
自从我开始使用 Go 编程以来,slice 的概念和使用一直令人困惑。slice 看起来像一个数组,感觉就像一个数组,但它们不仅仅是一个数组,对我来说是一种全新的概念。我一直在阅读 Go 程序员如何使用 slice,我认为现在终于明白了 slice 的用途。
Andrew Gerrand 撰写了一篇非常棒的关于 slice 的博文:
http://blog.golang.org/go-slices-usage-and-internals
没有理由重复 Andrew 所写的一切,所以请在开始之前阅读他的博文。这篇文章专注于 slice 的内部实现。
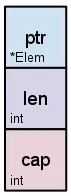
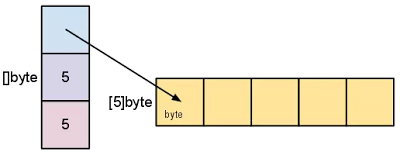
上图表示 slice 的内部结构。分配 slice 时,将创建此数据结构以及对应的基础数组。slice 变量的值指向该数据结构。将 slice 传递给函数时,会在堆栈上创建此数据结构的副本。
我们可以用两种方式创建一个 slice:
这里我们使用关键字 make 来创建 slice。需要传递我们存储的数据类型,slice 的初始长度和底层数组的容量,例如
mySlice := make([]string, 5, 8)
mySlice[0] = "Apple"
mySlice[1] = "Orange"
mySlice[2] = "Banana"
mySlice[3] = "Grape"
mySlice[4] = "Plum"
// You don ’ t need to include the capacity. Length and Capacity will be the same
mySlice := make([]string, 5)
您还可以使用 slice 字面量来定义 slice。在这种情况下,长度和容量将是相同的。请注意,中括号[]内没有提供任何值。如果添加一个值,您将拥有一个 array。如果您不添加值,您将获得一个 slice。
mySlice := []string{"Apple", "Orange", "Banana", "Grape", "Plum"}
创建 slice 后,无法扩展 slice 的容量。更改容量的唯一方法是创建新 slice 并执行复制。Andrew 提供了一个很好的示例函数,它显示了检查剩余容量的有效方法,并且只在必要时执行复制。
slice 的长度标识了我们从起始索引位置使用的基础数组的元素数量。容量标识了我们可以使用的总元素数量。
我们可以从原始 slice 创建一个新 slice:
newSlice := mySlice[2:4]
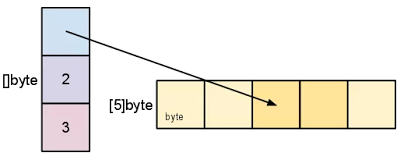
新 slice 的指针变量的值与初始基础数组的索引位置 2 和 3 相关联。就这个新 slice 而言,我们现在有一个包含 3 个元素的基础数组,我们只使用这 3 个元素中的 2 个。这个 slice 无法访问初始底层数组的前两个元素。
执行 slice 操作时,第一个参数指定 slice 指针变量位置的起始索引。在我们的例子中,我们说索引 2 是初始底层数组中的 3 个元素,我们从中获取 slice。第二个参数是最后一个索引位置加一(+1)。在我们的例子中,我们说索引 4 将包括索引 2(起始位置)和索引 3(最终位置)之间的所有索引。
执行 slice 操作时,我们并不总是需要包含起始或结束索引位置:
newSlice2 = newSlice[:cap(newSlice)]
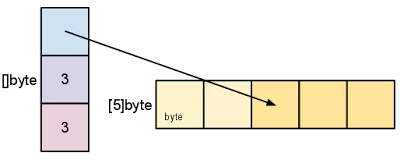
在此示例中,我们使用之前创建的新 slice 来创建第三个 slice。我们不提供起始索引位置,但我们确实指定了最后一个索引位置。我们最新的 slice 具有相同的起始位置和容量,但长度已经改变。通过将最后一个索引位置指定为容量大小,此 slice 的此长度使用基础数组中的所有剩余元素。
现在让我们运行一些代码来证明这个数据结构实际存在,并且 slice 按照说明的方式工作。
我创建了一个函数来检查与任何 slice 关联的内存:
func InspectSlice(slice []string) {
// Capture the address to the slice structure
address := unsafe.Pointer(&slice)
addrSize := unsafe.Sizeof(address)
// Capture the address where the length and cap size is stored
lenAddr := uintptr(address) + addrSize
capAddr := uintptr(address) + (addrSize * 2)
// Create pointers to the length and cap size
lenPtr := (*int)(unsafe.Pointer(lenAddr))
capPtr := (*int)(unsafe.Pointer(capAddr))
// Create a pointer to the underlying array
addPtr := (*[8]string)(unsafe.Pointer(*(*uintptr)(address)))
fmt.Printf("Slice Addr[%p] Len Addr[0x%x] Cap Addr[0x%x]\n",
address,
lenAddr,
capAddr)
fmt.Printf("Slice Length[%d] Cap[%d]\n",
*lenPtr,
*capPtr)
for index := 0; index < *lenPtr; index++ {
fmt.Printf("[%d] %p %s\n",
index,
&(*addPtr)[index],
(*addPtr)[index])
}
fmt.Printf("\n\n")
}
此函数正在执行一系列指针操作,因此我们可以检查 slice 的数据结构和底层数组的内存和值。
我们将它分解,但首先让我们创建一个 slice 并通过 inspect 函数运行它:
package main
import (
"fmt"
