
摘要
本文旨在对如何用 Go 语言构建 LL(1) 文法的解析器 ——此例用来解析 SQL 请求——作出简要的介绍。只需要读者具有极少的编程能力(函数、结构体、条件语句和 for 循环)。
如果你想直接跳过文章直接看结果,这里是完成后的解析器代码仓库:
https://github.com/marianogappa/sqlparser
为了简化而放弃的内容
我们不会实现一些 SQL 中的复杂特性,包括子选择、函数、复杂的嵌套表达式等。但是这些特性都可以很快使用我们的策略来实现。
简要的理论介绍
一个语法分析器由两部分组成:
词法分析器
我们用例子来定义,当我们说把下面的查询 “切分成记号(token)“:
SELECT id, name FROM 'users.csv'
实际上是要把当中的 “记号” 都提取出来。记号切分器处理的结果就像下面这样:
[]string{"SELECT", "id", ",", "name", "FROM", "'users.csv'"}
语法分析器
在这部分里,我们实际上要观察这些记号,确保它们有意义,然后解释成若干结构体(struct)。一些应用会使用这些结构体,例如执行查询,或者给查询添加颜色高亮。这些结构体把查询用一种方便应用使用的方式表示出来。这步之后,我们得到像是这样的东西:
query {
Type: "Select",
TableName: "users.csv",
Fields: ["id", "name"],
}
在解析过程中,会有非常多的失败情况。所以为了方便,一般把这两步(词法分析和语法分析)放在一起做,一旦出错就停止解析。
策略
我们像下面这样定义解释器 parser。
type parser struct {
sql string // 待解析的查询
i int // 当前所在查询字符串中的位置
query query.Query // 将要构建的 '' 查询结构体 ''
step step // 这是什么呢?往下看
}
// 主函数返回一个 '' 查询结构体 '' 或者一个错误
func (p *parser) Parse() (query.Query, error) {}
// 返回解析的下一个记号(token)
func (p *parser) peek() (string) {}
// 与 peek 相同,同时 parser 的 i 索引往前进
func (p *parser) pop() (string) {}
直觉上来说,在解析的过程中,我们要先 “偷看”(peek)第一个记号。在基本的 SQL 语法中,只有少数几个合法的记号:SELECT、UPDATE、DELETE 等,任何其他内容都是错误的。这部分代码看起来是这样的:
