
这是用 Go 创建新的智能合约语言项目的第二篇文章。在上一篇文章中,介绍了项目的概念,为什么我们决定去构建新的智能合约语言和简要的架构。这个项目就是 WIP 并且开放了源码,你可以在 [这里](https://github.com/DE-labtory/koa) 访问它并随时向我们做出贡献。
- **前面的文章:** [**新语言概念,目标,架构**](https://studygolang.com/articles/17960)
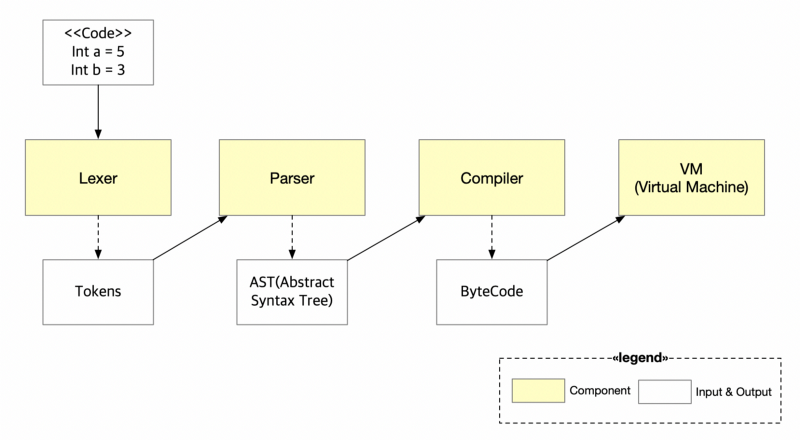
<center>koa 架构 </center>
项目由四个组件组成:词法分析器,语法分析器,编译器,VM。在这篇文章中我们将深入讨论第一个组件:**词法分析器**。
## 词法分析器?
在我们上代码之前,什么是词法分析器?词法分析器做的事就是按照字面意思对给出的输入文本做词法分析。然后词法分析是怎么进行的呢?第一个词法分析器一个一个地读取根据编程语言规则编写的由源码组成的字符流,然后无论什么时候词法分析器遇到由字符组成的词位是有意义的组合时,将该词位作为 `token` 并继续做相同的事情直到我们遇到 `eof`。
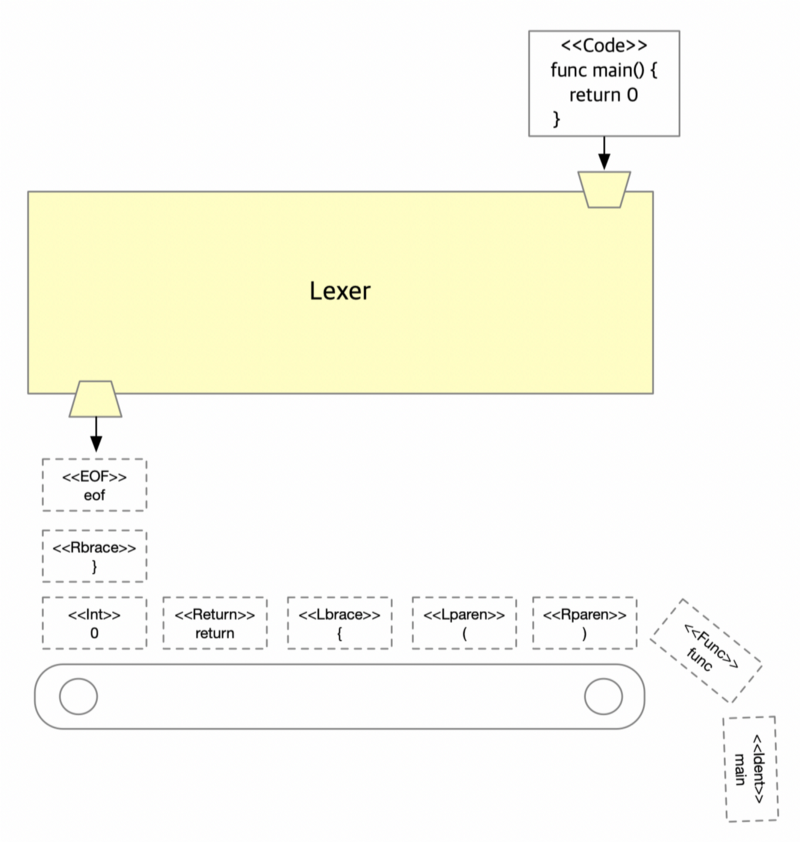
<center> 词法分析器是怎么工作的? </center>
例如,在图中词法分析器取到源码;‘ fun main() { return 0 } ’,然后词法分析器逐个字符地读取代码;‘ f ’,‘ u ’,‘ n ’,‘ c ’。当词法分析器读到‘ c ’,它知道‘ fun ’ + ‘ c ’是一个有意义的单词,函数关键字,然后词法分析器将‘ func ’字符从文本(代码)中剪切下来并为该单词制作 **token**。词法分析器继续像这样工作,直到我们遇到 `eof`。**简而言之,词法分析器把字符分组并制作 tokens**。
