转载:https://github.com/astaxie/build-web-application-with-golang/blob/master/zh/02.3.md
函数
函数是Go里面的核心设计,它通过关键字func来声明,它的格式如下:
func funcName(input1 type1, input2 type2) (output1 type1, output2 type2) {
//这里是处理逻辑代码
//返回多个值
return value1, value2
}
上面的代码我们看出
- 关键字
func用来声明一个函数funcName - 函数可以有一个或者多个参数,每个参数后面带有类型,通过
,分隔 - 函数可以返回多个值
- 上面返回值声明了两个变量
output1和output2,如果你不想声明也可以,直接就两个类型 - 如果只有一个返回值且不声明返回值变量,那么你可以省略 包括返回值 的括号
- 如果没有返回值,那么就直接省略最后的返回信息
- 如果有返回值, 那么必须在函数的外层添加return语句
下面我们来看一个实际应用函数的例子(用来计算Max值)
package main
import "fmt"
// 返回a、b中最大值.
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
x := 3
y := 4
z := 5
max_xy := max(x, y) //调用函数max(x, y)
max_xz := max(x, z) //调用函数max(x, z)
fmt.Printf("max(%d, %d) = %d\n", x, y, max_xy)
fmt.Printf("max(%d, %d) = %d\n", x, z, max_xz)
fmt.Printf("max(%d, %d) = %d\n", y, z, max(y,z)) // 也可在这直接调用它
}
上面这个里面我们可以看到max函数有两个参数,它们的类型都是int,那么第一个变量的类型可以省略(即
a,b int,而非 a int, b int),默认为离它最近的类型,同理多于2个同类型的变量或者返回值。同时我们注意到它的返回值就是一个类型,这个就是省略写法。
多个返回值
Go语言比C更先进的特性,其中一点就是函数能够返回多个值。
我们直接上代码看例子
package main
import "fmt"
//返回 A+B 和 A*B
func SumAndProduct(A, B int) (int, int) {
return A+B, A*B
}
func main() {
x := 3
y := 4
xPLUSy, xTIMESy := SumAndProduct(x, y)
fmt.Printf("%d + %d = %d\n", x, y, xPLUSy)
fmt.Printf("%d * %d = %d\n", x, y, xTIMESy)
}
上面的例子我们可以看到直接返回了两个参数,当然我们也可以命名返回参数的变量,这个例子里面只是用了两个类型,我们也可以改成如下这样的定义,然后返回的时候不用带上变量名,因为直接在函数里面初始化了。但如果你的函数是导出的(首字母大写),官方建议:最好命名返回值,因为不命名返回值,虽然使得代码更加简洁了,但是会造成生成的文档可读性差。
func SumAndProduct(A, B int) (add int, Multiplied int) {
add = A+B
Multiplied = A*B
return
}
变参
Go函数支持变参。接受变参的函数是有着不定数量的参数的。为了做到这点,首先需要定义函数使其接受变参:
func myfunc(arg ...int) {}
arg ...int告诉Go这个函数接受不定数量的参数。注意,这些参数的类型全部是int。在函数体中,变量arg是一个int的slice:
for _, n := range arg {
fmt.Printf("And the number is: %d\n", n)
}
传值与传指针
当我们传一个参数值到被调用函数里面时,实际上是传了这个值的一份copy,当在被调用函数中修改参数值的时候,调用函数中相应实参不会发生任何变化,因为数值变化只作用在copy上。
为了验证我们上面的说法,我们来看一个例子
package main
import "fmt"
//简单的一个函数,实现了参数+1的操作
func add1(a int) int {
a = a+1 // 我们改变了a的值
return a //返回一个新值
}
func main() {
x := 3
fmt.Println("x = ", x) // 应该输出 "x = 3"
x1 := add1(x) //调用add1(x)
fmt.Println("x+1 = ", x1) // 应该输出"x+1 = 4"
fmt.Println("x = ", x) // 应该输出"x = 3"
}
看到了吗?虽然我们调用了add1函数,并且在add1中执行a
= a+1操作,但是上面例子中x变量的值没有发生变化
理由很简单:因为当我们调用add1的时候,add1接收的参数其实是x的copy,而不是x本身。
那你也许会问了,如果真的需要传这个x本身,该怎么办呢?
