑你的实例,打开自动扩容,设置最小值和最大值为 2,然后点保存。
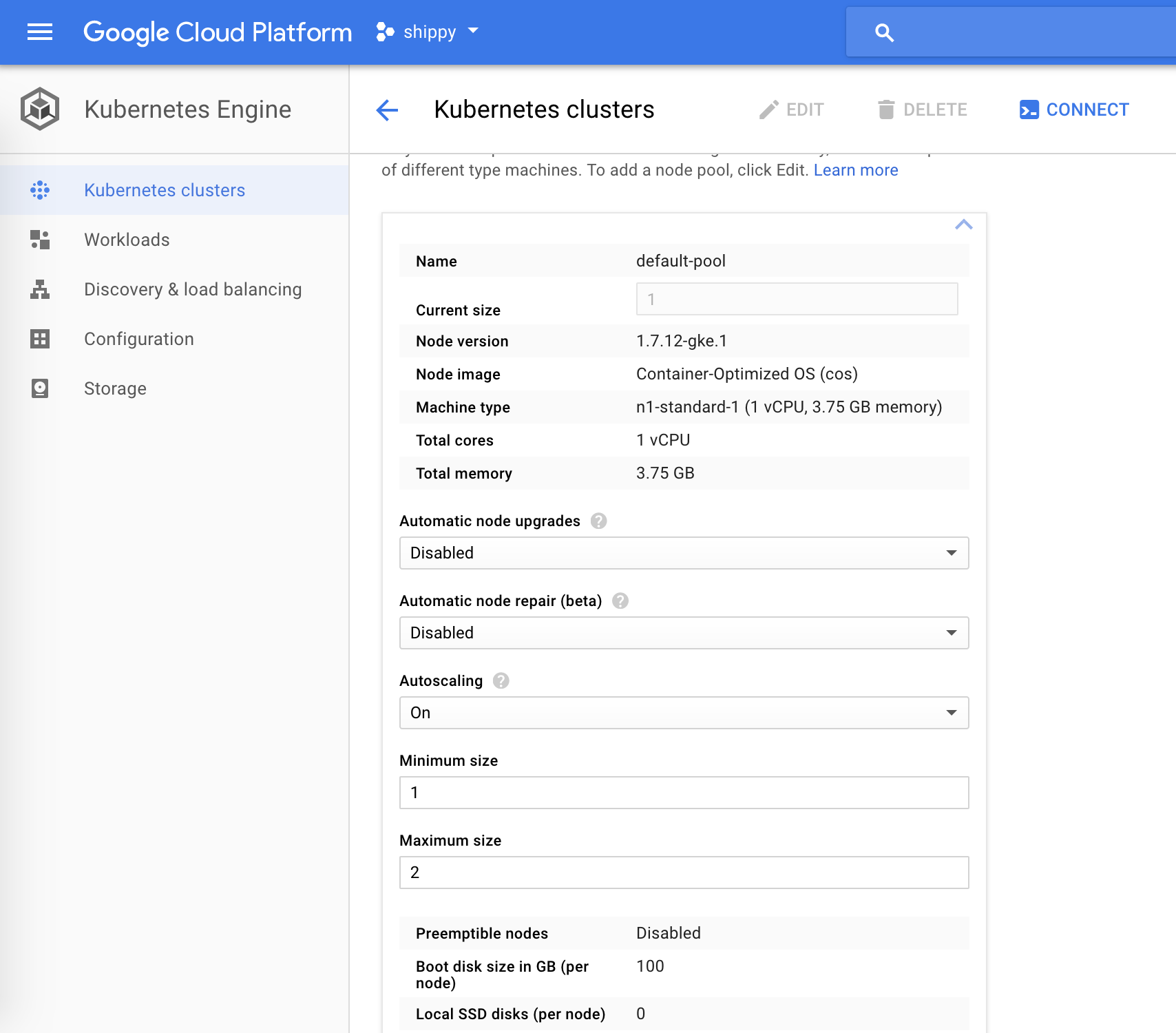
过几分钟,你的 node 节点会扩成两个,运行 $ kubectl get pods 你会看到 'ContainerCreating'。直到所有的容器以期待的方式运行。
现在我们有了数据库集群,一个自动扩容的 Kubernetes 引擎,我们来部署一些服务吧!
Vessel 服务
vessel 服务很轻量级,没做太多事情,也没有依赖,因此适合上手。
首先,我们稍微改动 vessel 服务上的一些代码片段。
// shippy-vessel-service/main.go
import (
...
k8s "github.com/micro/kubernetes/go/micro"
)
func main() {
...
// Replace existing service var with...
srv := k8s.NewService(
micro.Name("shippy.vessel"),
micro.Version("latest"),
)
}
我们在这做的所有事情,就是使用了 import 的新库 k8s.NewService 覆盖了已有的 micro.NewService()。那么新库是什么呢?