switch strings.ToUpper(parser.peek()) {
case "SELECT":
parser.query.type = "SELECT" // 开始构建此类型 "查询结构体"
parser.pop()
// TODO 继续 SELECT 查询的解析
case "UPDATE":
// TODO 处理 UPDATE
// TODO 其他情况
default:
return parser.query, fmt.Errorf("invalid query type")
}
接下来主要就是把这些 TODO 和边界填完。然而,勤奋的读者很快就会发现,完成解析整个 SELECT 查询的过程中,代码会迅速变得混乱不堪。更不用说我们还有很多中查询要解析。所以,我们需要一些有益的结构(来避免这种事情发生)。
有限状态自动机
有限状态自动机 是一个非常有意思的话题,但这里不是帮你拿计算机科学学位的地方,所以我们只关注需要的内容。
在我们解析的过程中,在每个点都只有少数几个记号是合法的。找到这样合法的记号之后,又到了一个新的节点,此时另一些记号是合法的。如此往复,直到完成整个查询的解析。我们可以将节点的关系用一个有向图来可视化:
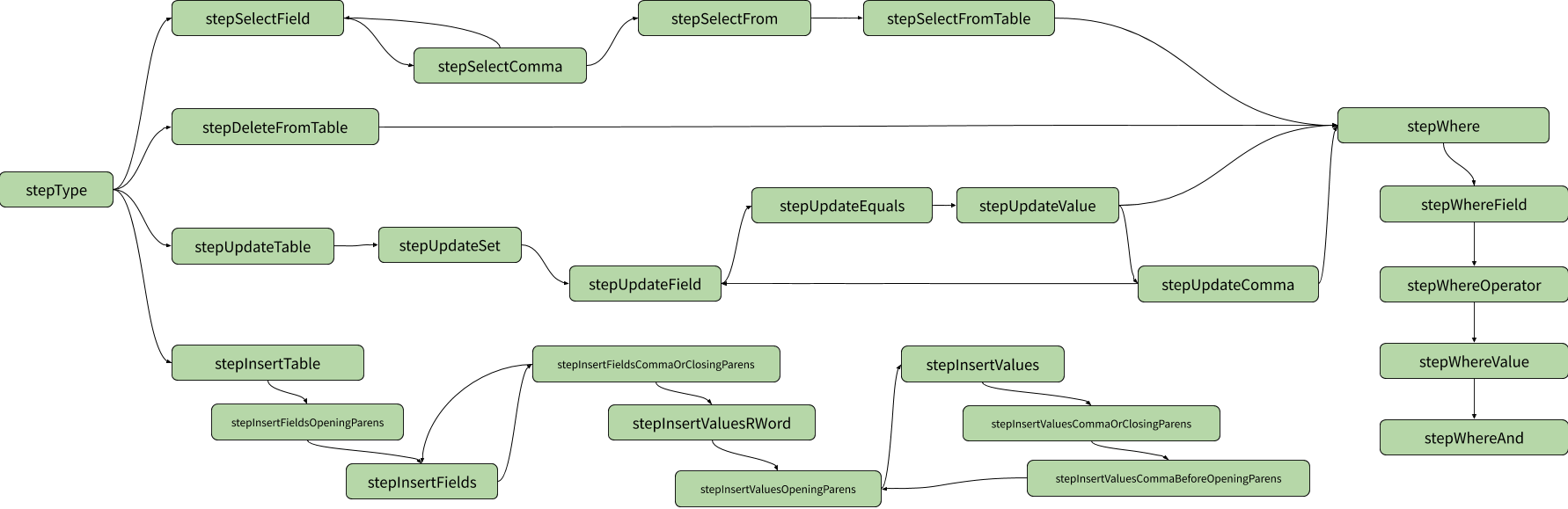
节点之间的转换,可以通过更简单的一张表来表示:
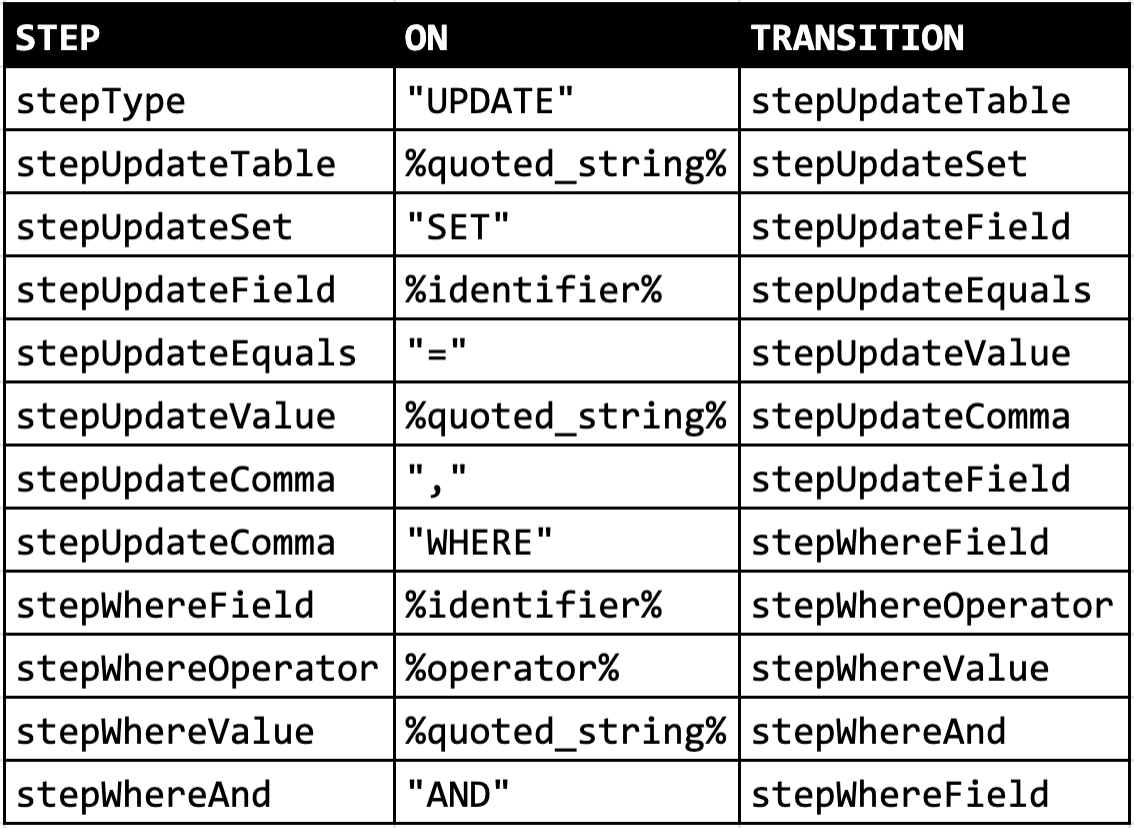
我们可以直接将这张表翻译成一个巨大的 switch 语句。现在我们可以使用之前那个鬼鬼祟祟的 parser.step 属性了:
func (p *parser) Parse() (query.Query, error) {
parser.step = stepType // 初始的 step
for parser.i < len(parser.sql) {
nextToken := parser.peek()
switch parser.step {
case stepType:
switch nextToken {
case UPDATE:
parser.query.type = "UPDATE"
parser.step = stepUpdateTable
// TODO 其他查询的情况
}
case stepUpdateSet:
// ...
case stepUpdateField:
// ...
case stepUpdateComma:
// ...