"unsafe"
)
func main() {
orgSlice := make([]string, 5, 8)
orgSlice[0] = "Apple"
orgSlice[1] = "Orange"
orgSlice[2] = "Banana"
orgSlice[3] = "Grape"
orgSlice[4] = "Plum"
InspectSlice(orgSlice)
}
这是程序的输出:
Slice Addr[0x2101be000] Len Addr[0x2101be008] Cap Addr[0x2101be010]
Slice Length[5] Cap[8]
[0] 0x2101bd000 Apple
[1] 0x2101bd010 Orange
[2] 0x2101bd020 Banana
[3] 0x2101bd030 Grape
[4] 0x2101bd040 Plum
正如 Andrew 所描述的那样,slice 的数据结构确实存在。
InspectSlice 函数首先显示 slice 数据结构的地址以及长度和容量值应该在的地址位置。然后通过使用这些地址创建 int 指针,我们显示长度和容量的值。最后,我们创建一个指向底层数组的指针。使用指针,我们遍历底层数组,显示索引位置,元素的起始地址和值。
让我们分解 InspectSlice 函数来理解它是如何工作的:
// Capture the address to the slice structure
address := unsafe.Pointer(&slice)
addrSize := unsafe.Sizeof(address)
// Capture the address where the length and cap size is stored
lenAddr := uintptr(address) + addrSize
capAddr := uintptr(address) + (addrSize * 2)
unsafe.Pointer 是一种映射到 uintptr 类型的特殊类型。因为我们需要执行指针运算,所以我们需要使用通用指针。第一行代码将 slice 的数据结构的地址强制转换为 unsafe.Pointer。然后我们得到编码运行的架构的地址大小。现在知道了地址大小,我们创建了两个通用指针,分别将地址大小和地址大小字节的两倍指向 slice 的数据结构。
下图显示了每个指针变量,变量的值以及指针指向的值:
| address | lenAddr | capAddr |
|---|---|---|
| 0x2101be000 | 0x2101be008 | 0x2101be010 |
| 0x2101bd000 | 5 | 8 |
有了我们的指针,我们现在可以创建正确的类型指针,以便我们可以显示值。这里我们创建两个整数指针,可用于显示 slice 数据结构的长度和容量值。
// Create pointers to the length and cap size
lenPtr := (*int)(unsafe.Pointer(lenAddr))
capPtr := (*int)(unsafe.Pointer(capAddr))
我们现在需要一个类型为[8]字符串的指针,它是底层数组的类型。
// Create a pointer to the underlying array
addPtr := (*[8]string)(unsafe.Pointer(*(*uintptr)(address)))
在这一个语句中有很多内容,所以让我们将其分解:
(*uintptr)(address):0x2101be000。此代码获取 slice 数据结构的起始地址并将其转换为通用指针。
*(*uintptr)(address):0x2101bd000。然后我们得到指针指向的值,这是底层数组的起始地址。
unsafe.Pointer(*(*uintptr)(address))。然后我们将底层数组的起始地址转换为 unsafe.Pointer 类型。我们需要一个这种类型的指针来执行最后的步骤。
(*[8]string)(unsafe.Pointer(*(*uintptr)(address)))
最后,我们将 unsafe.Pointer 转换为正确类型的指针。
其余代码使用正确的指针来显示输出:
fmt.Printf("Slice Addr[%p] Len Addr[0x%x] Cap Addr[0x%x]\n",
address,
lenAddr,
capAddr)
fmt.Printf("Slice Length[%d] Cap[%d]\n",
*lenPtr,
*capPtr)
for index := 0; index < *lenPtr; index++ {
fmt.Printf("[%d] %p %s\n",
index,
&(*addPtr)[index],
(*addPtr)[index])
}
现在让我们将整个程序放在一起并创建一些 slice。我们将检查每个 slice 并确保我们所知道的 slice 是真的:
package main
import (
"fmt"
"unsafe"
)
func main() {
orgSlice := make([]string, 5, 8)
orgSlice[0] = "Apple"
orgSlice[1] = "Orange"
orgSlice[2] = "Banana"
orgSlice[3] = "Grape"
orgSlice[4] = "Plum"
InspectSlice(orgSlice)
slice2 := orgSlice[2:4]
InspectSlice(slice2)
slice3 := slice2[1:cap(slice2)]
InspectSlice(slice3)
slice3[0] = "CHANGED"
InspectSlice(slice3)
InspectSlice(slice2)
}
func InspectSlice(slice []string) {
// Capture the address to the slice structure
address := unsafe.Pointer(&slice)
addrSize := unsafe.Sizeof(address)