这就牵扯到了所谓的指针。我们知道,变量在内存中是存放于一定地址上的,修改变量实际是修改变量地址处的内存。只有add1函数知道x变量所在的地址,才能修改x变量的值。所以我们需要将x所在地址&x传入函数,并将函数的参数的类型由int改为*int,即改为指针类型,才能在函数中修改x变量的值。此时参数仍然是按copy传递的,只是copy的是一个指针。请看下面的例子
package main
import "fmt"
//简单的一个函数,实现了参数+1的操作
func add1(a *int) int { // 请注意,
*a = *a+1 // 修改了a的值
return *a // 返回新值
}
func main() {
x := 3
fmt.Println("x = ", x) // 应该输出 "x = 3"
x1 := add1(&x) // 调用 add1(&x) 传x的地址
fmt.Println("x+1 = ", x1) // 应该输出 "x+1 = 4"
fmt.Println("x = ", x) // 应该输出 "x = 4"
}
这样,我们就达到了修改x的目的。那么到底传指针有什么好处呢?
- 传指针使得多个函数能操作同一个对象。
- 传指针比较轻量级 (8bytes),只是传内存地址,我们可以用指针传递体积大的结构体。如果用参数值传递的话, 在每次copy上面就会花费相对较多的系统开销(内存和时间)。所以当你要传递大的结构体的时候,用指针是一个明智的选择。
- Go语言中
string,slice,map这三种类型的实现机制类似指针,所以可以直接传递,而不用取地址后传递指针。(注:若函数需改变slice的长度,则仍需要取地址传递指针)
defer
Go语言中有种不错的设计,即延迟(defer)语句,你可以在函数中添加多个defer语句。当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回。特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题。如下代码所示,我们一般写打开一个资源是这样操作的:
func ReadWrite() bool {
file.Open("file")
// 做一些工作
if failureX {
file.Close()
return false
}
if failureY {
file.Close()
return false
}
file.Close()
return true
}
我们看到上面有很多重复的代码,Go的defer有效解决了这个问题。使用它后,不但代码量减少了很多,而且程序变得更优雅。在defer后指定的函数会在函数退出前调用。
func ReadWrite() bool {
file.Open("file")
defer file.Close()
if failureX {
return false
}
if failureY {
return false
}
return true
}
如果有很多调用defer,那么defer是采用后进先出模式,所以如下代码会输出4
3 2 1 0
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
函数作为值、类型
在Go中函数也是一种变量,我们可以通过type来定义它,它的类型就是所有拥有相同的参数,相同的返回值的一种类型
type typeName func(input1 inputType1 , input2 inputType2 [, ...]) (result1 resultType1 [, ...])
函数作为类型到底有什么好处呢?那就是可以把这个类型的函数当做值来传递,请看下面的例子
package main
import "fmt"
type testInt func(int) bool // 声明了一个函数类型
func isOdd(integer int) bool {
if integer%2 == 0 {
return false
}
return true
}
func isEven(integer int) bool {
if integer%2 == 0 {
return true
}
return false
}
// 声明的函数类型在这个地方当做了一个参数
func filter(slice []int, f testInt) []int {
var result []int
for _, value := range slice {
if f(value) {
result = append(result, value)
}
}
return result
}
func main(){
slice := []int {1, 2, 3, 4, 5, 7}
fmt.Println("slice = ", slice)
odd := filter(slice, isOdd) // 函数当做值来传递了
fmt.Println("Odd elements of slice are: ", odd)
even := filter(slice, isEven) // 函数当做值来传递了
fmt.Println("Even elements of slice are: ", even)
}
函数当做值和类型在我们写一些通用接口的时候非常有用,通过上面例子我们看到testInt这个类型是一个函数类型,然后两个filter函数的参数和返回值与testInt类型是一样的,但是我们可以实现很多种的逻辑,这样使得我们的程序变得非常的灵活。
Panic和Recover
Go没有像Java那样的异常机制,它不能抛出异常,而是使用了panic和recover机制。一定要记住,你应当把它作为最后的手段来使用,也就是说,你的代码中应当没有,或者很少有panic的东西。这是个强大的工具,请明智地使用它。那么,我们应该如何使用它呢?
