
这篇文章基于我在日本东京 GoCon Spring 2018 上的演讲讨论了,Go 语言中的 map 是如何实现的。
什么是映射函数
要明白 map 是如何工作的的,我们需要先讨论一下 map 函数。一个 map 函数用以将一个值映射到另一个值。给定一个值,我们叫 key,它就会返回另外一个值,称为 value。
map(key) → value
现在,map 还没什么用,除非我们放入一些数据。我们需要一个函数来将数据添加到 map 中
insert(map, key, value)
和一个函数从 map 中移除数据
delete(map, key)
在实现上还有一些有趣的点比如查询某个 key 当前在 map 中是否存在,但这已经超出了我们今天要讨论的范围。相反我们今天只专注于这几个点;插入,删除和如何将 key 映射到 value。
Go 中的 map 是一个 hashmap
Hashmap 是我要讨论的的 map 的一种特定实现,因为这也是 Go runtime 中所采用的实现方式。Hashmap 是一种经典的数据结构,提供了平均 O(1) 的查询时间复杂度,即使在最糟的情况下也有 O(n) 的复杂度。也就是说,正常情况下,执行 map 函数的时间是个常量。
这个常量的大小部分取决于 hashmap 的设计方式,而 map 存取时间从 O(1) 到 O(n) 的变化则取决于它的 hash 函数。
hash 函数
什么是 hash 函数 ?一个 hash 函数用以接收一个未知长度的 key 然后返回一个固定长度的 value。
hash(key) → integer
这个 hash value 大多数情况下都是一个整数,原因我们后边会说到。
Hash 函数和映射函数是相似的。它们都接收一个 key 然后返回一个 value。然而 hash 函数的不同之处在于,它返回的 value 来源于 key,而不是关联于 key。
hash 函数的重要特点
很有必要讨论一下一个好的 hash 函数的特点,因为 hash 函数的质量决定了其 map 函数运行复杂度是否接近于 O(1)。
Hashmap 的使用方面有两个重要的特点。第一个是稳定性。Hash 函数必须是稳定的。给定相同的 key,你的 hash 函数必须返回相同的值。否则你无法查找到你放入 map 中的数据。
第二个特点是良好的分布。给定两个相类似的 key,结果应该是极其不同的。这很重要,因为有两点原因。第一,跟我们稍后会看到的一样,hashmap 中的 value 值应当均匀地分布于 buckets 之间,否则存取的复杂度不会是 O(1)。第二,由于用户一定程度上可以控制 hash 函数的输入,它们也就能控制 hash 函数的输出。这就会导致糟糕的分布,在某些语言中是 DDoS 攻击的一种方式。这项特点也被叫做 碰撞抵抗性(collision resistance)。
hashmap 的数据结构
关于 hashmap 的第二部分来说说数据是如何存储的。
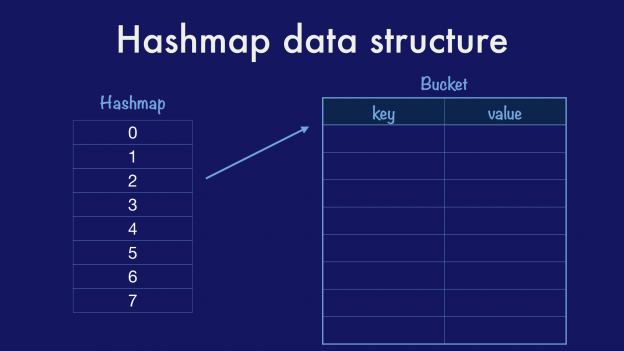
经典的 hashmap 结构是一个 bucket 数组,其中的每项包含一个指针指向一个 key/value entry 数组。在当前例子中我们的 hashmap 中有 8 个 bucket(Go 语言即如此实现),并且每个 bucket 最多持有 8 个 key/value entry(同样也是 Go 语言的实现)。使用 2 的次方便于做位掩码和移位,而不必做昂贵的除法操作。
因为 entry 被添加到 map 中,假定有一个良好分布的 hash 函数,那么 buckets 大致会被均匀地填充。一旦 bucket 中的 entry 数量超过总数的某个百分比,也就是所说的 负载因子(load factor),那么 map 就会翻倍 bucket 的数量并重新分配原先的 entry。
记住这个数据结构。假设我们现在有一个 map 用以存储项目名和对应的 Github star 数目,那么我们要如何往 map 中插入一个 value 呢?

