
很久以来,我一直对网络爬虫充满热情,特别是它背后的理论。我曾经使用过许多语言来构建它,例如:C++、JavaScript(Node.JS)、Python 等。
但是首先,什么是网络爬虫?
什么是网络爬虫?
网络爬虫是一个计算机程序,它通过浏览互联网来将现有的网页、图像、PDF 等编入索引,并允许用户使用搜索引擎来检索这些内容。 这基本上就是著名的谷歌搜索引擎背后的技术了。
通常,一个高效的网络爬虫被设计成分布式的,即并非一个运行在专用服务器上的独立程序,而是运行在多个服务器上(例如:在云上)的一些程序的多个实例。这样的设计使得爬取任务能够得到更合适的重新分割,从而达到提高性能、增加带宽的效果。
但是,分布式软件并非没有缺点,有一些因素可能会给程序增加额外的延迟,从而引起性能上的降低,例如:网络延迟、同步问题、设计不良的通讯协议等。
为了提高效率,分布式网络爬虫必须得到精心的设计,尽可能的消除一切瓶颈,正如法国海军上将 Olivier Lajous 曾经说过的:
最薄弱的链接决定了整个链条的强度。
Trandoshan: 一个暗网爬虫
您也许知道,已经有一些比较成功的爬虫正在网络上运行,例如 google bot,所以这次我不打算再做一个类似的,而是要做一个专门用于暗网的网络爬虫。
什么是暗网?
在这里我将不再从技术的角度来阐述什么是暗网,因为有专门的文章来描述它。
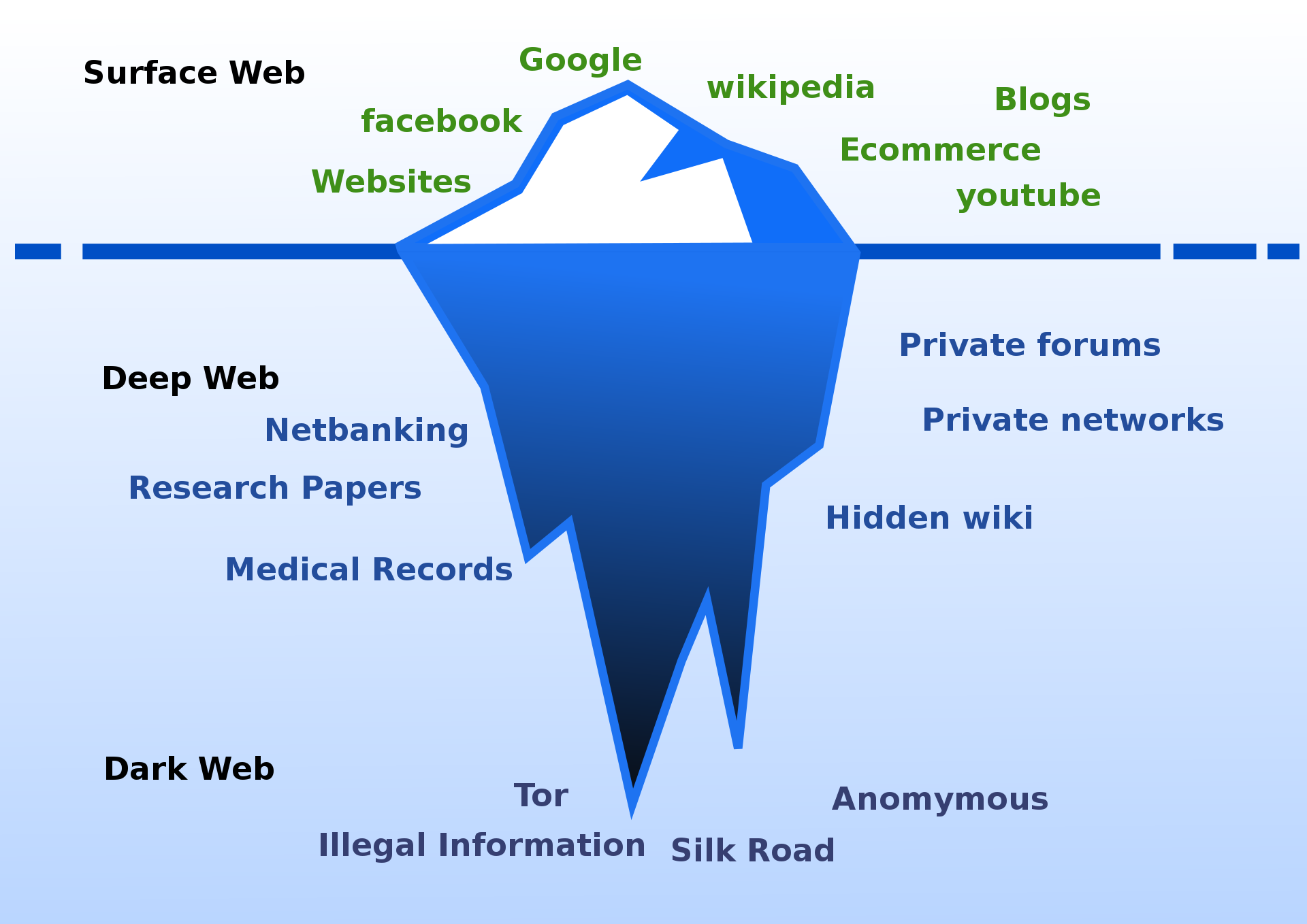
互联网是由三层组成的,我们可以把它想象成一个冰山,如下图所示:
- 表层网或者透明网是我们每天浏览的那部分网络,它被 Google,Qwant,Duckduckgo 等流行的网络爬虫编入索引。
- 深网是未经索引的网络的一部分,这意味着您无法通过搜索引擎来找到其中的网站,但是却可以通过 URL 或者 IP 地址来直接访问它们。
- 暗网是未经索引的网络的另一部分,访问它需要借助特殊的应用程序或代理,使用常规的浏览器是办不到的。例如:建立在 Tor 网络上的最著名的暗网,它需要通过以 .onion 结尾的特殊 URL 来访问。
Trandoshan 的设计是怎样的?