Panic
是一个内建函数,可以中断原有的控制流程,进入一个令人恐慌的流程中。当函数
F调用panic,函数F的执行被中断,但是F中的延迟函数会正常执行,然后F返回到调用它的地方。在调用的地方,F的行为就像调用了panic。这一过程继续向上,直到发生panic的goroutine中所有调用的函数返回,此时程序退出。恐慌可以直接调用panic产生。也可以由运行时错误产生,例如访问越界的数组。
Recover
是一个内建的函数,可以让进入令人恐慌的流程中的
goroutine恢复过来。recover仅在延迟函数中有效。在正常的执行过程中,调用recover会返回nil,并且没有其它任何效果。如果当前的goroutine陷入恐慌,调用recover可以捕获到panic的输入值,并且恢复正常的执行。
下面这个函数演示了如何在过程中使用panic
var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}
下面这个函数检查作为其参数的函数在执行时是否会产生panic:
func throwsPanic(f func()) (b bool) {
defer func() {
if x := recover(); x != nil {
b = true
}
}()
f() //执行函数f,如果f中出现了panic,那么就可以恢复回来
return
}
main函数和init函数
Go里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package
main)。这两个函数在定义时不能有任何的参数和返回值。虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
Go程序会自动调用init()和main(),所以你不需要在任何地方调用这两个函数。每个package中的init函数都是可选的,但package
main就必须包含一个main函数。
程序的初始化和执行都起始于main包。如果main包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下图详细地解释了整个执行过程:
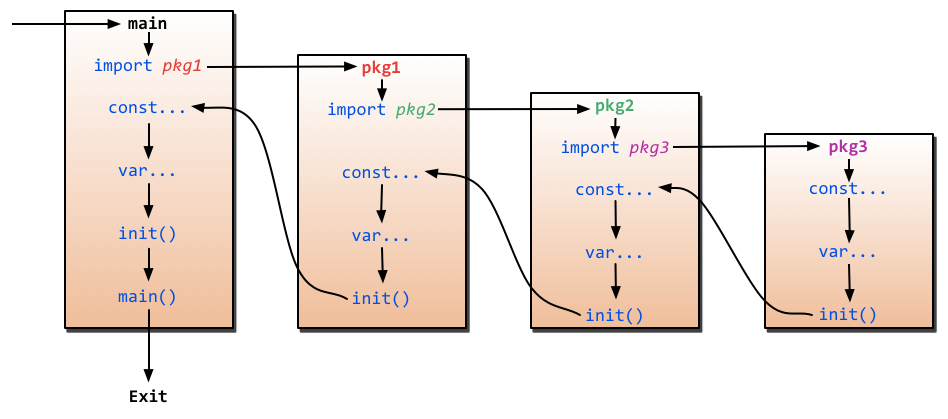
图2.6 main函数引入包初始化流程图
import
我们在写Go代码的时候经常用到import这个命令用来导入包文件,而我们经常看到的方式参考如下:
import(
"fmt"
)
然后我们代码里面可以通过如下的方式调用
fmt.Println("hello world")
上面这个fmt是Go语言的标准库,其实是去GOROOT环境变量指定目录下去加载该模块,当然Go的import还支持如下两种方式来加载自己写的模块:
-
相对路径
import “./model” //当前文件同一目录的model目录,但是不建议这种方式来import
-
绝对路径
import “shorturl/model” //加载gopath/src/shorturl/model模块
上面展示了一些import常用的几种方式,但是还有一些特殊的import,让很多新手很费解,下面我们来一一讲解一下到底是怎么一回事
-
点操作
我们有时候会看到如下的方式导入包
import( . "fmt" )这个点操作的含义就是这个包导入之后在你调用这个包的函数时,你可以省略前缀的包名,也就是前面你调用的fmt.Println("hello world")可以省略的写成Println("hello world")
-
别名操作
别名操作顾名思义我们可以把包命名成另一个我们用起来容易记忆的名字
import( f "fmt" )别名操作的话调用包函数时前缀变成了我们的前缀,即f.Println("hello world")
-
_操作
这个操作经常是让很多人费解的一个操作符,请看下面这个import
import ( "database/sql" _ "github.com/ziutek/mymysql/godrv" )_操作其实是引入该包,而不直接使用包里面的函数,而是调用了该包里面的init函数。

