
这是两部分系列文章中的第一部分,该文章采用教程的方式来探讨 Go 编译器。Go 编译器复杂而庞大,需要一本书才可能描述清楚,所以这个系列文章旨在提供一个快速而深度优先的方式进入学习。我计划在以后会写更多关于编译器领域的描述文章。
我们会修改 Go 编译器来增加一个新的(玩具性质)语言特性,并构建一个经过修改的编译器进行使用。
## 任务 —— 增加新的语句
很多语言都有 `while` 语句,在 Go 中对应的是 `for`:
```go
for <some-condition> {
<loop body>
}
```
增加 `while` 语句是比较简单的,因此 —— 我们只需简单将其转换为 `for` 语句。所以我选择了一个稍微有点挑战性的任务,增加 `until`。`until` 语句和 `while` 语句是一样的,只是有了条件判断。例如下面的代码:
```go
i := 4
until i == 0 {
i--
fmt.Println("Hello, until!")
}
```
等价于:
```go
i := 4
for i != 0 {
i--
fmt.Println("Hello, until!")
}
```
事实上,我们甚至可以像下面代码一样,在循环声明中使用一个初始化语句:
```go
until i := 4; i == 0 {
i--
fmt.Println("Hello, until!")
}
```
我们的目标是支持这个特性。
特别声明 —— 这只是一个玩具性的探索。我觉得在 Go 中添加 `until` 并不好,因为 Go 的极简主义设计思想本身就是非常正确的理念。
## Go 编译器的高级结构
默认情况下,Go 编译器(`gc`)是以相当传统的结构来设计的,如果你使用过其他编译器,你应该很快就能熟悉它:
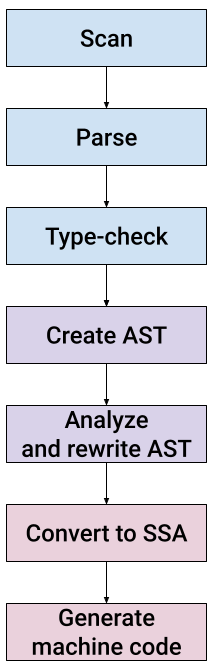
Go 仓库中相对路径的根目录下,编译器实现位于 `src/cmd/compile/internal`;本文后续提到的所有代码路径都是相对于这个目录。编译器是用 Go 编写的,代码可读性很强。在这篇文章中,我们将一点一点的研究这些代码,同时添加支持 `until` 语句的实现代码.
查看 `src/cmd/compile` 中的 `README` 文件,了解编译步骤的详细说明。它将与本文息息相关。
## 扫描
扫描器(也称为 _词法分析器_)将源码文本分解为编译器所需的离散实体。例如 `for` 关键字会转变成常量 `_For`;符号 `...` 转变成 `_DotDotDot`,`.` 将转变成 `_Dot` 等等。
扫描器的实现位于 `syntax` 包中。我们需要做的就是理解关键字 —— `until`。`syntax/tokens.go` 文件中列出了所有 token,我们要添加一个新的:
```
_Fallthrough // fallthrough
_For // for
_Until // until
_Func // func
```
token 常量右侧的注释非常重要,它们用来标识 token。这是通过 `syntax/tokens.go` 生成代码来实现的,文件上面的 token 列表有如下这一行:
```go
//go:generate stringer -type token -linecomment
```
`go generate` 必须手动执行,输出文件(`syntax/token_string.go`)被保存在 Go 源码仓库中。为了重新生成它,我在 `syntax` 目录中执行如下命令:
```
GOROOT=<src checkout> Go generate tokens.go
```
环境变量 `GOROOT` 是[从 Go 1.12 开始必须设置](https://github.com/golang/go/issues/32724),并且必须指向检出的源码根目录,我们要修改这个编译器。
运行代码生成器并验证包含新的 token 的 `syntax/token_string.go` 文件,我试着重新编译编译器,却出现了 panic 提示:
```
panic: imperfect hash
```
这个 panic 是 `syntax/scanner.go` 中代码引起的:
```go
// hash 是针对关键词的完美哈希函数
// 它假定参数 s 的长度至少为 2
