slice表示切片(分片),例如对一个数组进行切片,取出数组中的一部分值。在现代编程语言中,slice(切片)几乎成为一种必备特性,它可以从一个数组(列表)中取出任意长度的子数组(列表),为操作数据结构带来非常大的便利性,如python、perl等都支持对数组的slice操作,甚至perl还支持对hash数据结构的slice。
但Go中的slice和这些语言的slice不太一样,前面所说的语言中,slice是一种切片的操作,切片后返回一个新的数据对象。而Go中的slice不仅仅是一种切片动作,还是一种数据结构(就像数组一样)。
slice的存储结构
Go中的slice依赖于数组,它的底层就是数组,所以数组具有的优点,slice都有。且slice支持可以通过append向slice中追加元素,长度不够时会动态扩展,通过再次slice切片,可以得到得到更小的slice结构,可以迭代、遍历等。
实际上slice是这样的结构:先创建一个有特定长度和数据类型的底层数组,然后从这个底层数组中选取一部分元素,返回这些元素组成的集合(或容器),并将slice指向集合中的第一个元素。换句话说,slice自身维护了一个指针属性,指向它底层数组中的某些元素的集合。
例如,初始化一个slice数据结构:
my_slice := make([]int, 3,5)
// 输出slice
fmt.Println(my_slice) // 输出:[0 0 0]这表示先声明一个长度为5、数据类型为int的底层数组,然后从这个底层数组中从前向后取3个元素(即index从0到2)作为slice的结构。
如下图:
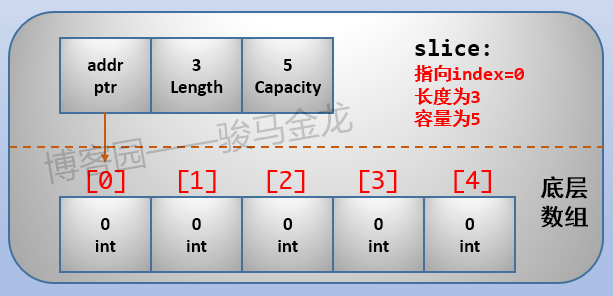
每一个slice结构都由3部分组成:容量(capacity)、长度(length)和指向底层数组某元素的指针,它们各占8字节(1个机器字长,64位机器上一个机器字长为64bit,共8字节大小,32位架构则是32bit,占用4字节),所以任何一个slice都是24字节(3个机器字长)。
- Pointer:表示该slice结构从底层数组的哪一个元素开始,该指针指向该元素
- Capacity:即底层数组的长度,表示这个slice目前最多能扩展到这么长
- Length:表示slice当前的长度,如果追加元素,长度不够时会扩展,最大扩展到Capacity的长度(不完全准确,后面数组自动扩展时解释),所以Length必须不能比Capacity更大,否则会报错
对上面创建的slice来说,它的长度为3,容量为5,指针指向底层数组的index=0。
可以通过len()函数获取slice的长度,通过cap()函数获取slice的Capacity。
my_slice := make([]int,3,5)
fmt.Println(len(my_slice)) // 3
fmt.Println(cap(my_slice)) // 5还可以直接通过print()或println()函数去输出slice,它将得到这个slice结构的属性值,也就是length、capacity和pointer:
my_slice := make([]int,3,5)
println(my_slice) // [3/5]0xc42003df10[3/5]表示length和capacity,0xc42003df10表示指向的底层数组元素的指针。
务必记住slice的本质是[x/y]0xADDR,记住它将在很多地方有助于理解slice的特性。另外,个人建议,虽然slice的本质不是指针,但仍然可以将它看作是一种包含了另外两种属性的不纯粹的指针,也就是说,直接认为它是指针。其实不仅slice如此,map也如此。
创建、初始化、访问slice
有几种创建slice数据结构的方式。
一种是使用make():
// 创建一个length和capacity都等于5的slice
slice := make([]int,5)
// length=3,capacity=5的slice
slice := make([]int,3,5)make()比new()函数多一些操作,new()函数只会进行内存分配并做默认的赋0初始化,而make()可以先为底层数组分配好内存,然后从这个底层数组中再额外生成一个slice并初始化。另外,make只能构建slice、map和channel这3种结构的数据对象,因为它们都指向底层数据结构,都需要先为底层数据结构分配好内存并初始化。
还可以直接赋值初始化的方式创建slice:
// 创建长度和容量都为4的slice,并初始化赋值
color_slice := []string{"red","blue","black","green"}
// 创建长度和容量为100的slice,并为第100个元素赋值为3
slice := []int{99:3}注意区分array和slice:
// 创建长度为3的int数组
array := [3]int{10, 20, 30}
// 创建长度和容量都为3的slice