Kubernetes 中的微服务
我喜欢 micro 中的一点,因为它对 cloud 有很深理解而构建,能一直适应新技术。Micro 很重视 Kubernetes,因此创建了一个 micro 的 Kubernetes 库。
实际情况是,所有的库实际上都是 micro,配置了 Kuberntes 的一些合理的默认值,和一个直接集成在 Kubernetes 服务之上的 service selector。也就是说它把服务发现交给了 Kubernetes。默认用 gRPC 作为默认 transport 。 当然你也可以使用环境变量和 plugin 来覆盖这些状态。
在 Micro 的世界里还有很多让人着迷的功能,这也是让我很兴奋的地方。一定要加入 slack channel。
现在我们在服务上创建一个部署服务,在这我们要稍微了解下关于每个部分作用的细节。
// shippy-vessel-service/deployments/deployment.yml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: vessel
spec:
replicas: 1
selector:
matchLabels:
app: vessel
template:
metadata:
labels:
app: vessel
spec:
containers:
- name: vessel-service
image: eu.gcr.io/<project-name>/vessel-service:latest
imagePullPolicy: Always
command: [
"./shippy-vessel-service",
"--selector=static",
"--server_address=:8080",
]
env:
- name: DB_HOST
value: "mongo:27017"
- name: UPDATED_AT
value: "Mon 19 Mar 2018 12:05:58 GMT"
ports:
- containerPort: 8080
name: vessel-port
这有很多内容,不过我尝试分解下一部分。首先你能看到 kind:Deployment,在 Kubernetes 里有很多不同的 things,大部分可以被看作 'cloud primatives'。在编程语言里,string,interger,struct,method 等等这些类型都是元数据。在 Kubernetes 里就把 cloud 看作是同样意思。因此把这些看作元数据。这样,一个 deployment,就是控制元数据的一种形式。元控制保证你期望的状态维持正常。deployment 是一个无状态控制的形式,是不可持续的,在重启或退出之后数据就被销毁了。Stateful sets 类似 deployment,除了他们要维持一些静态数据,还有之前声明过的数据。但是我们的服务不应该包含任何状态,微服务是无状态的。因此在这我们需要一个 deployment。
下一步你需要一个标准分区,启动时带着 deployment 的 metadata,名称,多少个这种 pod (副本),需要保持(如果其中一个死掉了,假设我们用的比一个多,控制元的工作就是检查有运行的 pod 数量是我们希望的,如果不在期待状态就再启动一个)。Selector 和 template 暴露了 pod 的某些 metadata,可以允许其他服务发现和连接 pod。
然后你需要另一个标准分区(有点困惑,不过继续往下看呀!)。这次是给我们自己的容器,或者分卷,共享 meta 数据等等。在这个服务里,我们需要启动一个独立容器。容器区域是一个数组,因为我们要启动几个容器作为 pod 的一部分。是为了组合相关容器。
容器的 metadata 一目了然,我们从镜像启动一个 docker 容器,设置一些环境变量,在运行时传入一些命令,暴露一个端口(用于服务查找)。
你看到我传入了一个新的命令:--selector=static,这是告诉 Kubernetes 微服务设置使用 Kubernetes 用于服务发现和负载均衡。真的很酷,因为现在你的微服务代码是直接和 Kubernetes 强大的 DNS ,网络,负载均衡和服务发现进行交互。
你可以提交这个选项,继续像之前一样使用微服务。但是我们也可以用到 Kubernetes 的好处。
你也注意到了,我们从一个私有仓库拉取镜像。当使用 Google 的容器工具时,你可以获取一个容器注册,用来创建你的容器镜像,推送下,像下面这样...
$ docker build -t eu.gcr.io/<your-project-name>/vessel-service:latest .
$ gcloud docker -- push eu.gcr.io/<your-project-name>/vessel-service:latest
现在看我们的服务...
// shippy-vessel-service/deployments/service.yml
apiVersion: v1
kind: Service
metadata:
name: vessel
labels:
app: vessel
spec:
ports:
- port: 8080
protocol: TCP
selector:
app: vessel
在这里,如之前所说的我们有一个 kind,在这个 case 下是一个服务元(本质上是一组网络级别的 DNS 和防火墙规则)。然后我们给服务名字和标签。spec 允许我们给服务定义端口,你也可以在这定义一个 targetPort 来查找特定的容器。不过幸好有 Kubernetes/micro 实现,我们可以自动操作。最后,selector 最重要的部分,必须和你目标的 pod 相匹配,否则服务通过代理找不到任何东西,不会工作的。
现在我们部署下集群里的修改吧。
$ kubectl create -f ./deployments/deployment.yml
$ kubectl create -f ./deployments/service.yml
等几分钟,然后运行...
