
这篇博客是我在维尔纽斯的 Go Meetup 演讲的总结。如果你在维尔纽斯并且喜欢 Go 语言,欢迎加入我们并考虑作演讲
在这篇博文中我们将要探索 Go 语言的内存管理,首先让我们来思考以下的这个小程序:
func main() {
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %q", html.EscapeString(r.URL.Path))
})
http.ListenAndServe(":8080", nil)
}
编译并且运行:
go build main.go
./main
接着我们通过 ps 命令观察这个正在运行的程序:
ps -u --pid 16609
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
povilasv 16609 0.0 0.0 388496 5236 pts/9 Sl+ 17:21 0:00 ./main
我们发现,这个程序居然耗掉了 379.39M 虚拟内存,实际使用内存为 5.11M。这有点儿夸张吧,为什么会用掉 380M 虚拟内存?
一点小提示:
虚拟内存大小(VSZ)是进程可以访问的所有内存,包括换出的内存、分配但未使用的内存和共享库中的内存。(stackoverflow 上有很好的解释。)
驻留集大小(RSS)是进程在实际内存中的内存页数乘以内存页大小,这里不包括换出的内存页(译者注:包含共享库占用的内存)。
在深入研究这个问题之前,让我们先介绍一些计算机架构和内存管理的基础知识。
内存的基本知识
维基百科对 RAM 的定义如下:
随机访问存储器(RAM /ræm/)是一种计算机存储设备,用于存储当前被使用的数据和机器码。 随机访问内存设备允许在几乎相同的时间内读取或写入数据项,而不管数据在内存中的物理位置如何。
我们可以将物理内存看作是一个槽/单元的数组,其中槽可以容纳 8 个位信息1。每个内存槽都有一个地址,在你的程序中你会告诉 CPU:“喂,CPU,你能在地址 0 处的内存中取出那个字节的信息吗?”,或者“喂,CPU,你能把这个字节的信息放在内存为地址 1 的地方吗?”。
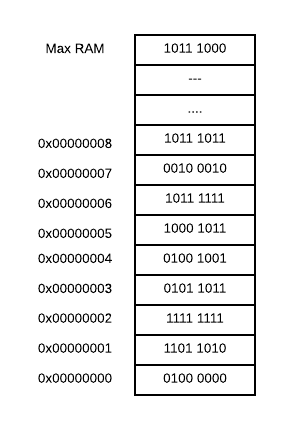
由于计算机通常要运行多个任务,所以直接从物理内存中读写是并不明智。想象一下,编写一个程序是一个很容易的事情,它会从内存中读取所有的东西(包括你的密码),或者编写一个程序,它会在不同的程序的内存地址中写入内容。那将是很荒唐的事情。
因此,除了使用实际物理内存去处理任务我们还有虚拟内存的概念。当你的程序运行时,它只看到它的内存,它认为它独占了内存2。另外,程序中存储的内存字节也不可能都放在 RAM 中。如果不经常访问特定的内存块,操作系统可能会将一些内存块放入较慢的存储空间(比如磁盘),从而节省宝贵的 RAM。操作系统甚至不会承认对你的程序是这样操作的,但实际上,我们知道操作系统确实是那样运作的。
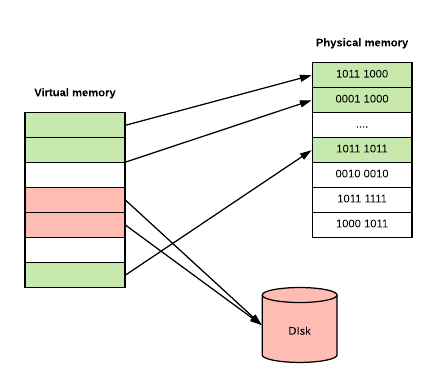
