
诊断和调试复杂系统是一件复杂的事。经常需要多个层次的诊断数据来弄清楚延迟问题可能的原因。
一个分布式系统由多个服务器组成,这些服务器互相依赖,共同完成对用户请求的服务。在任何时候,
- 系统中的一个进程可能会处理大量的请求。
- 在高并发的服务器中,没有容易的途径能将一个请求生命周期内的各个事件分离出来。
- 在高并发的服务器中,对于响应一个请求所发生的事件,我们没有很好的可见性。
随着 Go 在近些年来变成编写服务器的一门流行语言,我们意识到理解 Go 进程在一个请求的生命周期内发生了什么事的必要性。
在程序执行过程中会发生许多运行时活动:调度、内存分配、垃圾回收等等。但是要将用户代码与运行时事件关联起来,并帮助用户分析运行时事件如何影响他们的性能,这在过去是不可能的。
网站可靠工程师(SRE)可能会在诊断一个延迟问题时寻求帮助,并希望有人能帮助他们理解并优化一个特定的服务器。甚至对于那些精通 Go 的人来说,能够估计出运行时对于他们遇到的特定情况的影响,也是非常复杂的。
没有容易的方式能说明为什么某些请求延迟很高。分布式追踪让我们定位出哪个 handler 需要仔细查看,但我们需要深挖下去。是 GC,调度器还是 I/O 让我们在服务一个请求的时候等待如此之久? — SRE
在系统外部的人看来,经历延迟问题时,他们仅知道的一个事实就是自己等待了超出预期的时间(356ms)才收到响应,除此之外他们不知道别的。

用户使用 GET 方法访问 /messages 时等待了 356 ms 才收到响应。
从那些能够接触到分布追踪的开发者的角度来看,看到延迟的明细及每个服务对于总的延迟贡献了多少是有可能的。通过分布式追踪,我们对于境况有更好的可见性。
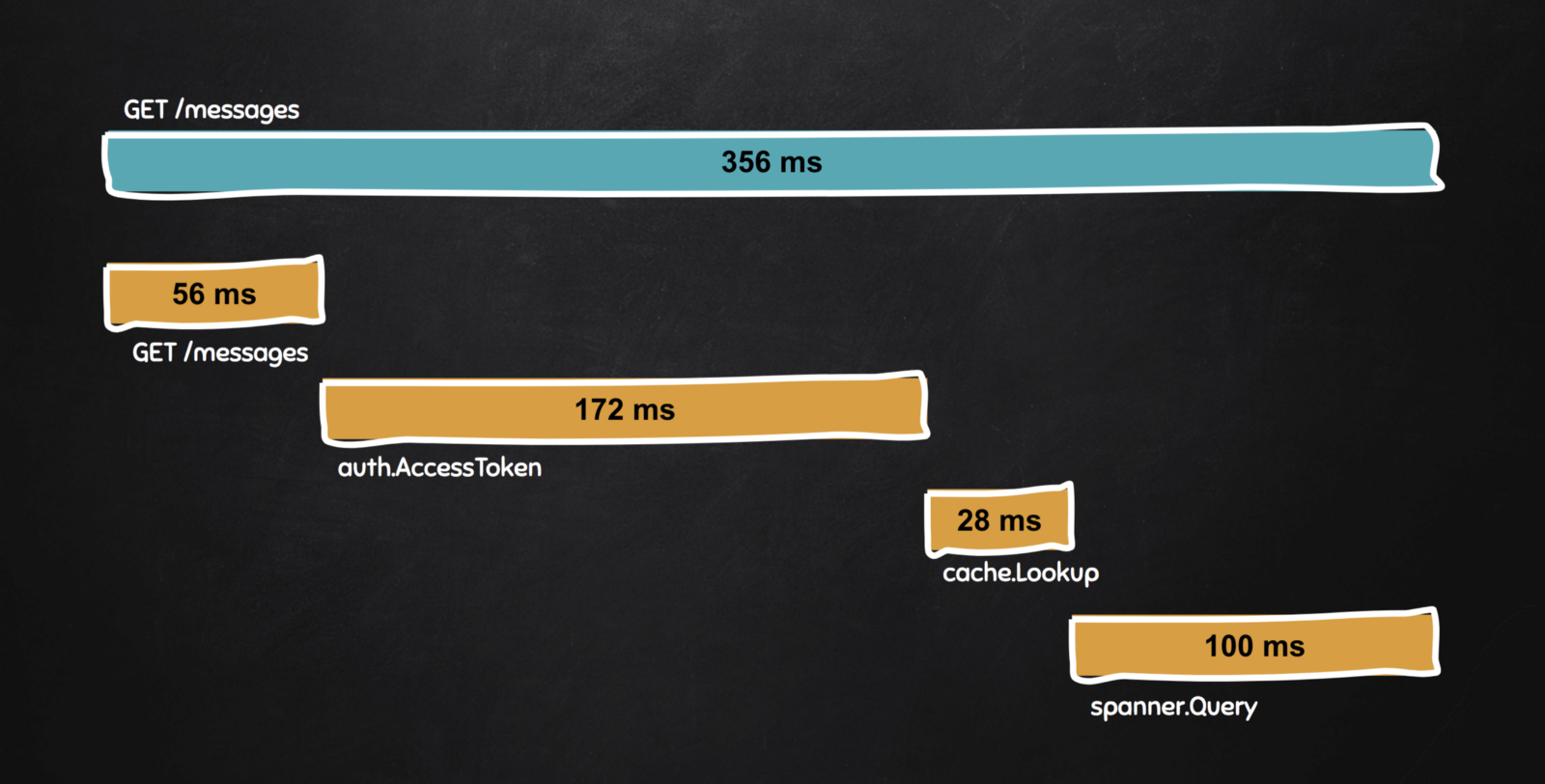
通过你收集到的分布式追踪来看延迟明细。