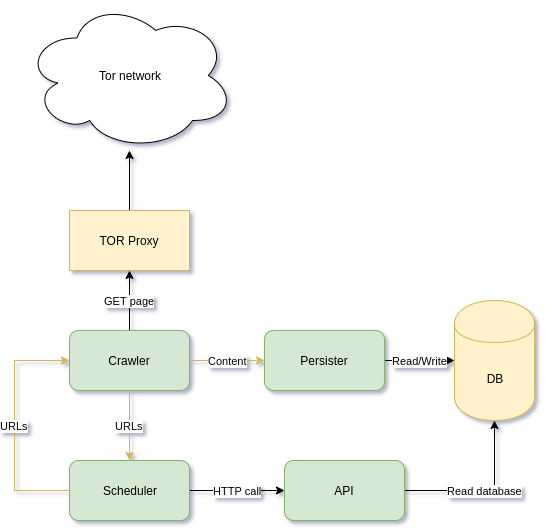
上图显示了 Trandoshan 的大致架构,在探讨它的每个进程的职责之前,我们需要先了解一下它们之间是如何通信的。
Trandoshan 的进程间通信(IPC)主要是依靠 NATS 的消息传递协议(上图中的黄线),并基于生产者 / 消费者模型来实现的。 NATS 中的每个消息都有一个主题(类似于电子邮件),该主题允许其他进程对消息进行过滤,以便只读取它们感兴趣的消息。NATS 是可伸缩的:例如,可以同时有 10 个爬虫进程从消息服务器中读取 URL,每个进程都将得到一个唯一的需要爬取的 URL。 这使得爬虫进程可以并发,即许多爬虫实例可以同时运行而不会产生任何错误,进而提高性能。
Trandoshan 被拆分为 4 个主要进程:
- 爬虫:爬虫进程负责爬取页面,它从 NATS 中读取 URL(由主题 "todoUrls" 标识的消息),然后爬取相应的页面,并提取所有包含在页面内的 URL。这些被提取到的 URL 将被以 "crawledUrls" 为主题发送给 NATS,相应的,页面正文(整个内容)则会被以 "content" 为主题发给 NATS。
- 调度器:调度器负责对 URL 进行审核,它从 NATS 中读取主题为 "crawledUrls" 的消息,然后根据该消息中的 URL 是否已经被爬取过做出要不要爬取的决定,如果需要爬取,则将 URL 以 "todoUrls" 为主题发送给 NATS。
- 持久器:持久器负责将页面内容归档,它读取页面的内容(由主题 "content" 标识的消息)并将其存储到 NoSQL 数据库(MongoDB)中。
- API:API 负责收集信息以供其它进程使用。例如,调度器通过它来确定某个页面是否已经被爬取过。调度程序并不通过与数据库的直接交互来确定相应的 URL 是否被爬取过(直接交互将增加调度器和数据库之间的耦合度),相反它与 API 进程进行交互,这使得数据库和进程之间有了一层抽象。
Go 是经过精心设计的专门用于构建高性能分布式系统的语言。以上这些不同的进程都是使用 Go 语言编写的,因为它能将性能提高很多(由于程序被编译成了二进制文件),除此之外, Go 语言也有很多的库可以使用。
Trandoshan 的源代码可在 GitHub 上找到:https://github.com/trandoshan-io。
怎样运行 Trandoshan?