虚拟内存可以使用基于CPU体系结构和操作系统的段或页表来实现。我不会详细讲段,因为页表更常见,但你可以在附录3中读到更多关于段的内容。
在分页虚拟内存中,我们将虚拟内存划分为块,称为页。页的大小可以根据硬件的不同而有所不同,但是页的大小通常是 4-64 KB,此外,通常还能够使用从 2MB 到 1GB 的巨大的页。分块很有用,因为单独管理每个内存槽需要更多的内存,而且会降低计算机的性能。
为了实现分页虚拟内存,计算机通常有一个称为内存管理单元(MMU)4的芯片,它位于 CPU 和内存之间。MMU 在一个名为页表的表(它存储在内存中)中保存了从虚拟地址到物理地址的映射,其中每页包含一个页表项(PTE)。MMU 还有一个物理缓存旁路转换缓冲(TLB),用来存储最近从虚拟内存到物理内存的转换。大致是这样的:
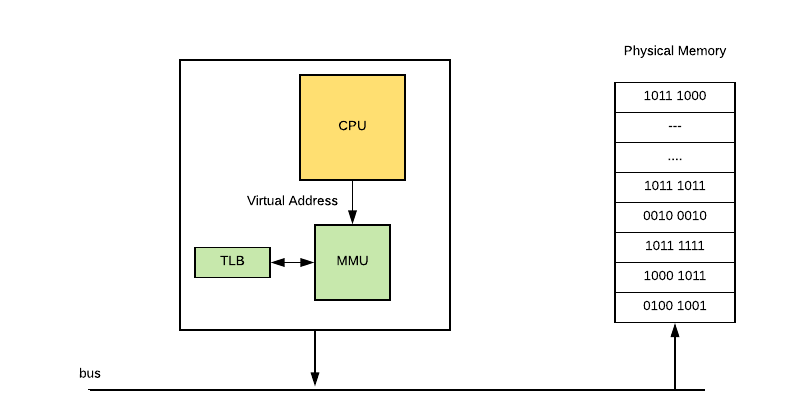
因此,假设操作系统决定将一些虚拟内存页放入磁盘,程序会尝试访问它。 此过程如下所示:
- CPU 发出访问虚拟地址的命令,MMU 在其页面表中检查它并禁止访问,因为没有为该虚拟页面分配物理 RAM。
- 然后 MMU 向 CPU 发送页错误。
- 然后,操作系统通过查找 RAM 的备用内存块(称为帧)并设置新的 PTE 来映射它来处理页错误。
- 如果没有RAM是空闲的,它可以使用一些替换算法选择现有页面,并将其保存到磁盘(此过程称为分页)。
- 对于一些内存管理单元,还可能出现页表入口不足的情况,在这种情况下,操作系统必须为新的映射释放一个表入口。
操作系统通常管理多个应用程序(进程),因此整个内存管理位如下所示:
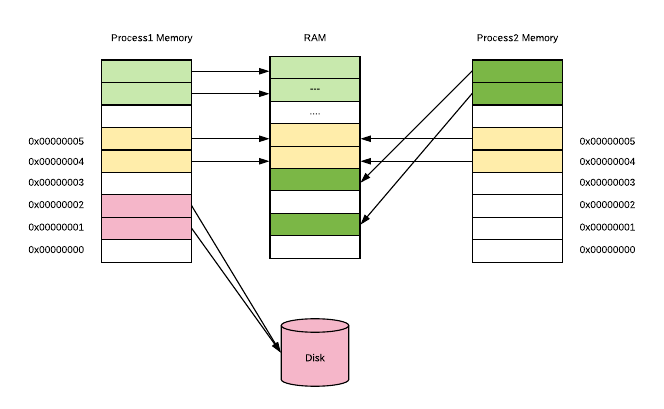
每个进程都有一个线性虚拟地址空间,地址从 0 到最大值。虚拟地址空间不需要是连续的,因此并非所有这些虚拟地址实际上都用于存储数据,并且它们不占用RAM或磁盘中的空间。很酷的一点是,真实内存的同一帧可以支持属于多个进程的多个虚拟页面。通常就是这种情况,虚拟内存占用 GNU C 库代码(libc),如果使用 go build 进行编译,则默认包含该代码。你可以通过添加 ldflags 参数来设置编译时不带 libc 的代码5:
go build -ldflags '-libgcc=none'
以上叙述是关于什么是内存,以及如何使用硬件和操作系统相互通信来实现内存的概述。现在让我们看看在操作系统中发生了什么,当你尝试运行你的程序时,程序将如何分配内存。
操作系统相关
为了运行程序,操作系统有一个模块,它负责加载程序和所需要的库,称为程序加载器。在 linux 系统中,你可以通过 execve() 系统调用来调用你的程序加载器。
当加载程序运行时,它会进行一下步骤6:
- 验证程序映像(权限、内存需求等);
- 将程序映像从磁盘复制到主存储器中;
- 传递堆栈上的命令行参数;
- 初始化寄存器(如栈指针);
加载完成后,操作系统通过将控制权传递给加载的程序代码来启动程序(执行跳转指令到程序的入口点(_start))。
那么什么是程序呢?