我们从 key 开始,把它传入 hash 函数,然后做掩码操作只取最低的几位来获取到 bucket 数组正确位置的偏移量。这也是要放入的 entry 所在的 bucket,它的 hash 值以 3(二进制 011) 结束。最终我们遍历这个 bucket 的 entry 列表直到我们找到一个空的位置,然后插入我们的 key 和 value。如果 key 已经存在了,我们就覆盖 value。
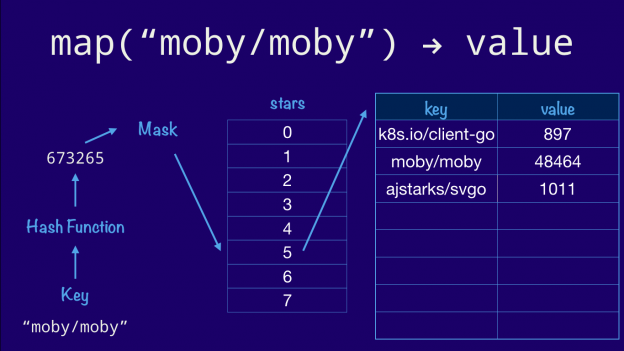
现在,我们仍然用这个示意图来从 map 中查找 value。过程很相似。我们先将 key 做 hash 操作。因为我们的 bucket 数组包含 8 个元素,所以我们取最低 3 位,也就是第 5 号 bucket (二进制 101)。如果我们的 hash 函数是正确的,那么字符串 "moby/moby" 做 hash 操作之后得到的值永远是相同的。所以我们知道 key 不会存在于其他 bucket 中。现在我们再从 bucket 的 entry 列表中通过比较 key 做一次线性查找就能得到结果了。
hashmap 的四个要点
这是个经典 hashmap 结构的比较高层的解释。我们已经看到了,要实现一个 hashmap 有四个要点;
- 你需要一个给 key 做计算的 hash 函数。
- 你需要一个判断 key 相等的算法。
- 你需要知道 key 的大小。
- 你需要知道 value 的大小,因为这同样影响了 bucket 结构的大小。编译器需要知道 bucket 结构的大小,这决定了当你遍历或者新增数据时内存中的步进值。
其他语言中的 hashmap
在讨论 Go 语言对于 hashmap 的实现之前,我想先简单介绍一下其他两个编程语言中是如何实现 hashmap 的。我选择了这两门语言,因为它们都提供了独立的 map 类型来适应各种不同的 key 和 value 类型。
C++
我们要讨论的第一个语言是 C++。C++ 标准模版库(STL)提供了 std::unordered_map 通常作为 hashmap 的实现来使用。
这是 std::unordered_map 的的定义。这是一个模版,所以参数实际的值取决于模版是如何初始化的。
template<
class Key, // the type of the key
class T, // the type of the value
class Hash = std::hash<Key>, // the hash function
class KeyEqual = std::equal_to<Key>, // the key equality function
class Allocator = std::allocator< std::pair<const Key, T> >
> class unordered_map;
可以讲的有很多,但比较重要的有以下几点:
- 模版接收了 key 和 value 的类型作为参数,所以知道它们的大小。
- 模版有一个 key 类型的
std::hash函数,所以它知道如何 hash 传给它的 key 值。 - 模版还有一个 key 类型的
std::equal_to函数,所以知道怎么比较两个 key 值。
现在我们知道了在 C++ 的 std::unordered_map 中 hashmap 的四个要点是如何传达给编译器的了,所以我们来看一下它是如何实际工作的。
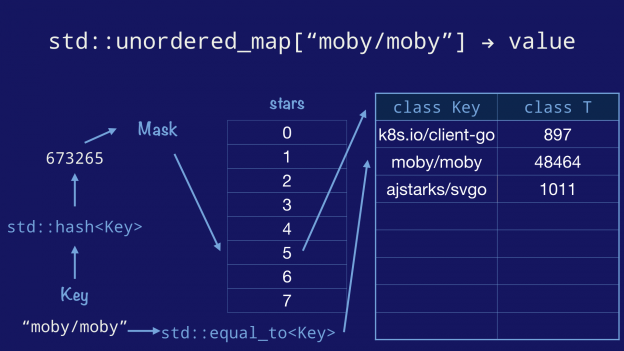
首先我们将 key 传给 std::hash 函数以得到 key 的 hash 值。然后做掩码并取到 bucket 数组中的序号,接着再遍历对应 bucket 的 entry 列表并用 std::equal_to 函数来比较 key。
Java
我们要讨论的第二个语言是 Java。不出所料,在 Java 中 hashmap 类型就叫做 java.util.Hashmap。
