背景
基于Kafka消息队列的两级协调调度架构
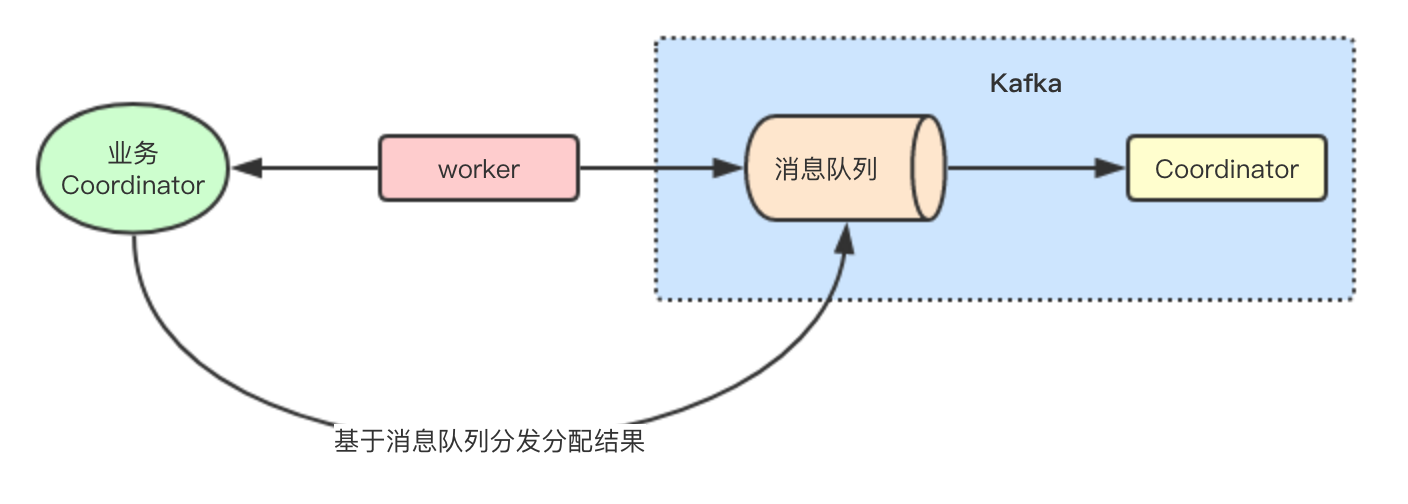
Kafka内部为了协调内部的consumer和kafka connector的工作实现了一个复制协议, 主要工作分为两个步骤:
通过worker(consumer或connect)获取自身的topic offset等元数据信息,交给kafka的broker完成Leader/Follower选举
worker Leader节点获取到kafka存储的partation和member信息,来进行二级分配,实现结合具体业务的负载均衡分配
从功能实现上两级调度,一级调度负责将Leader选举,二级调度则是worker节点完成每个成员的任务的分配
主要是学习这种架构设计思想,虽然这种方案场景非常有限
基于消息队列实现分布式协调设计
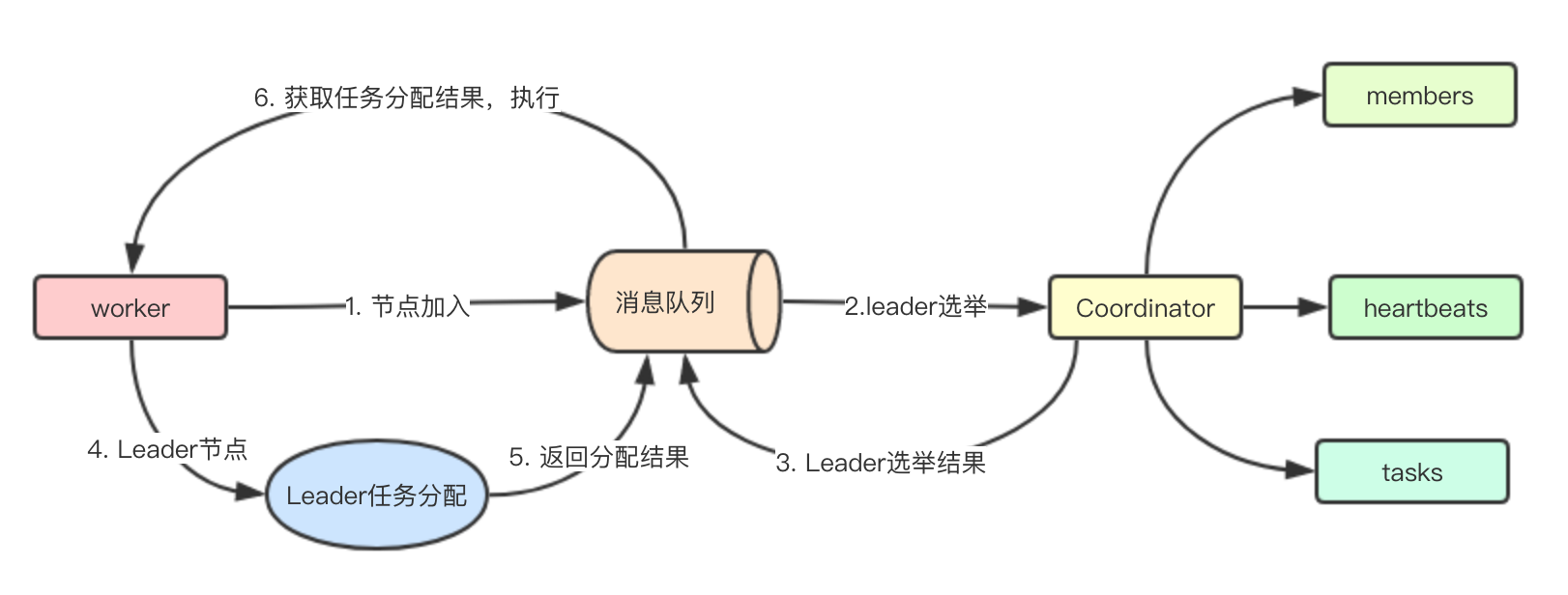
一级协调器设计:一级协调器主要是指的Coordinator部分,通过记录成员的元数据信息,来进行Leader选举,比如根据offset的大小来决定谁是Leader 二级协调器设计:二级协调器主要是指的Leader任务分配部分, worker节点获取到所有的任务和节点信息,就可以根据合适的算法来进行任务的分配,最终广播到消息队列
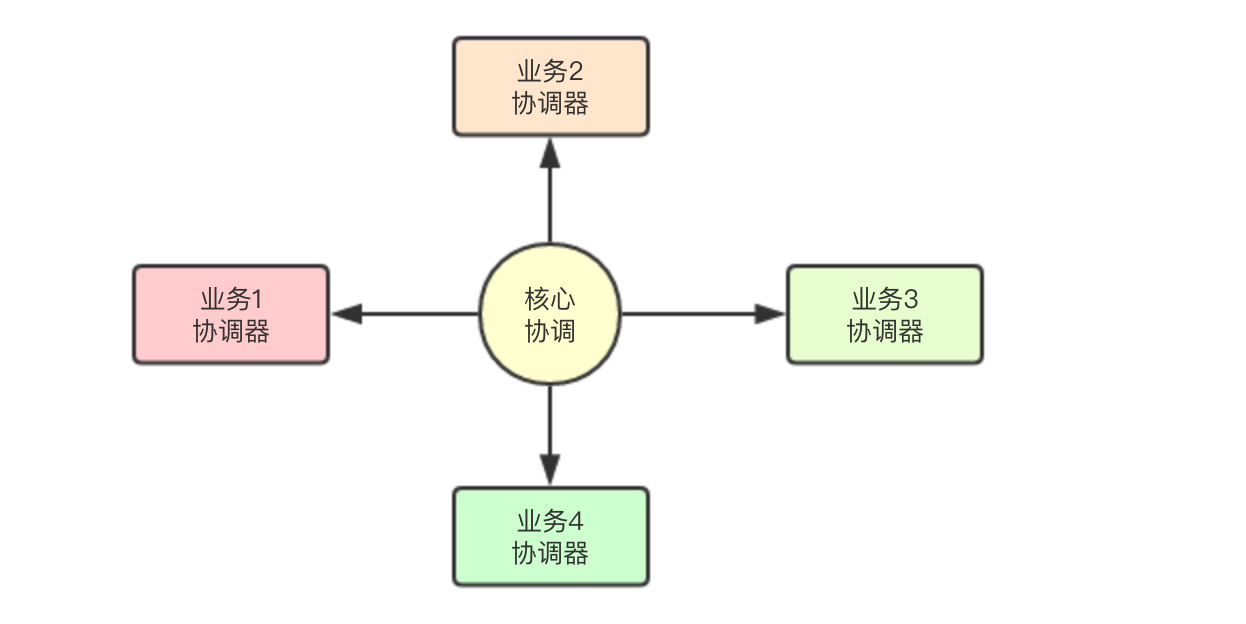
值得我们学习的地方, 通常在kafka这种场景下,如果要针对不同的业务实现统一调度,还是蛮麻烦的, 所以比如将具体任务的分配工作从架构中迁移出去, 在broker端只负责通用层的Leader选举即可, 将具体业务的分配工作,从主业务架构分离出去,由具体业务去实现
代码实现
核心设计
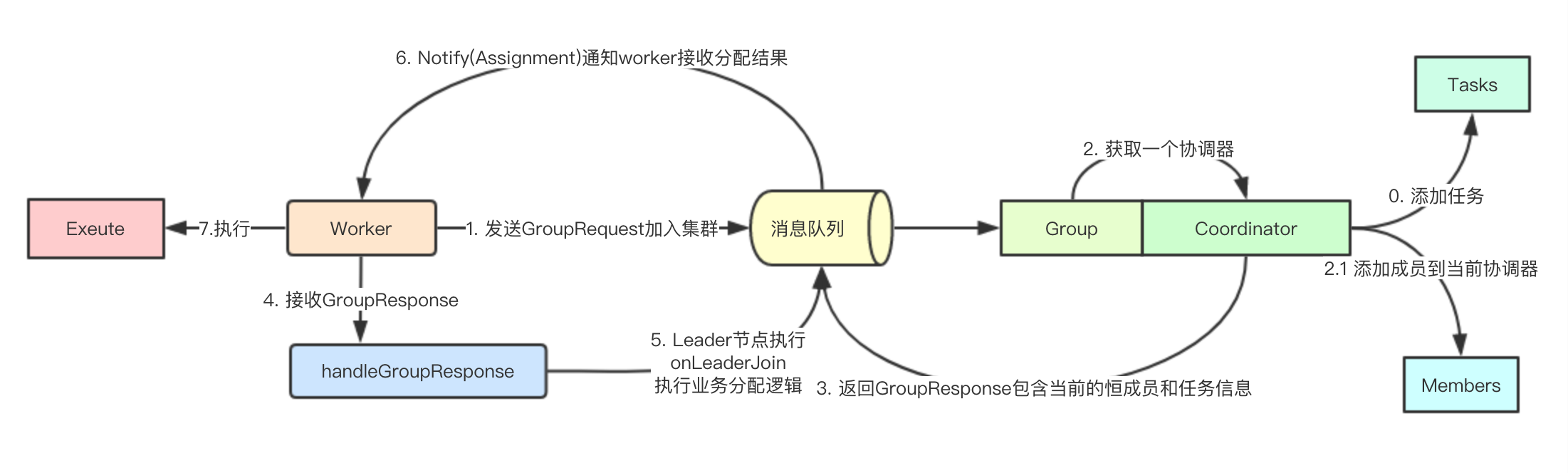
根据设计,我们抽象出: MemoryQueue、Worker、 Coordinator、GroupRequest、GroupResponse、Task、Assignment集合核心组件
MemoryQueue: 模拟消息队列实现消息的分发,充当kafka broker角色 Worker: 任务执行和具体业务二级协调算法 Coordinator: 位于消息队列内部的一个协调器,用于Leader/Follower选举 Task: 任务 Assignment: Coordnator根据任务信息和节点信息构建的任务分配结果 GroupRequest: 加入集群请求 GroupResponse: 响应信息
MemoryQueue
核心数据结构
// MemoryQueue 内存消息队列type MemoryQueue struct {