$ kubectl get pods
$ kubectl get services
你应该能看到你的新 pod,新服务了。确保他们的运行状态符合期待效果。
如果你遇到错误,你可以运行 $kubectl proxy,然后在浏览器打开 http://localhost:8001/ui ,看下 Kubernetes 的 ui,你可以深度探索下容器的状态等待。
在这有一点值得提一下,deployment 是原子操作并且是不可更改的,意思是他们必须通过某种方式更新才能被修改。他们有一个唯一的哈希值,如果哈希值没有变化,deployment 是不会更新的。
如果你运行 $ kubectl replace -f ./deployments/deployment.yml,什么也不会发生。因为 Kubernetes 没有检测到变化。
有很多方法可以规避这种情况,不过需要注意的是,大部分情况下,是你的容器会发生变化,所以不要用 latest 标签,你应该给每一个容器一个唯一的标签,比如编译编号,比如:vessel-service:。 这样就会标记为修改,deployment 就可以替换了。
但是在这个教程里,我们做点好玩的事,不过要留神,这是一种懒人写法,而且不是最好的实践方法。我创建了一个新文件 deployments/deployment.tmpl ,作为 deployment 的模板。然后我设置了一个环境变量 UPDATED_AT,值为 {{ UPDATED_AT }}。我更新了 Makefile 来打开模板文件,通过环境变量设置当前的 date/time ,然后输出到最终的 deployment.yml 文件。这有点不规范的感觉,不过只是暂时这么做。我看过很多方式,你感觉怎么合适怎么做吧。
// shippy-vessel-service/Makefile
deploy:
sed "s/{{ UPDATED_AT }}/$(shell date)/g" ./deployments/deployment.tmpl > ./deployments/deployment.yml
kubectl replace -f ./deployments/deployment.yml
好了,我们成功了,部署了一个服务,运行的和我们想的一样。
我现在给其他服务也做同样的操作。我在仓库里给每个服务做了简短的更新,如下...
Consignment service Email service User service Vessel service UI
给我们的用户服务部署 Postgres ...
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: postgres
selector:
matchLabels:
app: postgres
replicas: 3
template:
metadata:
labels:
app: postgres
role: postgres
spec:
terminationGracePeriodSeconds: 10
containers:
- name: postgres
image: postgres
ports:
- name: postgres
containerPort: 5432
volumeMounts:
- name: postgres-persistent-storage
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: postgres-persistent-storage
annotations:
volume.beta.kubernetes.io/storage-class: "fast"
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
Postgres 服务...
apiVersion: v1
kind: Service
metadata:
name: postgres
labels:
app: postgres
spec:
ports:
- name: postgres
port: 5432
targetPort: 5432
clusterIP: None
selector:
role: postgres
Postgres 存储...
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
部署 micro
// shippy-infrastructure/deployments/micro-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: micro
spec:
replicas: 3
selector:
matchLabels:
app: micro
template:
metadata:
labels:
app: micro
spec:
containers:
- name: micro
image: microhq/micro:kubernetes
args:
- "api"
- "--handler=rpc"
- "--namespace=shippy"
env:
- name: MICRO_API_ADDRESS
value: ":80"
ports:
- containerPort: 80
name: port
现在是服务...
// shippy-infrastructure/deployments/micro-service.yml
apiVersion: v1
kind: Service
metadata:
name: micro
spec:
type: LoadBalancer
ports:
- name: api-http
port: 80
targetPort: "port"
protocol: TCP
selector:
app: micro
在这些服务里,我们用了一个 LoadBalancer 类型,暴露了一个外部的 load balancer,提供给外部一个 IP 地址。如果你运行 $ kubectl get services,等一两分钟(你会看到 pending 一会),你就有了这个 ip 地址。这是公共部分的,你可以分配一个域名。
一旦部署完毕了,让服务调用 micro:
$ curl localhost/rpc -XPOST -d '{
"request": {
"name": "test",
"capacity": 200,
"max_weight": 100000,
"available": true
},
"method": "VesselService.Create",
"service": "vessel"
}' -H 'Content-Type: application/json'
你会看到一个返回 created: true。超简洁!这就是你的 gRPC 服务,被代理并且转成了 web 友好的格式,使用了分片的 mongodb 实例。没费多大劲!
部署 UI
服务部署的不错,我们来部署下用户接口
// shippy-ui/deployments/deployment.yml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: ui
spec:
replicas: 1
selector:
matchLabels:
app: ui
template:
metadata:
labels:
app: ui
spec:
containers:
- name: ui-service
image: ewanvalentine/ui:latest
imagePullPolicy: Always
env:
- name: UPDATED_AT
value: "Tue 20 Mar 2018 08:26:39 GMT"
ports:
- containerPort: 80
name: ui
现在是服务...
// shippy-ui/deployments/service.yml
apiVersion: v1
kind: Service
metadata:
name: ui
labels:
app: ui
spec:
type: LoadBalancer
ports:
- port: 80
protocol: TCP
targetPort: 'ui'
selector:
app: ui
注意到服务是 80 端口上的负载均衡,因为这是一个公共的用户接口,这就是用户如何与我们服务交互的。一看就明白!
最后总结
看我们成功了,用 docker 容器和 Kubernetes 管理我们的容器,成功的将整个工程部署到云端。希望你能从这篇文章发现一些有用的内容,没有觉得太不好消化。
本系列的下一部分,我们将看看把所有这些内容和 CI 进程联系起来,来管理我们的 deployment。
如果你觉得这个系列文章有用,如果你用了广告拦截(没怪你)。请考虑给我的辛苦劳动打个赏吧。共勉! https://monzo.me/ewanvalentine
或者,在 Patreon 上赞助我下吧。
via: https://ewanvalentine.io/microservices-in-golang-part-8/
作者:Ewan Valentine 译者:ArisAries 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