func hash(s []byte) uint {
return (uint(s[0])<<4 ^ uint(s[1]) + uint(len(s))) & uint(len(keywordMap)-1)
}
var keywordMap [1 << 6]token // 大小必须是 2 的整数倍(2 的整数次幂)
func init() {
// 填充 keywordMap
for tok := _Break; tok <= _Var; tok++ {
h := hash([]byte(tok.String()))
if keywordMap[h] != 0 {
panic("imperfect hash")
}
keywordMap[h] = tok
}
}
```
编译器试图构建一个“完美”哈希表来执行关键字字符串到 token 的查询。“完美”意味着它不太可能发生冲突,是一个线性的数组,其中每个关键字都映射为一个单独的索引。哈希函数相当特殊(例如,它查看字符串 token 的第一个字符),并且不容易调试新 token 为何出现冲突等问题。为了解决这个问题,我将查找表的大小更改为 `[1 << 7]token`,从而将查找数组的大小从 64 改成 128。这给予哈希函数更多的空间来分配对应的键,冲突也就消失了。
## 解析
Go 有一个相当标准的递归下降算法的解析器,它把扫描生成的 token 流转换为 _具体语法树_。我们开始为 `syntax/nodes.go` 中的 `until` 添加新的节点类型:
```go
UntilStmt struct {
Init SimpleStmt
Cond Expr
Body *BlockStmt
stmt
}
```
我借鉴了用于 `for` 循环的 `ForStmt` 的整体结构。类似于 `for`,`until` 语句有几个可选的子语句:
```
until <init>; <cond> {
<body>
}
```
`<init>` 和 `<cond>` 是可选的,不过省略 `<cond>` 也不是很常见。`UntilStmt.stmt` 中嵌入的字段用于表示整个语法树语句,并包含对应的位置信息。
解析过程在 `syntax/parser.go` 中实现。`parser.stmtOrNil` 方法解析当前位置的语句。它查看当前 token 并决定解析哪个语句。下方是添加的代码片段:
```go
switch p.tok {
case _Lbrace:
return p.blockStmt("")
// ...
case _For:
return p.forStmt()
case _Until:
return p.untilStmt()
```
And this is `untilStmt`:
```go
func (p *parser) untilStmt() Stmt {
if trace {
defer p.trace("untilStmt")()
}
s := new(UntilStmt)
s.pos = p.pos()
s.Init, s.Cond, _ = p.header(_Until)
s.Body = p.blockStmt("until clause")
return s
}
```
我们复用现有的 `parser.header` 方法,因为它解析了 `if` 和 `for` 语句对应的 header。在常用的形式中,它支持三个部分(分号分隔)。在 `for` 语句中,第三部分常被用于 ["post" 语句](https://golang.org/ref/spec#PostStmt),但我们不打算为 `until` 实现这种形式,而只需实现前两部分。注意 `header` 接收源 token,以便能够区分 `header` 所处的具体场景;例如,编译器会拒绝 `if` 的“post”语句。虽然现在还没有费力气实现“post”语句,但我们在 `until` 的场景中应该明确地拒绝“post”语句。
这些都是我们需要对解析器进行的修改。因为 `until` 语句在结构上跟现有的一些语句非常相似,所以我们可以复用已有的大部分功能。
假如在编译器解析后输出语法树(使用 `syntax.Fdump`)然后使用语法树:
```go
i = 4
until i == 0 {
i--
fmt.Println("Hello, until!")