done chan struct{} queue chan interface{}
wg sync.WaitGroup
coordinator map[string]*Coordinator
worker map[string]*Worker
}其中coordinator用于标识每个Group组的协调器,为每个组都建立一个分配器
节点加入集群请求处理
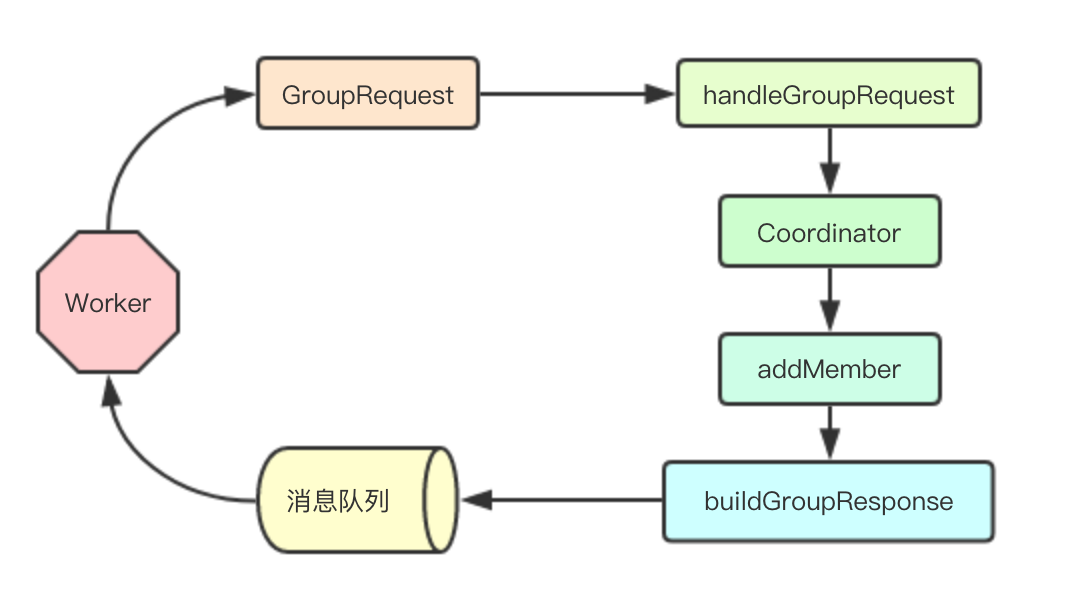
MemoryQueue 接收事件类型,然后根据事件类型进行分发,如果是GroupRequest事件,则分发给handleGroupRequest进行处理 handleGroupRequest内部先获取对应group的coordinator,然后根据当前信息buildGroupResponse发回消息队列
事件分发处理
func (mq *MemoryQueue) handleEvent(event interface{}) { switch event.(type) { case GroupRequest:
request := event.(GroupRequest)
mq.handleGroupRequest(&request) case Task:
task := event.(Task)
mq.handleTask(&task) default:
mq.Notify(event)
}
mq.wg.Done()
}加入Group组请求处理
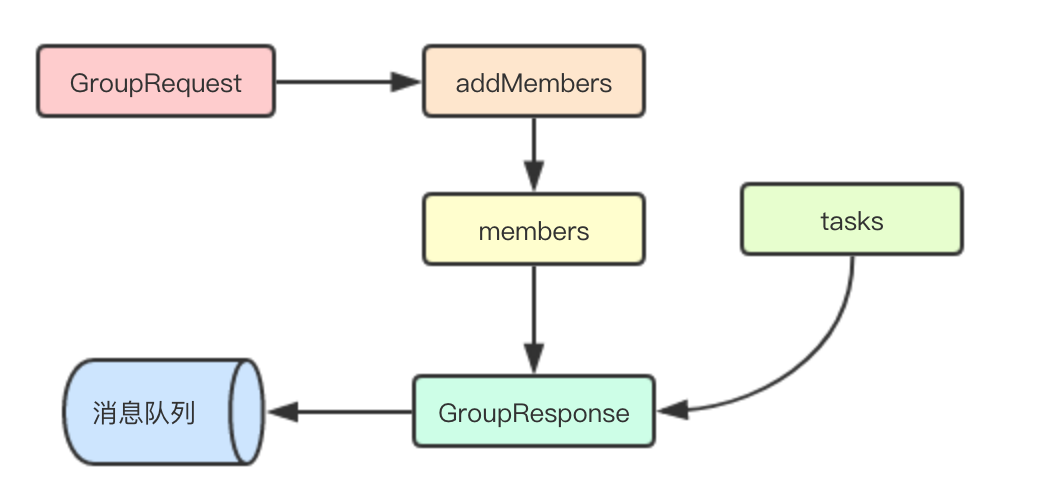
其中Coordnator会调用自己的getLeaderID方法,来根据当前组内的各成员的信息来选举一个Leader节点
// getGroupCoordinator 获取指定组的协调器func (mq *MemoryQueue) getGroupCoordinator(group string) *Coordinator {
coordinator, ok := mq.coordinator[group] if ok { return coordinator
}
coordinator = NewCoordinator(group)
mq.coordinator[group] = coordinator return coordinator
}
func (mq *MemoryQueue) handleGroupRequest(request *GroupRequest) {
coordinator := mq.getGroupCoordinator(request.Group)