我们通常用 Go 语言等高级语言编写程序,这些语言被编译成可执行的机器代码文件或不可执行的机器代码目标文件(库)。 这些可执行或不可执行的目标文件通常采用容器格式,例如可执行文件和可链接格式(ELF)(通常在 Linux 中),可执行文件(通常在Windows 中)。但有时候,你并不能用你喜欢的 Go 语言来编写所有程序。在这种情况下,一种选择是手工制作你自己的 ELF 二进制文件并将机器代码放入正确的 ELF 结构中。另一种选择是用汇编语言开发一个程序,该程序在与机器代码指令更紧密地联系,同时仍然是便于人们阅读的。
目标文件是直接在处理器上执行的程序的二进制表示。这些目标文件不仅包含机器代码,还包含有关应用程序的元数据,如操作系统体系结构,调试信息。目标文件还携带应用程序数据,如全局变量或常量。 通常,目标文件由以下段(section)组成,如:.text(可执行代码),.data(全局变量) 和 .rodata(全局常量) 等7。
我在 linux(Ubuntu) 系统上把程序编译成可执行和可链接形式的文件(也就是执行 go build 命令后的输出文件)8。在 Go 语言中,我们可以轻松编写一个读取 ELF 可执行文件的程序,因为 Go 语言在标准库中有一个 debug/elf 包。以下是一个例子:
package main
import (
"debug/elf"
"log"
)
func main() {
f, err := elf.Open("main")
if err != nil {
log.Fatal(err)
}
for _, section := range f.Sections {
log.Println(section)
}
}
输出如下:
2018/05/06 14:26:08 &{{ SHT_NULL 0x0 0 0 0 0 0 0 0 0} 0xc4200803f0 0xc4200803f0 0 0}
2018/05/06 14:26:08 &{{.text SHT_PROGBITS SHF_ALLOC+SHF_EXECINSTR 4198400 4096 3373637 0 0 16 0 3373637} 0xc420080420 0xc420080420 0 0}
2018/05/06 14:26:08 &{{.plt SHT_PROGBITS SHF_ALLOC+SHF_EXECINSTR 7572064 3377760 560 0 0 16 16 560} 0xc420080450 0xc420080450 0 0}
2018/05/06 14:26:08 &{{.rodata SHT_PROGBITS SHF_ALLOC 7573504 3379200 1227675 0 0 32 0 1227675} 0xc420080480 0xc420080480 0 0}
2018/05/06 14:26:08 &{{.rela SHT_RELA SHF_ALLOC 8801184 4606880 24 11 0 8 24 24} 0xc4200804b0 0xc4200804b0 0 0}
2018/05/06 14:26:08 &{{.rela.plt SHT_RELA SHF_ALLOC 8801208 4606904 816 11 2 8 24 816} 0xc4200804e0 0xc4200804e0 0 0}
2018/05/06 14:26:08 &{{.gnu.version SHT_GNU_VERSYM SHF_ALLOC 8802048 4607744 78 11 0 2 2 78} 0xc420080510 0xc420080510 0 0}
2018/05/06 14:26:08 &{{.gnu.version_r SHT_GNU_VERNEED SHF_ALLOC 8802144 4607840 112 10 2 8 0 112} 0xc420080540 0xc420080540 0 0}
2018/05/06 14:26:08 &{{.hash SHT_HASH SHF_ALLOC 8802272 4607968 192 11 0 8 4 192} 0xc420080570 0xc420080570 0 0}
2018/05/06 14:26:08 &{{.shstrtab SHT_STRTAB 0x0 0 4608160 375 0 0 1 0 375} 0xc4200805a0 0xc4200805a0 0 0}
2018/05/06 14:26:08 &{{.dynstr SHT_STRTAB SHF_ALLOC 8802848 4608544 594 0 0 1 0 594} 0xc4200805d0 0xc4200805d0 0 0}
2018/05/06 14:26:08 &{{.dynsym SHT_DYNSYM SHF_ALLOC 8803456 4609152 936 10 0 8 24 936} 0xc420080600 0xc420080600 0 0}
2018/05/06 14:26:08 &{{.typelink SHT_PROGBITS SHF_ALLOC 8804416 4610112 12904 0 0 32 0 12904} 0xc420080630 0xc420080630 0 0}
2018/05/06 14:26:08 &{{.itablink SHT_PROGBITS SHF_ALLOC 8817320 4623016 3176 0 0 8 0 3176} 0xc420080660 0xc420080660 0 0}
2018/05/06 14:26:08 &{{.gosymtab SHT_PROGBITS SHF_ALLOC 8820496 4626192 0 0 0 1 0 0} 0xc420080690 0xc420080690 0 0}
2018/05/06 14:26:08 &{{.gopclntab SHT_PROGBITS SHF_ALLOC 8820512 4626208 1694491 0 0 32 0 1694491} 0xc4200806c0 0xc4200806c0 0 0}
2018/05/06 14:26:08 &{{.got.plt SHT_PROGBITS SHF_WRITE+SHF_ALLOC 10518528 6324224 296 0 0 8 8 296} 0xc4200806f0 0xc4200806f0 0 0}
...