}
```
我们会得到 `until` 语句的相关片段:
```
84 . . . . . 3: *syntax.UntilStmt {
85 . . . . . . Init: nil
86 . . . . . . Cond: *syntax.Operation {
87 . . . . . . . Op: ==
88 . . . . . . . X: i @ ./useuntil.go:13:8
89 . . . . . . . Y: *syntax.BasicLit {
90 . . . . . . . . Value: "0"
91 . . . . . . . . Kind: 0
92 . . . . . . . }
93 . . . . . . }
94 . . . . . . Body: *syntax.BlockStmt {
95 . . . . . . . List: []syntax.Stmt (2 entries) {
96 . . . . . . . . 0: *syntax.AssignStmt {
97 . . . . . . . . . Op: -
98 . . . . . . . . . Lhs: i @ ./useuntil.go:14:3
99 . . . . . . . . . Rhs: *(Node @ 52)
100 . . . . . . . . }
101 . . . . . . . . 1: *syntax.ExprStmt {
102 . . . . . . . . . X: *syntax.CallExpr {
103 . . . . . . . . . . Fun: *syntax.SelectorExpr {
104 . . . . . . . . . . . X: fmt @ ./useuntil.go:15:3
105 . . . . . . . . . . . Sel: Println @ ./useuntil.go:15:7
106 . . . . . . . . . . }
107 . . . . . . . . . . ArgList: []syntax.Expr (1 entries) {
108 . . . . . . . . . . . 0: *syntax.BasicLit {
109 . . . . . . . . . . . . Value: "\"Hello, until!\""
110 . . . . . . . . . . . . Kind: 4
111 . . . . . . . . . . . }
112 . . . . . . . . . . }
113 . . . . . . . . . . HasDots: false
114 . . . . . . . . . }
115 . . . . . . . . }
116 . . . . . . . }
117 . . . . . . . Rbrace: syntax.Pos {}
118 . . . . . . }
119 . . . . . }
```
## 创建 AST
由于有了源代码的语法树表示,编译器才能构建一个*抽象语法树*。我曾写过关于[抽象 vs 具体语法树](http://eli.thegreenplace.net/2009/02/16/abstract-vs-concrete-syntax-trees)的文章 —— 如果你不熟悉他们之间的区别,可以好好看看这个文章。在 Go 中,未来可能会有所变动。Go 编译器最初是用 C 语言编写的,后来自动翻译成 Go;所以编译器的某些部分是 C 时期遗留下来的,有些部分是比较新的。未来的重构可能只会留下一种语法树,但是现在(Go 1.12)我们必须遵循这个流程。
AST 代码位于 `gc` 包中,节点类型在 `gc/syntax.go` 中定义。(不要跟 `syntax` 包中的 CST 混淆)
Go AST 的结构与 CST 不同。所有的 AST 节点都是 `syntax.Node` 类型而非有各自的类型。`syntax.Node` 类型是一种 _可区分的联合体_,其中的字段有很多不同的类型。然而,这些字段是通用的,并且可用于大多数节点类型:
```go
// 一个 Node 代表语法树中的单个节点
// 实际上,因为只有一个,所以语法树就是一个语法 DAG
// 对于一个给定的变量,使用 Op=ONAME 作为节点
// Op=OTYPE、Op=OLITERAL 也是这样,参考 Node.mayBeShared
type Node struct {
// 树结构
// 普通的递归遍历应该包含以下字段
Left *Node
Right *Node
Ninit Nodes
Nbody Nodes
List Nodes
Rlist Nodes
// ...
```
我们以增加一个新的常量标识 `until` 节点作为开始:
```go
// 语句
// ...
OFALL // fallthrough
OFOR // for Ninit; Left; Right { Nbody }
OUNTIL // until Ninit; Left { Nbody }
```
我们再运行一下 `go generate`,这次在 `gc/syntax.go` 文件中,生成了一个代表新节点类型的字符串:
```
// 在 gc 的目录中
GOROOT=<src checkout> Go generate syntax.go
```
应该更新 `gc/op_string.go` 文件使其包含 `OUNTIL`。现在是时候为新节点类型编写 CST->AST 的转换代码了。
转换是在 `gc/noder.go` 中实现的。我们基于现有的 `for` 语句支持,对 `until` 修改建模,从包含一个分支语句类型的 `stmtFall` 开始:
```go
case *syntax.ForStmt:
return p.forStmt(stmt)
case *syntax.UntilStmt:
return p.untilStmt(stmt)
```
然后是新的 `untilStmt` 方法,我们将其添加到 `noder` 类型上:
```go
// untilStmt 把具体语法树节点 UntilStmt 转换为对应的 AST 节点
func (p *noder) untilStmt(stmt *syntax.UntilStmt) *Node {
p.openScope(stmt.Pos())
var n *Node
n = p.nod(stmt, OUNTIL, nil, nil)
if stmt.Init != nil {
n.Ninit.Set1(p.stmt(stmt.Init))
}
if stmt.Cond != nil {
n.Left = p.expr(stmt.Cond)
}
n.Nbody.Set(p.blockStmt(stmt.Body))
p.closeAnotherScope()
return n
}
```
回想一下上面解释过的 `Node` 字段。这里我们使用 `Init` 作为可选的初始化操作,`Left` 字段作用于条件,`Nbody` 字段作用于循环体。
这就是新增 `until` 语句 AST 节点所需的全部内容。如果在构建后输出 AST,将得到以下这些:
```
. . UNTIL l(13)
. . . EQ l(13)
. . . . NAME-main.i a(true) g(1) l(6) x(0) class(PAUTO)
. . . . LITERAL-0 l(13) untyped number
. . UNTIL-body
. . . ASOP-SUB l(14) implicit(true)
. . . . NAME-main.i a(true) g(1) l(6) x(0) class(PAUTO)
. . . . LITERAL-1 l(14) untyped number
. . . CALL l(15)
. . . . NONAME-fmt.Println a(true) x(0) fmt.Println
. . . CALL-list
. . . . LITERAL-"Hello, until!" l(15) untyped string
```
## 类型检查
编译的下一步是类型检查,这是在 AST 的基础上完成的。除了检查类型错误外,Go 中的类型检查还包括 _类型推导_,类型推导可以让我们编写如下语句:
```go
res, err := func(args)
```
无需显示的声明 `res` 和 `err` 的类型。Go 类型检查器还会做一些其它事情,比如链接标识符到对应的声明上,和计算“编译时”常量。代码在 `gc/typecheck.go` 文件中。同样,在 `for` 语句的引导下,我们把这个子句添加到 `typecheck` 的分支中:
```go
case OUNTIL:
ok |= ctxStmt
typecheckslice(n.Ninit.Slice(), ctxStmt)
decldepth++
n.Left = typecheck(n.Left, ctxExpr)
n.Left = defaultlit(n.Left, nil)
if n.Left != nil {
t := n.Left.Type
if t != nil && !t.IsBoolean() {
yyerror("non-bool %L used as for condition", n.Left)
}
}
typecheckslice(n.Nbody.Slice(), ctxStmt)
decldepth--
```
只有一部分的语句分配了类型,并且在布尔上下文中检查条件是否合法。
## 分析并重写 AST
在类型检查后,编译器会经历 AST 分析和重写等几个阶段。具体的序列在 `gc/main.go` 文件的 `gc.Main` 函数中列出。在编译器术语中,这个阶段通常称为 _passes_。
很多 passes 中无需修改就能支持 `until`,因为这些 passes 对所有类型语句都是通用的(在这里通用的 `gc.Node` 结构也有效)。然而,只是有些场景是这样。比如逃逸分析中,它试图找到那些变量“逃离”函数作用域,并分配在堆上而非栈空间。
“逃逸分析”适用于每个语句类型,所以我们必须把它加在 `Escape.stmt` 对应的分支中:
```go
case OUNTIL:
e.loopDepth++
e.discard(n.Left)
e.stmts(n.Nbody)
e.loopDepth--
```
最后,`gc.Main` 可以调用可移植的代码生成器(`gc/pgen.go`)来编译分析代码。代码生成器首先进行一系列 AST 转换,将 AST 维度降低便于编译。这是在先调用 `order` 的 `compile` 函数中完成的。
这个转换(在 `gc/order.go` 中)对语句和表达式重新排序,以强制执行计算标识符顺序。比如,把 `foo /= 10` 重写为 `foo = foo / 10`,用多个单赋值语句替换多赋值语句等等。
为了支持 `until` 语句,我们需要向 `Order.stmt` 增加以下内容:
```go
case OUNTIL:
t := o.markTemp()
n.Left = o.exprInPlace(n.Left)
n.Nbody.Prepend(o.cleanTempNoPop(t)...)