exist := coordinator.addMember(request.ID, &request.Metadata) // 如果worker之前已经加入该组, 就不做任何操作
if exist { return
} // 重新构建请求信息
groupResponse := mq.buildGroupResponse(coordinator)
mq.send(groupResponse)
}
func (mq *MemoryQueue) buildGroupResponse(coordinator *Coordinator) GroupResponse { return GroupResponse{
Tasks: coordinator.Tasks,
Group: coordinator.Group,
Members: coordinator.AllMembers(),
LeaderID: coordinator.getLeaderID(),
Generation: coordinator.Generation,
Coordinator: coordinator,
}
}Coordinator
核心数据结构
// Coordinator 协调器type Coordinator struct {
Group string
Generation int
Members map[string]*Metadata
Tasks []string
Heartbeats map[string]int64
}Coordinator内部通过Members信息,来存储各个worker节点的元数据信息, 然后Tasks存储当前group的所有任务, Heartbeats存储workerd额心跳信息, Generation是一个分代计数器,每次节点变化都会递增
通过offset选举Leader
通过存储的worker的metadata信息,来进行主节点的选举
// getLeaderID 根据当前信息获取leader节点func (c *Coordinator) getLeaderID() string {
leaderID, maxOffset := "", 0
// 这里是通过offset大小来判定,offset大的就是leader, 实际上可能会更加复杂一些
for wid, metadata := range c.Members { if leaderID == "" || metadata.offset() > maxOffset {
leaderID = wid
maxOffset = metadata.offset()
}
} return leaderID
}Worker
核心数据结构
// Worker 工作者type Worker struct {