在 Java 中,java.util.Hashmap 只能操作对象,因为在 Java 中几乎所有的东西都是 java.lang.Object 的子类。由于在 Java 中所有对象都起源于 java.lang.Object,所以可以继承或者重写 hashCode 和 equals 方法。
然而你不能直接存储 8 个基本类型;boolean,int,short,long,byte,char,float 和 double,因为它们不是 java.lang.Object 的子类。你既不能将它们作为 key,也不能将它们作为 value 来存储。为了突破这种限制,它们会被隐式地转换为代表它们各自的对象。也叫做装箱。
先把这种限制放一边,让我们来看一下在 Java 的 hashmap 中查找是怎样的。
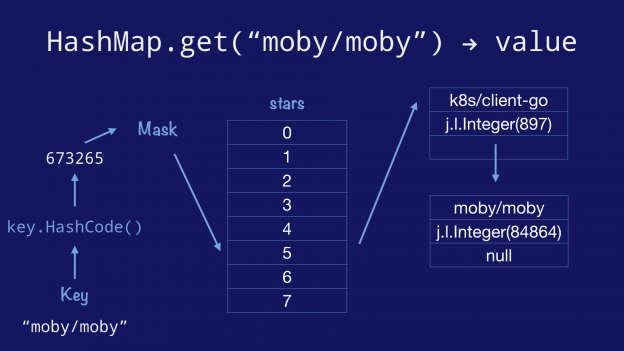
首先我们调用 key 的 hashCode 方法来获取它的 hash 值。然后做掩码操作,获取到 bucket 数组中的对应位置,里面存放了一个指向 Entry 的指针。Entry 中有一个 key,一个 value,还有一个指向下一个 Entry 的指针,形成了一个 linked list。
权衡
现在我们知道 C++ 和 Java 是如何实现 hashmap 的了,让我们来比较一下它们各自的优缺点。
C++ templated
std::unordered_map
优点
- key 和 value 类型的大小在编译期间就确定了。
- 数据结构的大小总是确定的,不需要装箱操作。
- 由于代码在编译期间就定下来了,所以其他编译优化操作例如内联,常数折叠和死代码删除就可以介入了。
总之,C++ 中的 map 和自己手写的为每种 key/value 类型组合定制的 map 一样快速高效,因为它其实就是这样的。
缺点
- 代码膨胀。每个不同的 map 都是不同类型的。如果你的代码中有 N 个 map 类型,在你的代码库中你也就需要有 N 份 map 代码的拷贝。
- 编译时间膨胀。由于头文件和模版的工作方式,每个使用了
std::unordered_map代码的文件中其实现都需要被生成,编译和优化。
Java util Hashmap
优点
- 一份 map 代码的实现可以服务于任何 java.util.Object 的子类。只需要编译一份 java.util.Object,在每个 class 文件中就都可以引用了。
缺点
- 所有东西必须是对象,即使它不是。这意味着基本类型的 map 必须用通过装箱操作转化为对象。装箱操作会增加垃圾回收的压力,并且额外的指针引用会增加缓存压力(每个对象都必须通过另外的指针来查找)。
- Buckets 是以 linked lists 而不是顺序数组的方式存储的。这会导致在对象比较期间产生大量的指针追踪操作。
- Hash 和 equals 函数需要代码编写者来实现。不正确的 hash 和 equals 函数会减慢 map 的运行速度,甚至导致 map 的行为错误。
Go 中 hashmap 的实现
现在,我们来讨论一下 Go 中 map 的实现。它保留了许多我们刚才讨论的实现中的优点,却没有那些缺点。
和 C++ 和 Java 一样, Go 中的 hashmap 是使用 Go 语言编写的。但是 Go 不支持范型,所以我们要如何来编写一个 hashmap 能够服务于(几乎)任何类型呢?
Go runtime 使用了 interface{} 吗?
不,Go runtime 并没有使用 interface{} 来实现 hashmap。虽然像 container/{list,heap} 这些包中使用了 interface{},但 runtime 的 map 却没有使用。
编译器是否使用了代码生成?
不,在 Go 语言可执行文件中只有一份 map 的实现。和 Java 不同,它并没有对 interface{} 做装箱操作。所以它是怎么工作的呢?