// Capture the address where the length and cap size is stored
lenAddr := uintptr(address) + addrSize
capAddr := uintptr(address) + (addrSize * 2)
// Create pointers to the length and cap size
lenPtr := (*int)(unsafe.Pointer(lenAddr))
capPtr := (*int)(unsafe.Pointer(capAddr))
// Create a pointer to the underlying array
addPtr := (*[8]string)(unsafe.Pointer(*(*uintptr)(address)))
fmt.Printf("Slice Addr[%p] Len Addr[0x%x] Cap Addr[0x%x]\n",
address,
lenAddr,
capAddr)
fmt.Printf("Slice Length[%d] Cap[%d]\n",
*lenPtr,
*capPtr)
for index := 0; index < *lenPtr; index++ {
fmt.Printf("[%d] %p %s\n",
index,
&(*addPtr)[index],
(*addPtr)[index])
}
fmt.Printf("\n\n")
}
下面是每个 slice 的代码和输出:
这里我们创建一个初始 slice,其长度为 5 个元素,容量为 8 个元素。
Code:
orgSlice := make([]string, 5, 8)
orgSlice[0] = "Apple"
orgSlice[1] = "Orange"
orgSlice[2] = "Banana"
orgSlice[3] = "Grape"
orgSlice[4] = "Plum"
Output:
Slice Addr[0x2101be000] Len Addr[0x2101be008] Cap Addr[0x2101be010]
Slice Length[5] Cap[8]
[0] 0x2101bd000 Apple
[1] 0x2101bd010 Orange
[2] 0x2101bd020 Banana
[3] 0x2101bd030 Grape
[4] 0x2101bd040 Plum
输出符合预期。长度为 5,容量为 8,底层数组包含我们的值。
接下来,我们从原始 slice 中获取 slice。我们要求索引 2 和 3 之间有 2 个元素。
Code:
slice2 := orgSlice[2:4]
InspectSlice(slice2)
Output:
Slice Addr[0x2101be060] Len Addr[0x2101be068] Cap Addr[0x2101be070]
Slice Length[2] Cap[6]
[0] 0x2101bd020 Banana
[1] 0x2101bd030 Grape
在输出中,您可以看到我们有一个长度为 2 且容量为 6 的 slice。因为这个新 slice 在原始 slice 的底层数组中启动了 3 个元素,所以有 6 个元素的容量。容量包括新 slice 可以访问的所有可能元素。新 slice 的索引 0 映射到原始 slice 的索引 2。它们都具有相同的地址 0x2101bd020。
这次我们要求从索引位置 1 开始 slice 到 slice2 的最后一个元素。
Code:
slice3 := slice2[1:cap(slice2)]
InspectSlice(slice3)
Output:
Slice Addr[0x2101be0a0] Len Addr[0x2101be0a8] Cap Addr[0x2101be0b0]
Slice Length[5] Cap[5]
[0] 0x2101bd030 Grape
[1] 0x2101bd040 Plum
[2] 0x2101bd050
[3] 0x2101bd060
[4] 0x2101bd070
正如预期的那样,长度和容量都是 5. 当我们显示 slice 的所有值时,您会看到最后三个元素没有值。在创建基础数组时,slice 初始化了所有元素。此 slice 的索引 0 也映射到 slice2 的索引 1 和原始 slice 的索引 3。它们都具有相同的地址 0x2101bd030。
最终代码将第一个元素的值(slice3 中的索引 0)更改为值 CHANGED。然后我们显示 slice3 和 slice2 的值。
slice3[0] = "CHANGED"
InspectSlice(slice3)
InspectSlice(slice2)
Slice Addr[0x2101be0e0] Len Addr[0x2101be0e8] Cap Addr[0x2101be0f0]
Slice Length[5] Cap[5]
[0] 0x2101bd030 CHANGED
[1] 0x2101bd040 Plum
[2] 0x2101bd050
[3] 0x2101bd060
[4] 0x2101bd070
Slice Addr[0x2101be120] Len Addr[0x2101be128] Cap Addr[0x2101be130]
Slice Length[2] Cap[6]
[0] 0x2101bd020 Banana
[1] 0x2101bd030 CHANGED
请注意,两个 slice 都在其尊重索引中显示更改的值。这证明了所有 slice 都使用相同的底层数组。
InspectSlice 函数证明每个 slice 都包含自己的数据结构,其中包含指向底层数组的指针,slice 的长度和容量。花些时间创建更多 slice 并使用 InspectSlice 函数验证您的假设。
via: https://www.ardanlabs.com/blog/2013/08/understanding-slices-in-go-programming.html
作者:William Kennedy 译者:lovechuck 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