正如之前所述,Trandoshan 被设计为运行在分布式系统之上的网络爬虫,它可以通过 docker 镜像来获取,这使得它非常适合云环境。https://github.com/trandoshan-io/k8s仓库中包含了在 Kubernetes 集群上部署 Trandoshan 生产实例所需的所有配置文件,对应的容器镜像则位于 docker hub 上。
如果您正确配置了 kubectl,那么就可以通过如下简单的命令来部署 Trandoshan:
./bootstrap.sh
除此之外,您也可以通过 docker 和 docker-compose 在本地运行 Trandoshan。 通过仓库 trandoshan-parent 中的 docker-compose 文件和一个 shell 脚本,使用以下命令便可运行它:
./deploy.sh
怎样使用 Trandoshan?
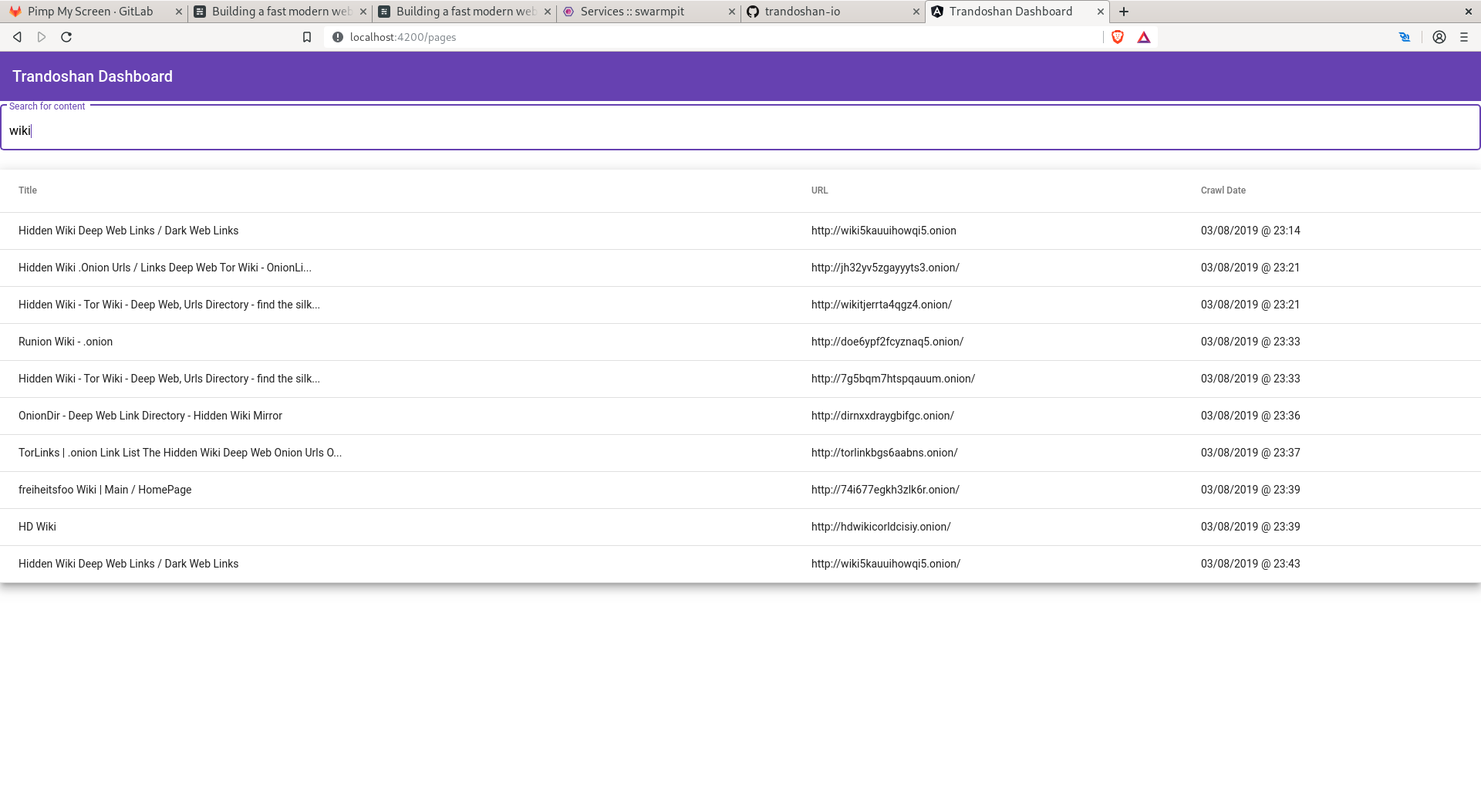
目前,有一个小巧的 Angular 应用程序可以用于查询被编入索引的内容,这个程序通过与 API 进程的交互来完成对数据库中内容的检索。
总结
这次就先到这里,尽管 Trandoshan 已经可以被用于生产环境,但是仍有许多优化工作和新功能需要完成。由于它是一个开源项目,所以每个人都可以通过对相应项目发起 PR 来做出贡献。
Happy hacking!
via: https://creekorful.me/building-fast-modern-web-crawler/
作者:Aloïs Micard 译者:Anxk 校对:lxbwolf
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