ID string
Group string
Tasks string
done chan struct{} queue *MemoryQueue
Coordinator *Coordinator
}worker节点会包含一个coordinator信息,用于后续向该节点进行心跳信息的发送
分发请求消息
worker接收到不同的事件类型,根据类型来进行处理, 其中handleGroupResponse负责接收到服务端Coordinator响应的信息,里面会包含leader节点和任务信息,由worker 来进行二级分配, handleAssign则是处理分配完后的任务信息
// Execute 接收到分配的任务进行请求执行func (w *Worker) Execute(event interface{}) { switch event.(type) { case GroupResponse:
response := event.(GroupResponse)
w.handleGroupResponse(&response) case Assignment:
assign := event.(Assignment)
w.handleAssign(&assign)
}
}GroupResponse根据角色类型进行后续业务逻辑
GroupResponse会将节点分割为两种:Leader和Follower, Leader节点接收到GroupResponse后需要继续进行分配任务,而Follower则只需要监听事件和发送心跳
func (w *Worker) handleGroupResponse(response *GroupResponse) { if w.isLeader(response.LeaderID) {
w.onLeaderJoin(response)
} else {
w.onFollowerJoin(response)
}
}Follower节点
Follower节点进行心跳发送
// onFollowerJoin 当前角色是followerfunc (w *Worker) onFollowerJoin(response *GroupResponse) {
w.Coordinator = response.Coordinator
go w.heartbeat()
}// heartbeat 发送心跳func (w *Worker) heartbeat() { // timer := time.NewTimer(time.Second)
// for {
// select {
// case <-timer.C:
// w.Coordinator.heartbeat(w.ID, time.Now().Unix())