在这种情况下,为了服务 /messages, 我们写了三个内部的 RPC: auth.AccessToken, cache.Lookup 和 spanner.Query。我们可以看到每个 RPC 对延迟贡献了多少。这个时候,我们看出是 auth.AccessToken 花费了比平时长的时间。
我们成功的将问题缩小到一个特定的服务。我们可以通过关联特定的进程查看 auth.AccessToken 的源码,找到导致高延迟的代码,或者我们可以随意看看这个问题是否会在某个验证服务的实例上重现。
在 Go 1.11 下,我们将对执行追踪器有额外的支持,以便能指出 RPC 调用时的运行时事件。有了这个新特性,对于一个调用生命周期所发生的事,用户可以收集到更多的信息。
在这个案例中,我们将聚焦于 auth.AccessToken 范围内的部分。在网络上一共花费了 30 + 18 µs,阻塞的系统调用 5µs,垃圾回收 21µs,真正执行 handler 花费了 123µs,其中大部分都花在序列化和反序列化上。
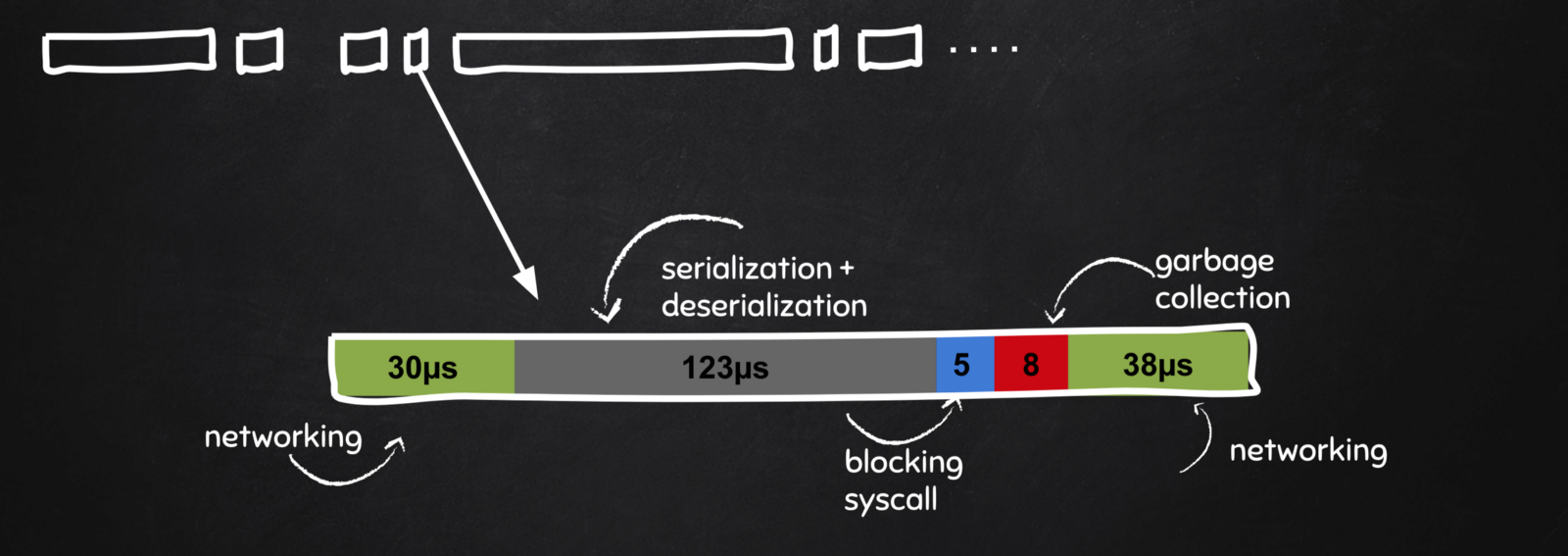
通过查看这一层次的详细信息,我们最终可以说我们很不幸的在 RPC 调用期间遇到了 GC,而且我们在序列化/反序列化上竟然花费了很长的时间。然后,工程师们就可以指出最近对于 auth.AccessToken 的消息进行的修改,从而改善性能问题。他们还可以看看垃圾回收是否经常会在关键路径上对这个请求的处理造成影响,对内存分配的方式进行优化。
Go 1.11
在 Go 1.11 下,Go 的执行追踪器将引入一些新的概念、API 及追踪特性:
- 用户事件及用户注解,参见 runtime/trace.
- 用户代码和运行时之间的关联。
- 执行追踪器与分布式追踪进行关联的可行性。
执行追踪器引入两个上层的概念:region 及 task,以便用户来对他们的代码进行插桩。
Region 是你希望收集追踪数据的代码区域。一个 region 开始和结束在同一个 goroutine 内。另一方面,task 是一个逻辑上的群组,将相关的 region 归在一起。一个 task 的开始和结束可以在不同的 goroutine 中。