slice := []int{10, 20, 30}由于slice底层是数组,所以可以使用索引的方式访问slice,或修改slice中元素的值:
// 创建长度为5、容量为5的slice
my_slice := []int{11,22,33,44,55}
// 访问slice的第2个元素
print(my_slice[1])
// 修改slice的第3个元素的值
my_slice[2] = 333由于slice的底层是数组,所以访问my_slice[1]实际上是在访问它的底层数组的对应元素。slice能被访问的元素只有length范围内的元素,那些在length之外,但在capacity之内的元素暂时还不属于slice,只有在slice被扩展时(见下文append),capacity中的元素才被纳入length,才能被访问。
nil slice和空slice
当声明一个slice,但不做初始化的时候,这个slice就是一个nil slice。
// 声明一个nil slice
var nil_slice []intnil slice表示它的指针为nil,也就是这个slice不会指向哪个底层数组。也因此,nil slice的长度和容量都为0。
|--------|---------|----------|
| nil | 0 | 0 |
| ptr | Length | Capacity |
|--------|---------|----------|还可以创建空slice(Empty Slice),空slice表示长度为0,容量为0,但却有指向的slice,只不过指向的底层数组暂时是长度为0的空数组。
// 使用make创建
empty_slice := make([]int,0)
// 直接创建
empty_slice := []int{}Empty Slice的结构如下:
|--------|---------|----------|
| ADDR | 0 | 0 |
| ptr | Length | Capacity |
|--------|---------|----------|虽然nil slice和Empty slice的长度和容量都为0,输出时的结果都是[],且都不存储任何数据,但它们是不同的。nil slice不会指向底层数组,而空slice会指向底层数组,只不过这个底层数组暂时是空数组。
可以使用println()来输出验证:
package main
func main() {
var nil_s []int
empty_s:= []int{}
println(nil_s)
println(empty_s)
}输出结果:
[0/0]0x0
[0/0]0xc042085f50当然,无论是nil slice还是empty slice,都可以对它们进行操作,如append()函数、len()函数和cap()函数。
对slice进行切片
可以从slice中继续切片生成一个新的slice,这样能实现slice的缩减。
对slice切片的语法为:
SLICE[A:B]
SLICE[A:B:C]其中A表示从SLICE的第几个元素开始切,B控制切片的长度(B-A),C控制切片的容量(C-A),如果没有给定C,则表示切到底层数组的最尾部。
还有几种简化形式:
SLICE[A:] // 从A切到最尾部
SLICE[:B] // 从最开头切到B(不包含B)
SLICE[:] // 从头切到尾,等价于复制整个SLICE例如:
my_slice := []int{11,22,33,44,55}
// 生成新的slice,从第二个元素取,切取的长度为2
new_slice := my_slice[1:3]注意,截取时"左闭右开"。所以上面new_slice是从my_slice的index=1开始截取,截取到index=3为止,但不包括index=3这个元素。所以,新的slice是由my_slice中的第2个元素、第3个元素组成的新的数据结构,长度为2。
以下是slice切片生成新的slice后的结构:
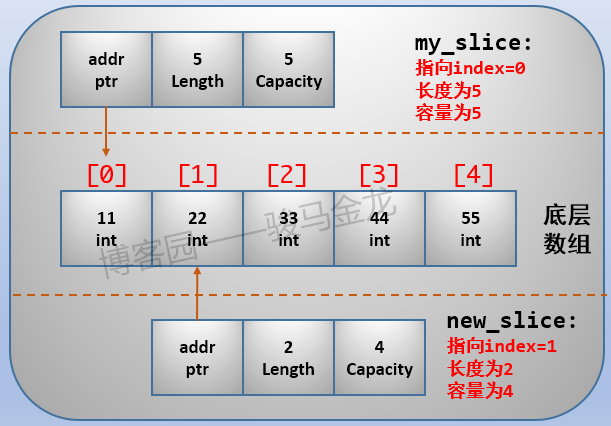
不难发现,一个底层数组,可以生成无数个slice,且对于new_slice而言,它并不知道底层数组index=0的那个元素。
还可以控制切片时新slice的容量:
my_slice := []int{11,22,33,44,55}
// 从第二个元素取,切取的长度为2,容量也为2
new_slice := my_slice[1:3:3]这时新slice的length等于capacity,底层数组的index=4、5将对new_slice永不可见,即使后面对new_slice进行append()导致底层数组扩容也仍然不可见。具体见下文。
由于多个slice共享同一个底层数组,所以当修改了某个slice中的元素时,其它包含该元素的slice也会随之改变,因为slice只是一个指向底层数组的指针(只不过这个指针不纯粹,多了两个额外的属性length和capacity),实际上修改的是底层数组的值,而底层数组是被共享的。