// timer.Reset(time.Second)
// case <-w.done:
// return
// }
// }}Leader节点
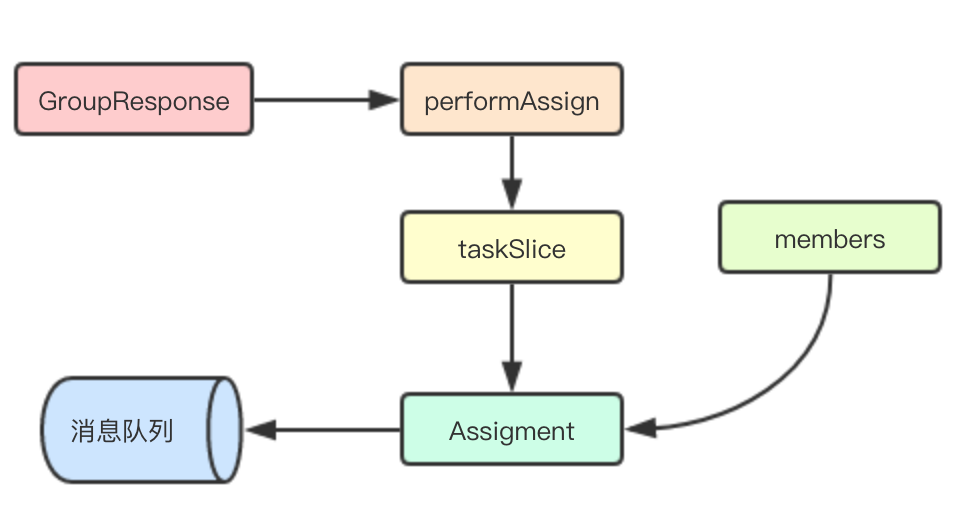
Leader节点这个地方我将调度分配分为两个步骤: 1)通过节点数和任务数将任务进行分片 2)将分片后的任务分配给各个节点,最终发送回队列
// onLeaderJoin 当前角色是leader, 执行任务分配并发送mqfunc (w *Worker) onLeaderJoin(response *GroupResponse) {
fmt.Printf("Generation [%d] leaderID [%s]\n", response.Generation, w.ID)
w.Coordinator = response.Coordinator
go w.heartbeat() // 进行任务分片
taskSlice := w.performAssign(response) // 将任务分配给各个worker
memerTasks, index := make(map[string][]string), 0
for _, name := range response.Members {
memerTasks[name] = taskSlice[index]
index++
} // 分发请求
assign := Assignment{LeaderID: w.ID, Generation: response.Generation, result: memerTasks}
w.queue.send(assign)
}// performAssign 根据当前成员和任务数func (w *Worker) performAssign(response *GroupResponse) [][]string {
perWorker := len(response.Tasks) / len(response.Members)
leftOver := len(response.Tasks) - len(response.Members)*perWorker
result := make([][]string, len(response.Members))
taskIndex, memberTaskCount := 0, 0
for index := range result { if index < leftOver {
memberTaskCount = perWorker + 1
} else {