}
parser.pop()
}
return parser.query, nil
}
这就好了!注意,有些步骤(step)会在某些条件下回到之前的步骤,例如在 SELECT 定义里的逗号。这种策略可以很好地扩展到基本解释器。然而随着语法变得越加复杂,状态的数目会急剧增长,写这个代码会显得很乏味。所以我建议边写代码边测试,而不是写完再测。
Peek() 的实现
记得我们之前需要实现 peek() 和 pop(),因为他们的工作基本上是相同的,所以用一个辅助函数来防止重复。另外,为防获取到空白字符,pop() 需要进一步前移索引。
func (p *parser) peek() string {
peeked, _ := p.peekWithLength()
return peeked
}
func (p *parser) pop() string {
peeked, len := p.peekWithLength()
p.i += len
p.popWhitespace()
return peeked
}
func (p *parser) popWhitespace() {
for ; p.i < len(p.sql) && p.sql[p.i] == ' '; p.i++ {
}
}
下面是一个我们可能获取到的记号列表:
var reservedWords = []string{
"(", ")", ">=", "<=", "!=", ",", "=", ">", "<",
"SELECT", "INSERT INTO", "VALUES", "UPDATE",
"DELETE FROM", "WHERE", "FROM", "SET",
}
除此之外,我们可能会经过用引号扩起来的字符串,或者普通标识符(也就是字段的名字)。下面是一个完整的 peekWithLength() 的实现。
func (p *parser) peekWithLength() (string, int) {
if p.i >= len(p.sql) {
return "", 0
}
for _, rWord := range reservedWords {
token := p.sql[p.i:min(len(p.sql), p.i+len(rWord))]
upToken := strings.ToUpper(token)
if upToken == rWord {
return upToken, len(upToken)
}
}
if p.sql[p.i] == '\'' { // 用引号扩起来的字符串
return p.peekQuotedStringWithLength()
}
return p.peekIdentifierWithLength()
}
剩下的函数都是很简单的,这里留给读者做练习。如果你对这些感到好奇,在摘要一节里的链接有全部的代码实现。这里就迂回一些,不再写出这个链接了。
最后的确认
解析器可能在完成一整个查询之前就遇到了字符串末尾。所以最好实现一个 parser.validata() 函数,用来检查一下生成的 “查询” 结构体。这个函数在生成的查询不完整,或者还有其他错误的情况下返回一个错误对象(error)。
测试
Go 语言的表格驱动测试模式,在我们的例子里也很性感。
type testCase struct {
Name string // 描述测试
SQL string // 输入的 SQL,例如 "SELECT a FROM 'b'"
Expected query.Query // 查询的预期的结果
Err error // 捕获的错误
}
测试例子:
ts := []testCase{
{
Name: "empty query fails",
SQL: "",
Expected: query.Query{},
Err: fmt.Errorf("query type cannot be empty"),
},
{
Name: "SELECT without FROM fails",
SQL: "SELECT",
Expected: query.Query{Type: query.Select},
Err: fmt.Errorf("table name cannot be empty"),
},
...
像这样运行测试:
for _, tc := range ts {
t.Run(tc.Name, func(t *testing.T) {
actual, err := Parse(tc.SQL)
if tc.Err != nil && err == nil {
t.Errorf("Error should have been %v", tc.Err)
}
if tc.Err == nil && err != nil {
t.Errorf("Error should have been nil but was %v", err)
}
if tc.Err != nil && err != nil {
require.Equal(t, tc.Err, err, "Unexpected error")
}
if len(actual) > 0 {
require.Equal(t, tc.Expected, actual[0],
"Query didn't match expectation")
}
})
}
我用了 testify 这个包,因为它会在查询结构体不一致时输出不同在哪里。
更进一步
本文的实验适合:
- 学习 LL(1) 解释器算法。
- 不依赖任何东西,解析自定义的简单语法。
然而,这个方法很乏味,而且有局限性。想一想如何解析任意的复杂组合表达式(例如 sqrt(a) = (1 * (2 + 3)))。
想要一个更强大的解释器模型的话,可以看看解析器组合子。goyacc 是个流行的 Go 语言实现。
我还推荐 Rob Pike 在 Lexical Scanning 上有趣的演讲。
而递归下降解析 则是另一种解析手段。
为什么写这个
最近我打算把我的数据集中到一个 CSV 仓库里。这让我有了一个从打造增删改查 数据的用户接口的角度,学习 React 的机会。当我想要设计在前端和后端之间传递增删改查操作的接口时,我发现 SQL 是一个很自然的语言(而且我已经很了解它了)。
虽然有不少用 SQL 读取 CSV 的的库,但是好像对写操作的支持并不多(特别是数据定义语句)。一个同事建议我把文件上传到 SQLite 内存数据库里,然后运行 SQL 再导出 CSV。这是一个蛮好的方案,因为我并不是很关心效率。最后,我问自己:你不是总想写个 SQL 的解释器吗?这个能有多难呢?
结果发现,写一个(基本的)解释器是很简单的。如果没有一个尽可能简单的教程来指导,这个工作还是可能让人望而怯步。
我希望这是一个让你不再害怕的教程,KISS。
via: https://marianogappa.github.io/software/2019/06/05/lets-build-a-sql-parser-in-go/
作者:Mariano Gappa 译者:plus7wist 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