orderBlock(&n.Nbody, o.free)
o.out = append(o.out, n)
o.cleanTemp(t)
```
在 `order`、`compile` 调用位于 `gc/walk.go` 中的 `walk` 后。这个传递过程收集了一系列 AST 转换,这些语句在后面有助于降低 AST 的维度成为 SSA。比如,在 for 循环中重写 range 语句,转变成更为简单的、有具体变量的 for 循环的形式 [\[1\]](https://eli.thegreenplace.net/2019/go-compiler-internals-adding-a-new-statement-to-go-part-1/#id2)。[运行时重写调用 map 的访问方式](https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics)等等。
为了支持 `walk` 中的新语句,我们必须在 `walkstmt` 函数中添加一个 switch 子句。顺便说一下,这也是我们实现 `until` 语句要修改的地方,主要是将它重写为编译器能识别的 AST 节点。在 `until` 的例子中,这比较简单 —— 如文章开头所示,我们只是用倒装条件将它重写为一个 `for` 循环。具体转换代码如下:
```go
case OUNTIL:
if n.Left != nil {
walkstmtlist(n.Left.Ninit.Slice())
init := n.Left.Ninit
n.Left.Ninit.Set(nil)
n.Left = nod(ONOT, walkexpr(n.Left, &init), nil)
n.Left = addinit(n.Left, init.Slice())
n.Op = OFOR
}
walkstmtlist(n.Nbody.Slice())
```
注意我们替换了 n.Left(条件),它带有类型为 ONOT 的新节点(它代表一元操作符 !),新节点包装了之前的 n.Left,然后我们用 OFOR 替换 n.Op。就是这样!
如果在遍历之后输出 AST,我们会看到 OUNTIL 节点不见了,取而代之的是新的 OFOR 节点。
## 尝试
我们现在可以尝试修改编译器,然后运行一个使用了 `until` 语句的示例程序,
```go
$ cat useuntil.go
package main
import "fmt"
func main() {
i := 4
until i == 0 {
i--
fmt.Println("Hello, until!")
}
}
$ <src checkout>/bin/go run useuntil.go
Hello, until!
Hello, until!
Hello, until!
Hello, until!
```
成功了!
提醒:`<src checkout>` 是我们检出的 Go 代码仓库,我们需要修改它、编译它(更多细节参见附录)
## 结论部分 1
这是结论第一部分。我们成功地在 Go 编译器中实现了新增一个语句。这个过程没有涵盖编译器的所有方面,因为这种通过使用 `for` 节点的方式重写 `until` 节点的 AST 方式像是一条捷径。这是一种有效的编译策略,Go 编译器已经有了很多类似的优化手段来 _转换_ AST(这将减少构成的形式,便于编译的最后阶段做更少的工作)。即便如此,我们仍然有兴趣探索最后两个编译阶段 —— _转换为 SSA_ 和 _生成机器码_。这些将在[第 2 部分]((http://eli.thegreenplace.net/2019/go-compiler-internals-adding-a-new-statement-to-go-part-2/)) 讨论。
## Appendix - 构建 Go 的工具链
请先浏览 [Go 贡献指南](https://golang.org/doc/contribute.html)。下面是类似于本文关于重述修改 Go 编译器的简要说明。
有两种方法:
1. 克隆官方的 [Go 仓库](https://github.com/golang/go)并实践本文所描述的内容。
2. 克隆官方的 [Go 仓库](https://github.com/golang/go),并检出 `adduntil` 分支,这个分支中已经有很多基于调试工具的修改。
克隆的路径是本文中 `<src checkout>` 所表示的路径。
要编译工具链,进入 `src/` 目录并运行 `./make.bash`。也能通过 `./all.bash` 来运行所有的测试用例并构建。运行 `make.bash` 将调用构建 Go 完整的 3 个引导步骤,这在我的旧机器上大概需要 50 秒时间。
一旦构建完成,工具链安装在 `src` 同级的 `bin` 目录中。然后,我们可以通过运行 `bin/go` 安装 `cmd/compile` 来快速重新构建编译器。
[\[1\]](https://eli.thegreenplace.net/2019/go-compiler-internals-adding-a-new-statement-to-go-part-1/#id1) Go 有一些特殊的“魔法”、`range` 子句,比如在字符串上使用 `range` 子句,把字符串分隔成字符。这个地方就用了“转换”来实现。
如果要评论,请给我发 [邮件](eliben@gmail.com),或者在[推特](https://twitter.com/elibendersky)上联系我。
via: https://eli.thegreenplace.net/2019/go-compiler-internals-adding-a-new-statement-to-go-part-1/
作者:Eli Bendersky 译者:suhanyujie 校对:JYSDeveloper
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