当同一个底层数组有很多slice的时候,一切将变得混乱不堪,因为我们不可能记住谁在共享它,通过修改某个slice的元素时,将也会影响那些可能我们不想影响的slice。所以,需要一种特性,保证各个slice的底层数组互不影响,相关内容见下面的"扩容"。
copy()函数
可以将一个slice拷贝到另一个slice中。
$ go doc builtin copy
func copy(dst, src []Type) int这表示将src slice拷贝到dst slice,src比dst长,就截断,src比dst短,则只拷贝src那部分。
copy的返回值是拷贝成功的元素数量,所以也就是src slice或dst slice中最小的那个长度。
例如:
s1 := []int{11, 22, 33}
s2 := make([]int, 5)
s3 := make([]int,2)
num := copy(s2, s1)
copy(s3,s1)
fmt.Println(num) // 3
fmt.Println(s2) // [11,22,33,0,0]
fmt.Println(s3) // [11,22]此外,copy还能将字符串拷贝到byte slice中,因为字符串实际上就是[]byte。
func main() {
s1 := []byte("Hello")
num := copy(s1, "World")
fmt.Println(num)
fmt.Println(s1) // 输出[87 111 114 108 100 32]
fmt.Println(string(s1)) //输出"World"
}append()函数
可以使用append()函数对slice进行扩展,因为它追加元素到slice中,所以一定会增加slice的长度。
但必须注意,append()的结果必须被使用。所谓被使用,可以将其输出、可以赋值给某个slice。如果将append()放在空上下文将会报错:append()已评估,但未使用。同时这也说明,append()返回一个新的slice,原始的slice会保留不变。
例如:
my_slice := []int{11,22,33,44,55}
new_slice := my_slice[1:3]
// append()追加一个元素2323,返回新的slice
app_slice := append(new_slice,2323)上面的append()在new_slice的后面增加了一个元素2323,所以app_slice[2]=2323。但因为这些slice共享同一个底层数组,所以2323也会反映到其它slice中。
现在的数据结构图如下:

当然,如果append()的结果重新赋值给new_slice,则new_slice会增加长度。
同样,由于string的本质是[]byte,所以string可以append到byte slice中:
s1 := []byte("Hello")
s2 := append(s1, "World"...)
fmt.Println(string(s2)) // 输出:HelloWorld扩容
当slice的length已经等于capacity的时候,再使用append()给slice追加元素,会自动扩展底层数组的长度。
底层数组扩展时,会生成一个新的底层数组。所以旧底层数组仍然会被旧slice引用,新slice和旧slice不再共享同一个底层数组。
func main() {
my_slice := []int{11,22,33,44,55}
new_slice := append(my_slice,66)
my_slice[3] = 444 // 修改旧的底层数组
fmt.Println(my_slice) // [11 22 33 444 55]
fmt.Println(new_slice) // [11 22 33 44 55 66]
fmt.Println(len(my_slice),":",cap(my_slice)) // 5:5
fmt.Println(len(new_slice),":",cap(new_slice)) // 6:10
}从上面的结果上可以发现,底层数组被扩容为10,且是新的底层数组。
实际上,当底层数组需要扩容时,会按照当前底层数组长度的2倍进行扩容,并生成新数组。如果底层数组的长度超过1000时,将按照25%的比率扩容,也就是1000个元素时,将扩展为1250个,不过这个增长比率的算法可能会随着go版本的递进而改变。
实际上,上面的说法应该改一改:当capacity需要扩容时,会按照当前capacity的2倍对数组进行扩容。或者说,是按照slice的本质[x/y]0xADDR的容量y来判断如何扩容的。之所以要特别强调这两种不同,是因为很容易搞混。
例如,扩容的对象是底层数组的真子集时:
my_slice := []int{11,22,33,44,55}