我们预期用户为每个分布式追踪的 span 都启动一个执行追踪器,通过创建 region, 当问题发生时即刻启用执行追踪器,记录一些数据,分析输出,来对他们的 RPC 框架进行全面的插桩。
亲手进行测试
尽管这些新特性只能在 Go 1.11 中使用,你依然可以按照说明从源码安装。
我也推荐你在分布式追踪里试试。我最近在 Census 创建的 span 中增加了对执行追踪器中 task 的支持。
import (
"runtime/trace"
"go.opencensus.io/trace"
)
ctx, span := trace.StartSpan(ctx, "/messages")
defer span.End()
trace.WithRegion(ctx, "connection.init", conn.init)
如果你用的是 gRPC 或者 HTTP,那么你不需要手动创建 span,因为他们已经自动创建好了。在你的 handler 里面,你可以简单的对接收到的 context 使用 runtime/trace。
注册 pprof.Trace 的 handler,当你需要用执行追踪器的数据进行诊断时进行数据收集。
import _ "net/http/pprof"
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
如果你需要执行追踪器的数据,那就马上记录,并启动可视化工具:
$ curl http://server:6060/debug/pprof/trace?seconds=5 -o trace.out
$ go tool trace trace.out
2018/05/04 10:39:59 Parsing trace...
2018/05/04 10:39:59 Splitting trace...