这要分成两部分来回答。它需要编译器和 runtime (运行时)之间的相互协作。
编译时间重写
第一部分我们需要先理解 runtime 包中对于 map 的实现是如何做查找,插入和删除操作的。在编译期间 map 的操作被重写去调用了 runtime。例如。
v := m["key"] → runtime.mapaccess1(m, "key", &v)
v, ok := m["key"] → runtime.mapaccess2(m, "key", &v, &ok)
m["key"] = 9001 → runtime.mapinsert(m, "key", 9001)
delete(m, "key") → runtime.mapdelete(m, "key")
值得注意的是,channel 中也做了相同的事,slice 却没有。
这是因为 channel 是复杂的数据类型。发送,接收和 select 操作和调度器之间都有复杂的交互,所以就被委托给了 runtime。相比较而言,slice 就简单很多了。像 slice 的存取,len 和 cap 这些操作编译器就自己做了,而像 copy 和 append 这种复杂的还是委托给了 runtime。
map 代码解释
现在我们知道编译器重写了 map 的操作去调用了 runtime。我们也知道了在 runtime 内部,有一个叫 mapaccess1 的函数,一个叫 mapaccess2 的函数等等。
所以,编译器是如何重写
v := m["key"]
到
runtime.mapaccess(m, "key", &v)
却没有使用 interface{} 的呢?要解释 Go 中的 map 类型是如何工作的最简单的函数是给你看一下 runtime.mapaccess1 的定义。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
让我们来过一下这些参数。
key是指向你提供的作为 key 值的指针。h是个指向runtime.hmap结构的指针。hmap是一个持有 buckets 和其他一些值的 runtime 的 hashmap 结构。t是个指向maptype的指针。
为什么我们已经有了 *hmap 之后还需要一个 *maptype?*maptype 是个特殊的东西,使得通用的 *hmap 可以服务于(几乎)任意 key 和 value 类型的组合。在你的程序中对于每一个独立的 map 定义都会有一个特定的 maptype 值。例如,有一个 maptype 值描述了从 strings 到 ints 的映射,另一个描述了 strings 到 http.Headers 的映射,等等。
C++ 中,对于每一个独立的 map 定义都有一个完整的实现。而 Go 并非如此,它在编译期间创建了一个 maptype 并在调用 runtime 的 map 函数的时候使用了它。
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
hmap *_type // internal type representing a hmap
keysize uint8 // size of key slot
indirectkey bool // store ptr to key instead of key itself
valuesize uint8 // size of value slot
indirectvalue bool // store ptr to value instead of value itself
bucketsize uint16 // size of bucket
reflexivekey bool // true if k==k for all keys
needkeyupdate bool // true if we need to update key on overwrite
}
每个 maptype 中都包含了特定 map 中从 key 映射到 elem 所需的各种属性细节。它包含了关于 key 和 element 的信息。maptype.key 包含了指向我们传入的 key 的指针的信息。我们称之为 类型描述符。
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
在 _type 类型中,包含了它的大小。这很重要,因为我们只有一个指向 key 的指针,而不知道它实际多大并且是什么类型。它到底是一个整数,还是一个结构体,等等。我们也需要知道如何比较这种类型的值和如何 hash 这种类型的值,这也就是 _type.alg 字段的意义所在。
type typeAlg struct {
// function for hashing objects of this type
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}
在你的程序中这就是一个服务于特定类型的 typeAlg 值。
放在一起来看,这就是(轻微修改,便于理解) runtime.mapaccess1 函数。
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
// it will return a reference to the zero object for the value type if
// the key is not in the map.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
值得关注的一点是传递给 alg.hash 函数的 h.hash0 参数。h.hash0 是一个在 map 创建时生成的随机种子,为了防止在 Go runtime 中产生 hash 碰撞。
任何人都可以阅读 Go 语言的源码,所以可以找到一系列值,使得其使用 Go 语言中的 hash 函数计算后,得到的 hash 值会被放入同一个 bucket 中。种子的存在就为 hash 函数增加了很多随机性,为碰撞攻击提供了一些保护措施。
结论
我很高兴能在 GoCon 大会上做这个演讲。因为 Go 中的 map 实现是一个介于 C++ 和 Java 之间的权衡,汲取了很多优点同时又没有包含很多缺点。
和 Java 不同,你可以直接使用基本类型数据,例如字符和整数,而不需要进行装箱操作。和 C++ 不同,在最后的二进制文件中,没有 N 份 runtime.hashmap 的实现,只有 N 份 runtime.maptype 的值,显著减少了程序的体积和编译时间。
现在我想说明的是我不是在试图告诉你 Go 不应该支持范型。我今天的目的是阐述当前 Go 1 的现状和在当前情形下 map 类型的工作方式。现今 Go 语言下 map 的实现是非常高效的,提供了很多模版类型的优点,而没有代码生成和编译时间膨胀的缺点。
我视之为一次值得学习赞赏的设计案例。
- 你可以在这里找到更多关于 runtime.hmap 结构的内容。https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
via: https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics
作者:Dave Cheney 译者:alfred-zhong 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