2018/05/06 14:26:08 &{{.dynamic SHT_DYNAMIC SHF_WRITE+SHF_ALLOC 10518848 6324544 304 10 0 8 16 304} 0xc420080720 0xc420080720 0 0}
2018/05/06 14:26:08 &{{.got SHT_PROGBITS SHF_WRITE+SHF_ALLOC 10519152 6324848 8 0 0 8 8 8} 0xc420080750 0xc420080750 0 0}
2018/05/06 14:26:08 &{{.noptrdata SHT_PROGBITS SHF_WRITE+SHF_ALLOC 10519168 6324864 183489 0 0 32 0 183489} 0xc420080780 0xc420080780 0 0}
2018/05/06 14:26:08 &{{.data SHT_PROGBITS SHF_WRITE+SHF_ALLOC 10702688 6508384 46736 0 0 32 0 46736} 0xc4200807b0 0xc4200807b0 0 0}
2018/05/06 14:26:08 &{{.bss SHT_NOBITS SHF_WRITE+SHF_ALLOC 10749440 6555136 127016 0 0 32 0 127016} 0xc4200807e0 0xc4200807e0 0 0}
2018/05/06 14:26:08 &{{.noptrbss SHT_NOBITS SHF_WRITE+SHF_ALLOC 10876480 6682176 12984 0 0 32 0 12984} 0xc420080810 0xc420080810 0 0}
2018/05/06 14:26:08 &{{.tbss SHT_NOBITS SHF_WRITE+SHF_ALLOC+SHF_TLS 0 0 8 0 0 8 0 8} 0xc420080840 0xc420080840 0 0}
2018/05/06 14:26:08 &{{.debug_abbrev SHT_PROGBITS 0x0 10891264 6557696 437 0 0 1 0 437} 0xc420080870 0xc420080870 0 0}
2018/05/06 14:26:08 &{{.debug_line SHT_PROGBITS 0x0 10891701 6558133 350698 0 0 1 0 350698} 0xc4200808a0 0xc4200808a0 0 0}
2018/05/06 14:26:08 &{{.debug_frame SHT_PROGBITS 0x0 11242399 6908831 381068 0 0 1 0 381068} 0xc4200808d0 0xc4200808d0 0 0}
2018/05/06 14:26:08 &{{.debug_pubnames SHT_PROGBITS 0x0 11623467 7289899 121435 0 0 1 0 121435} 0xc420080900 0xc420080900 0 0}
2018/05/06 14:26:08 &{{.debug_pubtypes SHT_PROGBITS 0x0 11744902 7411334 225106 0 0 1 0 225106} 0xc420080930 0xc420080930 0 0}
2018/05/06 14:26:08 &{{.debug_gdb_scripts SHT_PROGBITS 0x0 11970008 7636440 53 0 0 1 0 53} 0xc420080960 0xc420080960 0 0}
2018/05/06 14:26:08 &{{.debug_info SHT_PROGBITS 0x0 11970061 7636493 1847750 0 0 1 0 1847750} 0xc420080990 0xc420080990 0 0}
2018/05/06 14:26:08 &{{.debug_ranges SHT_PROGBITS 0x0 13817811 9484243 167568 0 0 1 0 167568} 0xc4200809c0 0xc4200809c0 0 0}
2018/05/06 14:26:08 &{{.interp SHT_PROGBITS SHF_ALLOC 4198372 4068 28 0 0 1 0 28} 0xc4200809f0 0xc4200809f0 0 0}
2018/05/06 14:26:08 &{{.note.go.buildid SHT_NOTE SHF_ALLOC 4198272 3968 100 0 0 4 0 100} 0xc420080a20 0xc420080a20 0 0}