## Token ?
是的,词法分析器制作 tokens …但…什么是 token 呢?我们可以将‘ func ’是视为原始数据,但如果不处理这些数据,这些数据就不能轻易地在其他组件中被使用。token 就是为我们做那样的工作,token 是帮助数据结构化地被表达的数据结构。
```go
type TokenType int
type Token struct {
Type TokenType
Val string
Column Pos
Line int
}
```
这就是我们在项目中被定义的 token。`Type` 是单词的类型,`Val` 是单词的值。使用这个 `Token` 结构,其他组件像是解析器能够更有效地完成它地工作,并且代码将会具有很高的可维护性和可伸缩性。
## 如何进行标记?
### 状态,行为
我们的词法分析器设计的灵感来源于使用了 **状态和行为** 概念的 [golang template package](https://github.com/golang/go/tree/master/src/text/template/parse)。实际上 [go-ethereum](https://github.com/ethereum/go-ethereum/blob/master/core/asm/lexer.go) 也使用了这个概念。
- **状态** 表示词法分析器来自给定输入文本的位置以及我们希望接下来看到的内容。
- **行为** 表示当前状态我们将要做的事情。
我们可以看到词法分析器的工作 - 读取字符,生成 token,继续下一个字符 - 当前状态所做的行为然后前进到下一个状态。在每一个操作过后,你知道你想要到的地方,新的状态是这个行为的结果。
#### 状态函数
```go
// stateFn determines how to scan the current state.
// stateFn also returns the stateFn to be scanned next after scanning the current state.
type stateFn func(*state, emitter) stateFn
```
这是我们状态函数的声明。状态函数利用当前状态和发送器,返回另外的状态函数。被返回的状态函数是基于当前状态并且知道接下来做什么。我知道虽然状态函数的定义是递归的,但是这样简单且清晰。
```go
// emitter is the interface to emit the token to the client(parser).
type emitter interface {
emit(t Token)
}
```
你可能会好奇,`emitter` 为我们做了什么呢。你可能已经注意到我们知道如何去对给定的输入进行词法分析,但是不知道如何传递被生成的 tokens 到像是解析器这样的客户端。这就也是我们为什么需要 `emitter`,`emitter` 使用 Go 的一个特征,channel,简单地传递 token 到客户端。我们将在在几秒钟内明白 `emitter` 是如何工作的。
#### 运行我们的状态机
```go
// run runs the state Machine for the lexer.
func (l *Lexer) run(input string) {
state := &state{
input: input,
}
for stateFn := defaultStateFn; stateFn != nil; {
stateFn = stateFn(state, l)
}
close(l.tokench)
}
```
这就是我们词法分析器的 `run` 方法,它获取到输入的字符串 - 源码 - 并且对我们的输入进行 `state` 化。在 for 循环中,状态函数用状态作为参数进行调用,然后返回状态函数的值并成为一个新的状态函数。我们可以看到词法分析器作为 `emitter` 被传递到了状态函数中,不要紧张,我们之后将会看见词法分析器如何实现 `emitter` 接口的。从现在开始,我们仅仅需要记住我们的状态机是如何工作的:
**获取到当前状态,做一些事,运行到下一个状态。**
这样做的优势是什么呢?好了,首先,我们没有必要每次都去检测我们处于什么状态。那不是我们关心的。我们总是处于正确的地方。在我们的机器中需要做的唯一的事情就是运行状态函数知道我们遇到空的状态函数。
#### 并发地运行我们的机器
我们没有过多地谈论如何向客户端发送我们生成地 token,并且我认为这里就是恰当的时间了。这个想法就是我们将要运行词法分析器作为一个 Go 协程,附带着可能像是解析器样的客户端,这样两个独立的机器做它们的工作,无论什么时候,当词法分析器有新的东西时,客户端将会取到它并且做它们自己的工作。这种机制能够被 Go channel 所处理。
channel 是 Go 语言最伟大的特性之一并且确实很复杂,但是在我们的词法分析器中,它只是把数据传输到另外一个程序的一种方法,它可能正在完全独立的运行。
```go
type Lexer struct {
tokench chan Token
}
func NewLexer(input string) *Lexer {
l := &Lexer{
tokench: make(chan Token, 2),
}
go l.run(input)
return l
}
// emit passes an token back to the client.
func (l *Lexer) emit(t Token) {
l.tokench <- t
}
```
那就是我们的词法分析器的定义,它只有 token channel,当发送 token 到客户端的时候,将被使用。在 `NewLexer` 中我们可以看到使用 Go-routine 去启动运行机器。如何接受这些 token 在这篇文章中没有被涉及到,因为这是词法分析器组件,这个问题将在下一篇文章(解析器部分)中被涉及到。
### 怎样实现状态函数?
我们已经看到了我们的词法分析器如何被构建的大图,让我们深入一些:状态函数应该是长什么样的呢?