memberTaskCount = perWorker
} for i := 0; i < memberTaskCount; i++ {
result[index] = append(result[index], response.Tasks[taskIndex])
taskIndex++
}
} 测试数据
启动一个队列,然后加入任务和worker,观察分配结果
// 构建队列
queue := NewMemoryQueue(10) queue.Start() // 发送任务
queue.send(Task{Name: "test1", Group: "test"}) queue.send(Task{Name: "test2", Group: "test"}) queue.send(Task{Name: "test3", Group: "test"}) queue.send(Task{Name: "test4", Group: "test"}) queue.send(Task{Name: "test5", Group: "test"}) // 启动worker, 为每个worker分配不同的offset观察是否能将leader正常分配
workerOne := NewWorker("test-1", "test", queue)
workerOne.start(1) queue.addWorker(workerOne.ID, workerOne)
workerTwo := NewWorker("test-2", "test", queue)
workerTwo.start(2) queue.addWorker(workerTwo.ID, workerTwo)
workerThree := NewWorker("test-3", "test", queue)
workerThree.start(3) queue.addWorker(workerThree.ID, workerThree)
time.Sleep(time.Second)
workerThree.stop()
time.Sleep(time.Second)
workerTwo.stop()
time.Sleep(time.Second)
workerOne.stop() queue.Stop()运行结果: 首先根据offset, 最终test-3位Leader, 然后查看任务分配结果, 有两个节点2个任务,一个节点一个任务, 然后随着worker的退出,又会进行任务的重新分配