2018/05/06 14:26:08 &{{.symtab SHT_SYMTAB 0x0 0 9654272 290112 35 377 8 24 290112} 0xc420080a50 0xc420080a50 0 0}
2018/05/06 14:26:08 &{{.strtab SHT_STRTAB 0x0 0 9944384 446735 0 0 1 0 446735} 0xc420080a80 0xc420080a80 0 0}
你也可以通过一些 linux 工具来查看 ELF 文件信息,如: size --format=sysv main 或 readelf -l main(这里的 main 是指输出的二进制文件)。
显而易见,可执行文件只是具有某种预定义格式的文件。通常,可执行格式具有段,这些段是在运行映像之前映射的数据内存。下面是 segment 的一个常见视图,流程如下:
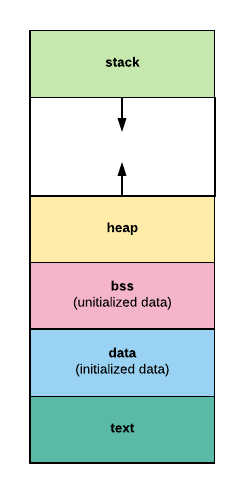
文本段包含程序指令、字面量和静态常量。
数据段是程序的工作存储器。它可以由 exec 预分配和预加载,进程可以扩展或收缩它。
堆栈段包含一个程序堆栈。它随着堆栈的增长而增长,但是当堆栈收缩时它不会收缩。
堆区域通常从 .bss 和 .data 段的末尾开始,并从那里增长到更大的地址。
我们来看看进程如何分配内存。
Libc 手册解释是9,程序可以使用 exec 系列函数和编程方式以两种主要方式进行分配。exec 调用程序加载器来启动程序,从而为进程创建虚拟地址空间,将程序加载进内存并运行它。常用的编程方式有:
- 静态分配是在声明全局变量时发生的事情。每个全局变量定义一个固定大小的空间块。当你的程序启动时(exec 操作的一部分),该空间被分配一次,并且永远不会被释放。
- 自动分配 - 声明自动变量(例如函数参数或局部变量)时会发生自动分配。输入包含声明的复合语句时会分配自动变量的空间,并在退出该复合语句时释放。
- 动态分配 - 是一种程序确定它们在哪里运行,并存储某些信息的技术。当你需要的内存量或你需要多长时间时,你需要动态分配,这取决于程序运行之前未知的因素。
要动态分配内存,你有几个选择。其中一个选项是调用操作系统(syscall 或通过 libc)。操作系统提供各种功能,如:
mmap/munmap- 分配/解除分配固定块内存页面。brk/sbrk- 更改/获取数据分段大小。madvise- 提供操作系统如何管理内存的建议。set_thread_area/get_thread_area- 适用于线程本地存储。
我认为 Go 语言的运行时只使用 mmap、 madvise、 munmap 与 sbrk,并且它们都是在操作系统下通过汇编或者 cgo 直接调用的,也就是说它不会调用 libc10。这些内存分配是低级别的,通常程序员不使用它们。更常见的是使用 libc 的 malloc 系列函数,当你向系统申请 n 个字节的内存时,libc 将为你分配内存。同时,你不需要这些内存的时候,要调用 free 来释放这些内存。
以下是一个 C 语言使用 malloc 函数的基础示例:
#include /* printf, scanf, NULL */
#include /* malloc, free, rand */
int main (){
int i,n;
char * buffer;
printf ("How long do you want the string? ");
scanf ("%d", &i);
buffer = (char*) malloc (i+1);
if (buffer==NULL) exit (1);
for (n=0; n<i; n++)
buffer[n]=rand()%26+'a';
buffer[i]='\0';
printf ("Random string: %s\n",buffer);
free (buffer);
return 0;
}
这个例子说明了动态分配数据的需要,因为我们要求用户输入字符串长度,然后根据它分配字节并生成随机字符串。另外,请注意对 free() 的显式调用。
内存分配器
由于 Go 语言不使用 malloc 来获取内存,而是直接操作系统申请(通过 mmap),它必须自己实现内存分配和释放(就像 malloc 一样)。 Go 语言的内存分配器最初基于 TCMalloc:Thread-Caching Malloc。
以下是一些关于 TCMalloc 的有趣事实:
- TCMalloc 比 glibc 2.3 malloc 更快(作为一个名为
ptmalloc2的独立库提供)。 - ptmalloc2 执行 malloc 需要大约 300 纳秒。
- 对于相同的操作对,TCMalloc 实现大约需要 50 纳秒。
TCMalloc 还减少了多线程程序的锁争用:
- 对于小型对象,几乎没有争用。
- 对于大型对象,TCMalloc 尝试使用细粒度和高效的自旋锁。
TCMalloc
TCMalloc 性能背后的秘密在于它使用线程本地缓存来存储一些预先分配的内存“对象”,以便从线程本地缓存11中满足小分配。一旦线程本地缓存耗尽空间,内存对象就会从中心数据结构移动到线程本地缓存。
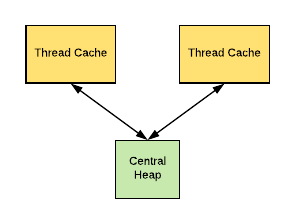
TCMalloc 对小对象(大小 <= 32K)分配的处理与大对象不同。使用页级分配器直接从中心堆分配大型对象。同时,小对象被映射到大约 170 个可分配大小类中的一个。
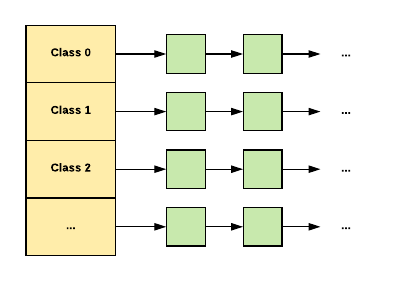
以下是它如何适用于小对象:
当给一个小对象分配内存时:
- 我们将其大小映射到相应的大小等级。
- 查看当前线程的线程缓存中的相应空闲列表。
- 如果空闲列表不为空,我们从列表中删除第一个对象并将其返回。
如果没有空闲列表:
- 我们从这个 size-class 的中心空闲列表中获取一些对象(中心空闲列表由所有线程共享)。
- 将它们放在线程本地空闲列表中。
- 将一个新获取的对象返回给应用程序。
如果中心空闲列表也是空的:
- 我们从中央页面分配器分配了一系列页面。
- 将 run 分解为这个 size-class 的一组对象。
- 将新对象放在中央自由列表中。
- 与前面一样,将这些对象中的一些移动到线程本地自由列表中。
大对象(大小为 > 32K)四舍五入到一个页面大小(4K),由一个中心页面堆处理。中心页面堆又是一个自由列表数组:
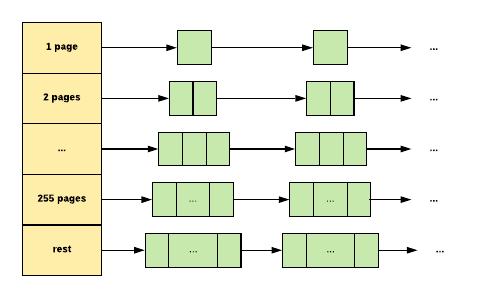
对于 i < 256,第 k 个项是由 k 个页组成的运行的空闲列表。第256项是长度 > = 256 页的运行的空闲列表。
以下描述了它如何适用于大型对象的:
满足 k 页的分配:
- 我们查看k-th列表。
- 如果这个空闲列表是空的,我们会查看下一个空闲列表,等等。
- 所示。最后,如果有必要,我们会查看最后一个免费列表。
- 所示。如果失败,我们将从系统中获取内存。
- 如果对k个页面的分配通过运行长度为> k的页面来满足,则运行的其余部分将重新插入到页面堆中的适当空闲列表中。
内存是根据连续页面的运行来管理的,这些页面称为 Spans(这很重要,因为 Go 语言耶稣根据 Spans 来管理内存的)。
在 TCMalloc 中,span 可以是 assigned,或 free:
- 如果空闲,则 span 是页堆链接列表中的条目之一。
- 如果已分配,则它是一个已移交给应用程序的大对象,或者是已分割成一系列小对象的一组页面。
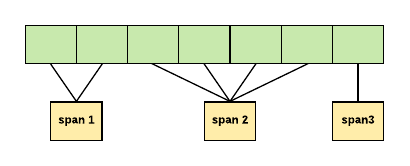
在这个例子中,span 1 占 2 页,span 2 占 4 页,span 3 占 1 页。可以使用按页码索引的中心数组来查找页面所属的跨度。
Go 语言的内存分配器
Go 语言的内存分配器与 TCMalloc 类似,它在页运行(spans/mspan 对象)中工作,使用线程局部缓存并根据大小划分分配。 跨度是 8K 或更大的连续内存区域。在 runtime/mheap.go 中你可以看到有一个名为 mspn 的结构体。Spans有3种类型:
- 空闲 - span,没有对象,可以释放回操作系统,或重用于堆分配,或重用于堆栈内存。
- 正在使用 - span,至少有一个堆对象,可能有更多的空间。
- 栈 - span,用于 goroutine 堆栈。此跨度可以存在于堆栈中或堆中,但不能同时存在。
当分配发生时,我们将对象映射到 3 个大小的类:对于小于 16 字节的对象的极小类,对于达到 32 kB 的对象的小类,以及对于其他对象的大类。小的分配大小被四舍五入到大约 70 个大小的类中的一个,每个类都有它自己的恰好大小的自由对象集。我在 runtime/malloc.go 中发现了一些有趣的注释:小分配器的主要目标是小字符串和独立转义变量。
在json基准测试中,分配器将分配数量减少了大约12%,并将堆大小减少了大约20%。微型分配器将几个微小的分配请求组合成一个16字节的单个内存块。当所有子对象都无法访问时,将释放生成的内存块。子对象不能有指针。
下面描述极小对象是如何工作的:
当分配极小对象:
- 查看这个 P 的 mcache 中对应的小槽对象。
- 根据新对象的大小,将现有子对象的大小(如果存在的话)四舍五入为 8、4 或 2 个字节。
- 如果对象与现有的子对象相匹配,将其放在那里。
如果它不适合小块:
- 看看这个 P 的 mcache 对应的 mspan。
- 从 mcache 获得一个新的 mspan。
- 扫描 mspan 的空闲位图找到一个自由插槽。
- 如果有一个空闲的槽,分配它并将它用作一个新的小槽对象。(这一切都不需要锁。)
如果 mspan 的列表为空:
- 从 mheap 中获取要用于 mspan 的一系列页。
如果 mheap 为空或没有足够大的页面运行:
- 从操作系统分配一组新的页(至少 1MB)。
- 分配大量的页会平摊与操作系统对话的成本。
对于小对象,它非常相似,但我们跳过了第一部分*:
当分配小对象:
- 四舍五入到一个小类的大小。
- 看看这个 P 的 mcache 对应的 mspan。
- 扫描 mspan 的空闲位图找到一个自由插槽。
- 如果有空闲的槽,分配它。(这一切都不需要锁。)
如果 mspan 没有空闲插槽:
- 从 mcentral 提供的具有空闲空间的所需大小类的 mspan 列表中获得一个新的 mspan。
- 获得整个跨度将分摊锁定 mcentral 的成本。
如果 mspan 的列表为空:
- 从 mheap 中获取要用于 mspan 的一系列页。
如果 mheap 为空或没有足够大的页面运行:
- 从操作系统分配一组新的页(至少 1MB)。
- 分配大量的页会平摊与操作系统对话的成本。
分配和释放一个大对象直接使用 mheap,绕过了 mcache 和 mcentral。mheap 的管理类似于 TCMalloc,我们有一个空闲的列表数组。大的对象被四舍五入到页面大小(8K),我们在一个由 k 个页组成的空闲列表中查找第 k 个项,如果它是空的,我们就继续下去。清楚缓存并重复操作,直到第 128 个数组。如果我们没有在 127 页中找到空白页,我们就会在剩下的大页(mspan.freelarge 子段)中寻找一个跨度,如果这个跨度失败,我们就会从操作系统中获取。
这就是在深入研究代码运行时之后的内存分配,通过发掘后发现,MemStats 对我来说更有意义。你可以查看大小类的所有报告,可以查看实现内存管理(如 MCache、MSpan)的多少 bytes 对象,等等。
回到问题中来
为了让你对文章开始提出的问题还有印象,我们再描述一下问题:
func main() {
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %q", html.EscapeString(r.URL.Path))
})
http.ListenAndServe(":8080", nil)
}
go build main.go
./main
ps -u --pid 16609
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
povilasv 16609 0.0 0.0 388496 5236 pts/9 Sl+ 17:21 0:00 ./main
这里使用了大约 380 MiB 虚拟内存。
这是运行时引起的么?
让我们用程序来读取 memstats 的信息:
func main() {
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %q", html.EscapeString(r.URL.Path))
})
go func() {
for {
var m runtime.MemStats
runtime.ReadMemStats(&m)
log.Println(float64(m.Sys) / 1024 / 1024)
log.Println(float64(m.HeapAlloc) / 1024 / 1024)
time.Sleep(10 * time.Second)
}
}()
http.ListenAndServe(":8080", nil)
}
注意:
MemStats.Sys是从系统获得的内存总字节数。Sys测量 Go 语言的运行时给堆,堆栈和其他内部数据结构保留的虚拟地址空间。MemStats.HeapAlloc是为堆对象分配的字节数。
不,看起来不像:
2018/05/08 18:00:34 4.064689636230469
2018/05/08 18:00:34 0.5109481811523438
这个问题属于正常现象?
让我们测试以下这个 C 程序:
#include /* printf, scanf, NULL */
int main (){
int i,n;
printf ("Enter a number:");
scanf ("%d", &i);
return 0;
}
(译者注:编译,运行)
gcc main.c
./a.out
不对,C 程序只花了 10Mb:
ps -u --pid 25074
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
povilasv 25074 0.0 0.0 10832 908 pts/6 S+ 17:48 0:00 ./a.out
让我们试着看看 /proc
cat /proc/30376/status
Name: main
State: S (sleeping)
Pid: 30376
...