2018/05/04 10:39:59 Opening browser. Trace viewer is listening on http://127.0.0.1:51803
接着你就可以在 /usertasks 看到由 helloworld.Greeter.SayHello 创建的执行追踪器任务的一个分布。
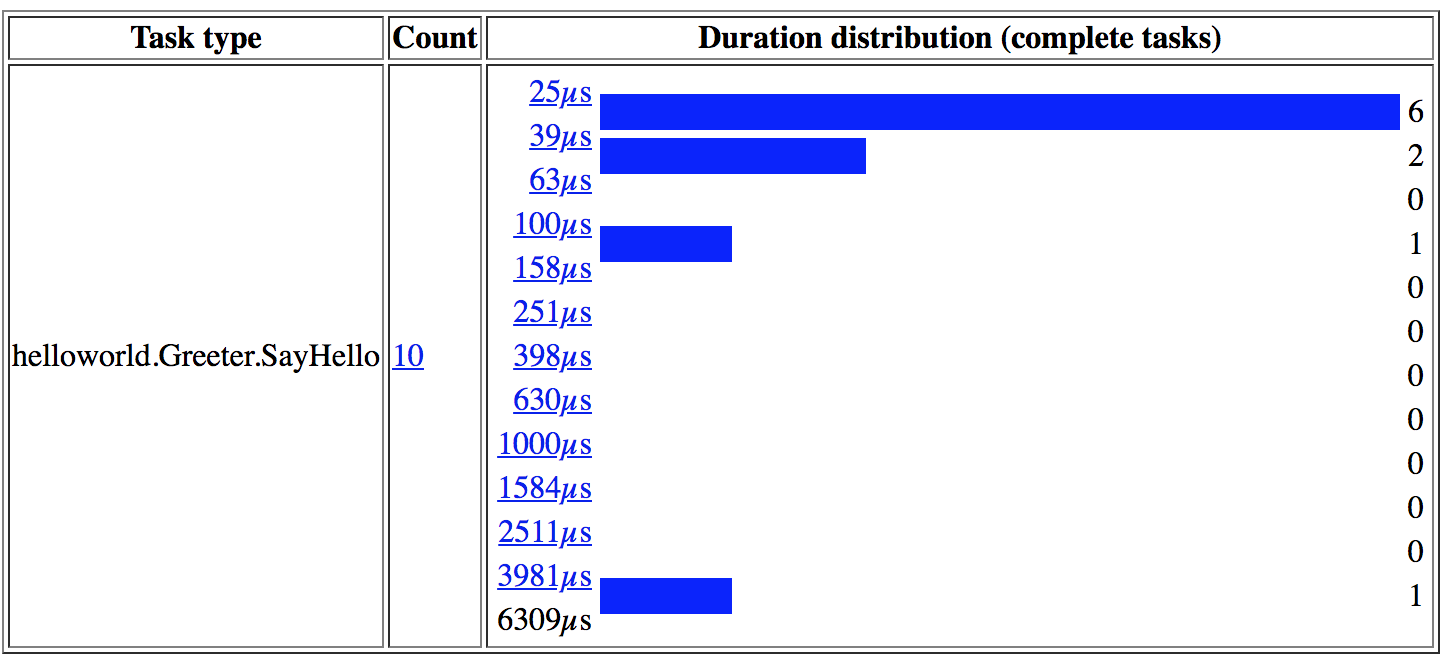
RPC task 的时间分布。
你可以点击 3981µs 的那个异常的 bucket,进一步分析在那个特定 RPC 的生命周期里发生了什么。
同时,/userregions 让你列出收集到的 region。你可以看到 connection.init 这个 region 以及所对应的多条记录。(注意到 connection.init 是为了演示而手动集成到 gRPC 框架的源码中的,更多的插桩工作还在进行中。)

region 的时间分布。
如果你点击了任意一个链接,它会给你更多关于处于那个延迟 bucket 中的 region 的详细信息。在下面的例子中,我们看到有一个 region 位于 1000µs 的 bucket。
 1000µs 的 region 在等待 GC 和调度器上花费了额外的时间。
1000µs 的 region 在等待 GC 和调度器上花费了额外的时间。
这样你就看到了细粒度的延迟明细。你可以看到 1309µs 的 region 交叠了垃圾回收。这以垃圾回收和调度的形式在关键路径上增加了不少开销。除此之外,执行 handler 与处理阻塞的系统调用花费了差不多的时间。
局限
尽管新的执行追踪器的特性很强大,但还是有一些局限。
- Region 只能在同一个 goroutine 中开始和结束。执行追踪器目前还不能自动记录跨越多个 goroutine 的数据。这就需要我们手动地插桩 region。下一个大的步伐将是在 RPC 框架及 net/http 这样的标准包里增加细粒度的插桩。
- 执行追踪器输出的格式比较难解析,
go tool trace是唯一的能理解这种格式的标准工具。并没有简单的方式能够自动将执行追踪器的数据与分布式追踪数据关联起来 - 所以我们分别搜集它们,之后再做关联。
结论
Go 正在努力成为强大的线上服务运行时。有了来自执行追踪器的数据,我们距离对线上服务器的高可见性近了一步,当问题出现时,能提供的可行数据也更多了。
via: https://medium.com/observability/debugging-latency-in-go-1-11-9f97a7910d68
作者:JBD 译者:krystollia 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