Generation [1] leaderID [test-1] Generation [2] leaderID [test-2] Generation [3] leaderID [test-3] Generation [1] worker [test-1] run tasks: [test1||test2||test3||test4||test5] Generation [1] worker [test-2] run tasks: [] Generation [1] worker [test-3] run tasks: [] Generation [2] worker [test-1] run tasks: [test1||test2||test3] Generation [2] worker [test-2] run tasks: [test4||test5] Generation [2] worker [test-3] run tasks: [] Generation [3] worker [test-1] run tasks: [test1||test2] Generation [3] worker [test-2] run tasks: [test3||test4] Generation [3] worker [test-3] run tasks: [test5] Generation [4] leaderID [test-2] Generation [4] worker [test-1] run tasks: [test1||test2||test3] Generation [4] worker [test-2] run tasks: [test4||test5] Generation [5] leaderID [test-1] Generation [5] worker [test-1] run tasks: [test1||test2||test3||test4||test5]
总结
其实在分布式场景中,这种Leader/Follower选举,其实更多的是会选择基于AP模型的consul、etcd、zk等, 本文的这种设计,与kafka自身的业务场景由很大的关系, 后续有时间,还是继续看看别的设计, 从kafka connet借鉴的设计,就到这了
最后也给大家推荐一个架构技术交流群:714827309 ,里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析
,高并发、高性能、分布式、微服务架构的原理,JVM性能优化这些成为架构师必备的知识体系。还能领取免费的学习资源,相信对于已经工作
和遇到技术瓶颈的码友,在这个群里会有你需要的内容。
点击链接加入群聊【JAVA高级架构技术交流】:https://jq.qq.com/?_wv=1027&k=51OhGuo
有疑问加站长微信联系(非本文作者)