// 限定长度和容量,且让长度和容量相等
new_slice := my_slice[1:3:3] // [22 33]
// 扩容
app_slice := append(new_slice,4444)上面的new_slice的容量为2,并没有对应到底层数组的最结尾,所以new_slice是my_slice的一个真子集。这时对new_slice扩容,将生成一个新的底层数组,新的底层数组容量为4,而不是10。如下图:
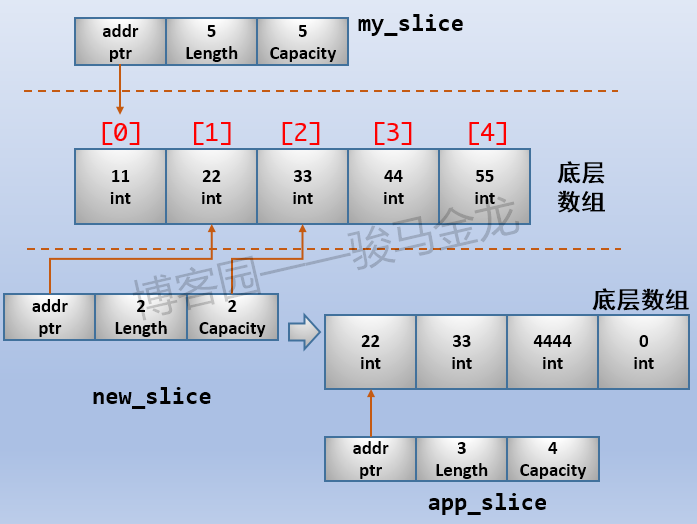
因为创建了新的底层数组,所以修改不同的slice,将不会互相影响。为了保证每次都是修改各自的底层数组,通常会切出仅一个长度、仅一个容量的新slice,这样只要对它进行任何一次扩容,就会生成一个新的底层数组,从而让每个slice的底层数组都独立。
my_slice := []int{11,22,33,44,55}
new_slice := my_slice[2:3:3]
app_slice := append(new_slice,3333)事实上,这还是会出现共享的几率,因为没有扩容时,那个唯一的元素仍然是共享的,修改它肯定会影响至少1个slice,只有切出长度为0,容量为0的slice,才能完全保证独立性,但这和新创建一个slice没有区别。
合并slice
slice和数组其实一样,都是一种值,可以将一个slice和另一个slice进行合并,生成一个新的slice。
合并slice时,只需将append()的第二个参数后加上...即可,即append(s1,s2...)表示将s2合并在s1的后面,并返回新的slice。
s1 := []int{1,2}
s2 := []int{3,4}
s3 := append(s1,s2...)
fmt.Println(s3) // [1 2 3 4]注意append()最多允许两个参数,所以一次性只能合并两个slice。但可以取巧,将append()作为另一个append()的参数,从而实现多级合并。例如,下面的合并s1和s2,然后再和s3合并,得到s1+s2+s3合并后的结果。
sn := append(append(s1,s2...),s3...)slice遍历迭代
slice是一个集合,所以可以进行迭代。
range关键字可以对slice进行迭代,每次返回一个index和对应的元素值。可以将range的迭代结合for循环对slice进行遍历。
package main
func main() {
s1 := []int{11,22,33,44}
for index,value := range s1 {
println("index:",index," , ","value",value)
}
}输出结果:
index: 0 , value 11
index: 1 , value 22
index: 2 , value 33
index: 3 , value 44传递slice给函数
前面说过,虽然slice实际上包含了3个属性,它的数据结构类似于[3/5]0xc42003df10,但仍可以将slice看作一种指针。这个特性直接体现在函数参数传值上。
Go中函数的参数是按值传递的,所以调用函数时会复制一个参数的副本传递给函数。如果传递给函数的是slice,它将复制该slice副本给函数,这个副本实际上就是[3/5]0xc42003df10,所以传递给函数的副本仍然指向源slice的底层数组。
换句话说,如果函数内部对slice进行了修改,有可能会直接影响函数外部的底层数组,从而影响其它slice。但并不总是如此,例如函数内部对slice进行扩容,扩容时生成了一个新的底层数组,函数后续的代码只对新的底层数组操作,这样就不会影响原始的底层数组。
例如:
package main
import "fmt"
func main() {
s1 := []int{11, 22, 33, 44}
foo(s1)
fmt.Println(s1[1]) // 输出:23
}
func foo(s []int) {
for index, _ := range s {
s[index] += 1
}
}上面将输出23,因为foo()直接操作原始的底层数组,对slice的每个元素都加1。
slice和内存浪费问题
由于slice的底层是数组,很可能数组很大,但slice所取的元素数量却很小,这就导致数组占用的绝大多数空间是被浪费的。
特别地,垃圾回收器(GC)不会回收正在被引用的对象,当一个函数直接返回指向底层数组的slice时,这个底层数组将不会随函数退出而被回收,而是因为slice的引用而永远保留,除非返回的slice也消失。
因此,当函数的返回值是一个指向底层数组的数据结构时(如slice),应当在函数内部将slice拷贝一份保存到一个使用自己底层数组的新slice中,并返回这个新的slice。这样函数一退出,原来那个体积较大的底层数组就会被回收,保留在内存中的是小的slice。
有疑问加站长微信联系(非本文作者)