```go
func defaultStateFn(s *state, e emitter) stateFn {
switch ch := s.next(); {
case ch == '!':
if s.peek() == '=' {
s.next()
e.emit(s.cut(NOT_EQ))
} else {
e.emit(s.cut(Bang))
}
...
case ch == '+':
e.emit(s.cut(Plus))
...
case unicode.IsDigit(ch):
s.backup()
return numberStateFn
...
default:
e.emit(s.cut(Illegal))
}
return defaultStateFn
}
```
我引入 `defaultStateFn`,因为这个函数拥有所有的状态函数是如何工作的想法。首先,使用 `next()` 在状态中移动到下一个字符。还记得吗?状态中有输入的文本。然后根据字符我们决定如何去处理它。这里有许多的情况,但是我跳过了,这里写了四种情况,因为其他情况有就是其中一种相同的思考方式。
```go
case ch == '!':
if s.peek() == '=' {
s.next()
e.emit(s.cut(NOT_EQ))
} else {
e.emit(s.cut(Bang))
}
```
让我们假设我们读到的字符是‘ ! ’。但是只有 '!',我们不能生成 token。为什么呢?因为我们不知道 '!' 是单独的 '!',还是不等于符号 '!=' 的一部分。因此我们如何得知那种情况呢?我们应该读取从状态中读取一个字符,但是我们应该尽可能小心地看代码,我们没有用 `next` 而是用 `peek`。为什么不是 `next` ?因为在 '!' 字符的情况下仅仅是感叹号标记,这没有回去的路了。当然,我知道我们有回退一步的 `backup` 函数,我们可以用不同的方法实现它,但是我们认为这是风格问题。在读取字符之后,`cut` 在当前状态我们已经读取的的字符并且生成 token 然后发送。
```go
case ch == '+':
e.emit(s.cut(Plus))
```
在‘ + ’的情况下,加法字符。这种情况就非常简单了,因为这里没有其他的选择去不同地读取 - 我们还没有像 `++` 这种操作符 - 因此就剪切掉并且发送默认状态函数的返回。
```go
case unicode.IsDigit(ch):
s.backup()
return numberStateFn
```
如果接下来的字符是数字,怎么办呢?我们应该回退。为什么?因为如果读取的字符是数字,我们对于数字的选择应该采取不同的行为,不然我们就会出错,默认状态函数由于回退一个字符并且通过返回分析数字字符的 `numberStateFn`,我们才能恰当地处理数字字符。
```go
default:
e.emit(s.cut(Illegal))
```
如果读取的字符没有在我们的情况中被定义,我们应该做什么呢? Panic ?打印出出错信息?不,我们在词法分析器遇到没有被定义的字符的情况下的设计是生成 `Illegal` token 并且继续运行。
为什么我们像这样设计?当然,我们认为处理错误不是词法分析器的部分,因此传递这个责任给其他接收 token 的。通过这样做,我们可以保持简单,这里没有错误处理的代码,因此有更好的可读性,专注于它的工作。
就这样了!我们已经明白状态函数是如何基本地工作的了。在读取的字符不能充分得制作 token 的情况下就多读一个,如果充分了就生成 token 并且发送。有的情况下字符应该被区别处理然后回退,并且使用选择该字符的不同状态函数处理它。如果字符没有被定义在我们的字符集中,那么生成非法 token 并继续。
## 结论
所以在这篇文章中我们已经看到词法分析器如何被设计和工作。我们使用状态和动作去给给定的输入字符串做词法分析。伴随它的状态做出行为并继续到下一个状态。通过这样做,我们可以让我们的状态机保持简单和可扩展。
另外,使用 Go 协程同时运行我们的状态机。词法分析器可以独立于其客户端运行,且无论什么时候客户端需要从词法分析器获取 token,客户端可以从发送器推送的通道中获取生成的 token。
在下一篇文章中,我们将要介绍从词法分析器接收 tokens 的解析器并做它自己的工作 :)
via: https://medium.com/@14wnrkim/create-new-smartcontract-language-with-go-lexer-part-a5cdfca9b42e
作者:zeroFruit 译者:PotoYang 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





