
这是 Benjamin Manes 的讲座文章,他曾在谷歌担任工程师,现在正在 Vector 担任 CTO 职务。
前一篇文章描述了 Caffeine 使用的缓存算法,特别是淘汰算法和并发模型。我们还对淘汰算法进行了改进,并探索了一种新的到期方法。
淘汰策略
Window TinyLFU(W-TinyLFU)算法将策略分为三部分:准入窗口、频率滤波器和主区域。通过使用一个紧凑的流行度描述(sterch),以较小的开销对历史频率进行保留和查找。这样就可以快速丢弃不太可能再次使用的新数据,避免主要区域受到缓存污染。准入窗口为短期突发数据提供了一个小区域,避免当一个数据频繁访问时,出现缓存失效的问题。
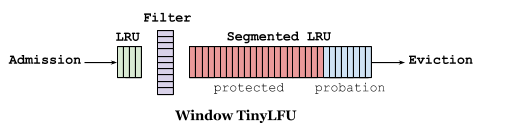
类似数据库,搜索,分析这种负载比较重的系统,这个设计结构表现的比较好。这些情况时频率偏好的,使用一个较小的准入窗口就可以进行有效的过滤。但较小的窗口对于工作队列和事件流等不同时间场景的处理模式不太合适。在一些系统中,访问模式随时间进行变化,例如缓存在白天为活跃用户提供支持,夜间对批处理任务提供缓存,因此没有相对固定的静态配置内容。
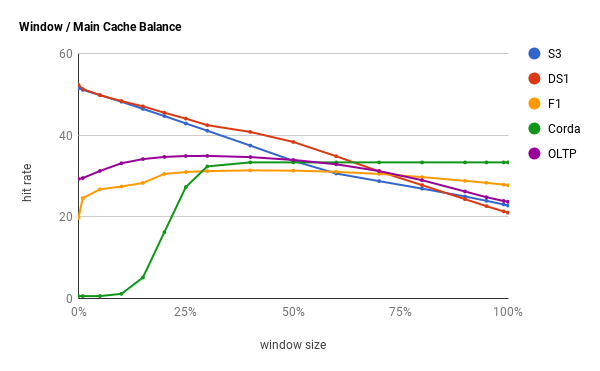
命中率曲线既展示了启发式设置的挑战,也给出解决方案的提示。通过使用爬坡算法的优化技术,自适应缓存可以使曲线走向其峰值。通过对命中率进行采样并选择移动方向来完成优化。当前一个方向导致命中率增加时,它继续前进,否则它会转换方向。最终,缓存将围绕最佳配置振荡,因此逐渐缩短步长,可以收敛到最佳值。当命中率变化百分比非常大的时候,此过程会重新执行一次,因为较大的命中率变化说明底层工作负载已经更改。
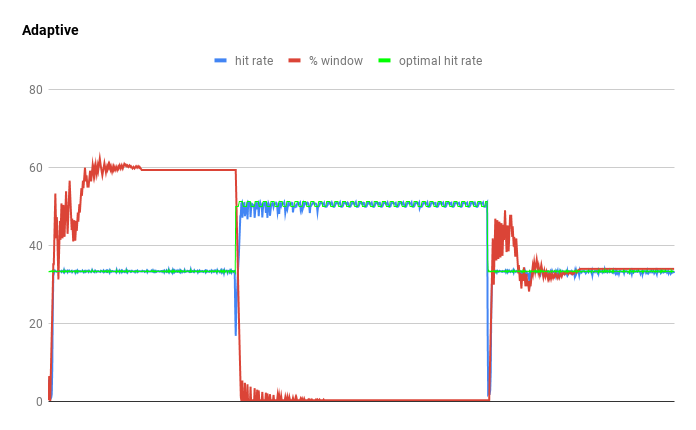
我们可以通过连接近期偏好和频率偏好数据来看到这一点(区块链挖掘和分析循环)。准入窗口配置为 1%,以频率偏好启动缓存。近期偏好数据使窗口增大并达到 LRU 的命中率。当频率偏好数据达到时,发生了命中率崩溃,缓存将准入窗口收缩至零。最后,近期偏好数据再次进入缓存,并触发自适应。最终的整体命中率为 39.6%,仅略低于最佳的 40.3%。所有其他测试的缓存策略命中率都在 20% 一下,包括 ARC,LIRS 和静态 W-TinyLFU 策略。
过期策略
以前,由于更高级的支持正在开发中,因此仅简单提到了过期。典型的方法是使用 O(lg n) 优先级队列来维护顺序,或使用死条目污染缓存,并依赖最大大小策略来最终淘汰它们。Caffeine 使用均摊的 O(1) 时间复杂度算法,从简单的固定策略开始,然后添加可变策略。
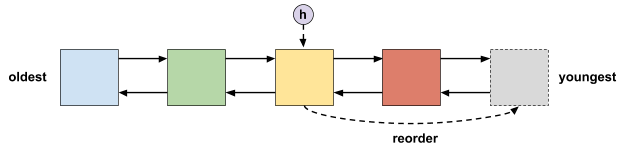
固定的过期策略是指对每个项目采用相同的处理方式,例如设置十分钟的有效时间设置。在这种情况下,我们可以使用有时间限制的 LRU 列表,其中头部是最旧的项目,尾部是最新的。当项目的到期时间被重置时,该项目被移动到尾部,这个操作可以通过将列表指针嵌入其中来高效的执行。在淘汰时,因为头部存储的是最旧的项目,我们可以根据需求对项目进行轮询。这样可以支持顺序读写策略,但仅限于固定的过期时间。
可变的到期策略更具挑战性,因为每个条目的评估方式都不相同。当过期策略在缓存外部时,通常会发生这种情况,例如来自第三方资源的 http 头的过期标志。这需要排序,但由于分片计时策略的独创性,可以使用散列而不是比较来完成排序。
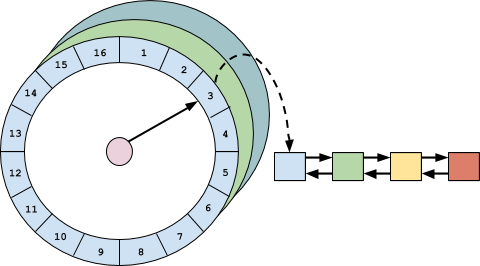
时间轮是由多个双向链表组成的数组,每个双向列表代表一个粗略的时间跨度。项目被散列到相应的存储桶,将其按粗略排序的顺序排列。通过使用多个时间轮,可以表示更大的时间范围,例如天,小时,分钟和秒。当上层时间轮转动时,前一个存储桶被冲到下层的时间轮,并且这些项目被重新三列并存储到相应的位置。当最低级别的时间轮转动时,前一个存储桶中的项目被逐出。由于使用了散列和级联,此策略在实现了 O(1)均摊时间复杂度,并提供了出色的性能。
结论
Caffeine 是一个开源的 Java 缓存库。本文和上一篇文章讨论的技术可以应用于任何语言,并且实现起来非常简单。除了我们上一篇文章中所感谢的人员,我还要特别感谢以下人员做出的贡献,Ohad Eytan,Julian Vassev,ViktorSzathmáry,Charles Allen,William Burns,Christian Sailer,Rick Parker,Branimir Lambov,Benedict Smith,Martin Grajcar,Kurt Kluever,Johno Crawford,Ken Dombeck 和 James Baker
via: http://highscalability.com/blog/2019/2/25/design-of-a-modern-cachepart-deux.html
作者:Benjamin Manes 译者:Althen 校对:JYSDeveloper
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