FDSize: 64
VmPeak: 386576 kB
VmSize: 386576 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 5116 kB
VmRSS: 5116 kB
RssAnon: 972 kB
RssFile: 4144 kB
RssShmem: 0 kB
VmData: 44936 kB
VmStk: 136 kB
VmExe: 2104 kB
VmLib: 2252 kB
VmPTE: 132 kB
VmSwap: 0 kB
HugetlbPages: 0 kB
CoreDumping: 0
Threads: 6
由于段大小正常,没有帮助,只有 VmSize 的值比较大。
让我们看看 /proc/maps
cat /proc/31086/maps
结果如下:
00400000-0060e000 r-xp 00000000 fd:01 1217120 /main
0060e000-007e5000 r--p 0020e000 fd:01 1217120 /main
007e5000-0081b000 rw-p 003e5000 fd:01 1217120 /main
0081b000-0083d000 rw-p 00000000 00:00 0
0275d000-0277e000 rw-p 00000000 00:00 0 [heap]
c000000000-c000001000 rw-p 00000000 00:00 0
c41fff0000-c420200000 rw-p 00000000 00:00 0
7face8000000-7face8021000 rw-p 00000000 00:00 0
7face8021000-7facec000000 ---p 00000000 00:00 0
7facec000000-7facec021000 rw-p 00000000 00:00 0
...
7facf4021000-7facf8000000 ---p 00000000 00:00 0
7facf8000000-7facf8021000 rw-p 00000000 00:00 0
7facf8021000-7facfc000000 ---p 00000000 00:00 0
7facfd323000-7facfd324000 ---p 00000000 00:00 0
7facfd324000-7facfdb24000 rw-p 00000000 00:00 0
7facfdb24000-7facfdb25000 ---p 00000000 00:00 0
...
7facfeb27000-7facff327000 rw-p 00000000 00:00 0
7facff327000-7facff328000 ---p 00000000 00:00 0
7facff328000-7facffb28000 rw-p 00000000 00:00 0
7fddc2798000-7fddc2f98000 rw-p 00000000 00:00 0
...
7fddc2f98000-7fddc2f9b000 r-xp 00000000 fd:01 2363785 libdl-2.27.so
...
7fddc319c000-7fddc3383000 r-xp 00000000 fd:01 2363779 libc-2.27.so
...
7fddc3587000-7fddc3589000 rw-p 001eb000 fd:01 2363779 libc-2.27.so
7fddc3589000-7fddc358d000 rw-p 00000000 00:00 0
7fddc358d000-7fddc35a7000 r-xp 00000000 fd:01 2363826 libpthread-2.27.so
...
7fddc37a8000-7fddc37ac000 rw-p 00000000 00:00 0
7fddc37ac000-7fddc37b2000 r-xp 00000000 fd:01 724559 libgtk3-nocsd.so.0
...
7fddc39b2000-7fddc39b3000 rw-p 00006000 fd:01 724559 libgtk3-nocsd.so.0
7fddc39b3000-7fddc39da000 r-xp 00000000 fd:01 2363771 ld-2.27.so
7fddc3af4000-7fddc3bb8000 rw-p 00000000 00:00 0
7fddc3bda000-7fddc3bdb000 r--p 00027000 fd:01 2363771 ld-2.27.so
....
7fddc3bdc000-7fddc3bdd000 rw-p 00000000 00:00 0
7fff472e9000-7fff4730b000 rw-p 00000000 00:00 0 [stack]
7fff473a7000-7fff473aa000 r--p 00000000 00:00 0 [vvar]
7fff473aa000-7fff473ac000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 [vsyscall]
把所有这些地址加起来可能会留下相同的结果,大约是 380Mb。我懒得总结。但它很有趣,向右滚动你会看到 libc 和其他共享库映射到你的进程。
让我们尝试另一个简单点儿的程序
func main() {
go func() {
for {
var m runtime.MemStats
runtime.ReadMemStats(&m)
log.Println(float64(m.Sys) / 1024 / 1024)
log.Println(float64(m.HeapAlloc) / 1024 / 1024)
time.Sleep(10 * time.Second)
}
}()
fmt.Println("hello")
time.Sleep(1 * time.Hour)
}
编译运行:
go build main.go
./main
$ ps -u --pid 3642
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
povilasv 3642 0.0 0.0 4900 948 pts/10 Sl+ 09:07 0:00 ./main
恩,是不是很有意思?这个程序只花了 4Mb (RSS)。
未完待续。。。
感谢你阅读本文。一如既往的,我期待你的评论。同时请不要破坏我在评论中的搜索????
via: https://povilasv.me/go-memory-management/
作者:Povilas 译者:7Ethan 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




