

负载均衡器在 Web 架构中扮演了很关键的角色。它们能在一组后端机器分配负载。这使得服务扩展性更好。因为配置了很多的后端机器,服务也因此能在某次请求失败后找到正常运行的服务器而变得高可用。
在使用了像 [NGINX](https://www.nginx.com/) 等专业的负载均衡器后,我自己也尝试着用 [Golang](https://golang.org/) 创建了一个简易负载均衡器。Go 是一种现代语言,第一特性是支持并发。Go 有丰富的标准库,使用这些库你可以用更少的代码写出高性能的应用程序。对每一个发行版本它都有静态链接库。
## 我们的简易负载均衡器工作原理
负载均衡器有不同的策略用来在一组后端机器中分摊负载。
例如:
- **轮询** 平等分摊,认为后端的所有机器处理能力相同
- **加权轮询** 基于后端机器不同的处理能力,为其加上不同的权重
- **最少连接数** 负载被分流到活跃连接最少的服务器
至于我们的简易负载均衡器,我们会实现这里边最简单的方式 **轮询**。
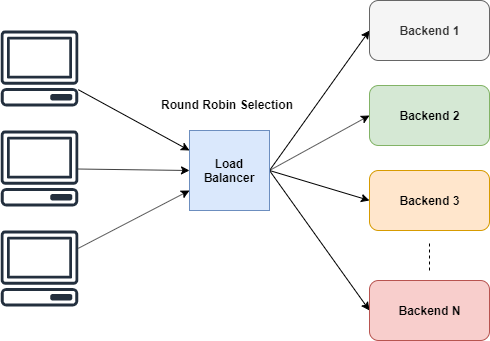
## 轮询选择
轮询无疑是很简单的。它轮流给每个 worker 相同的执行任务的机会。
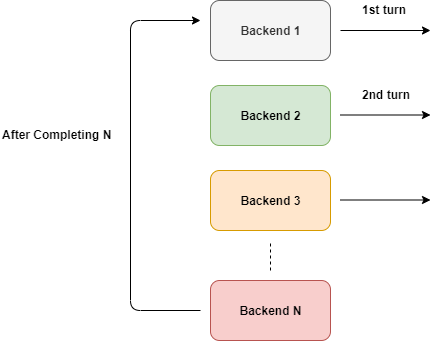
上图已经说明了,负载均衡器周期性地选择某台服务器。但是我们不能*直接*使用它,不是吗?
**如果后端机器宕机了怎么办?**恐怕我们不会希望流量被路由到挂掉的机器上去。因此除非我们添加一些条件,否则不能直接使用这个算法。我们需要**把流量只路由到没有挂掉且正常运行的后端机器上**。
## 定义几个结构体
修正思路后,现在我们清楚我们是想要一种能跟踪后端机器状态信息的方法。我们需要检查机器是否存活,也需要跟踪 Url。
我们可以简单地定义一个下面的结构体来维护我们的后端机器。
```go
type Backend struct {
URL *url.URL
Alive bool
mux sync.RWMutex
ReverseProxy *httputil.ReverseProxy
}
```
不要担心,**后面我会解释 `Backend` 里的字段**。
现在我们要在负载均衡器中跟踪所有后端机器的状态,可以简单地使用一个切片来实现。另外还需要一个计算变量。我们可以定义为 `ServerPool`
```go
type ServerPool struct {
backends []*Backend
current uint64
}
```
## ReverseProxy 的使用
前面已经声明过了,负载均衡器是专门用来把流量路由到不同的后端机器以及把结果返回给来源客户端的。
Go 官方文档的描述:
> ReverseProxy 是一种 HTTP Handler,接收请求并发送到另一台服务器,把响应代理回客户端。
**而这正是我们需要的。**我们不需要重复造轮子了。我们可以简单地通过 `ReverseProxy` 转发原始请求。
```go
u, _ := url.Parse("http://localhost:8080")
rp := httputil.NewSingleHostReverseProxy(u)
// initialize your server and add this as handler
http.HandlerFunc(rp.ServeHTTP)
```
通过 `httputil.NewSingleHostReverseProxy(url)` 我们可以初始化一个把请求转发给 `url` 的反向代理。在上面的例子中,所有的请求会被转发到 localhost:8080,结果会发回到来源客户端。这里你可以找到更多例子。
如果我们看一下 ServeHTTP 方法的签名,它有 HTTP handler 的签名,因此我们可以把它传给 `http` 的 `HandlerFunc`。
你可以在[文档](https://golang.org/pkg/net/http/httputil/#ReverseProxy)中找到更多例子。
在我们的简易负载均衡器中,我们可以用与 `ReverseProxy` 相关联的 `Backend` 中的 `URL` 初始化 `ReverseProxy`,这样 `ReverseProxy` 就会把我们请求路由到 `URL`.
## 选择处理过程
我们要在下一次轮询中**跳过挂掉的后端机器**。但是无论如何我们需要一种计数的方式。
很多客户端会连接到负载均衡器,当某一个客户端发来请求时,我们要转发流量的目标机器会出现竞争。我们可以使用 `mutex` 为 `ServerPool` 加锁来避免这种现象。但这是一种过犹不及的手段,毕竟我们不希望锁住 ServerPool。我们的需求只是让计数器加 1.
为了满足这个需求,最理想的解决方案是让加 1 成为原子操作。Go 的 `atomic` 包能完美支持。
```go
func (s *ServerPool) NextIndex() int {
return int(atomic.AddUint64(&s.current, uint64(1)) % uint64(len(s.backends)))
}
```
这里我们的加 1 是原子操作,通过对切片的长度取模返回了 index。这意味着返回的值一定在 0 与切片长度之间。归根结底,我们需要的是一个特定的 index,而不是所有数。
## 选中存活的后端机器
我们已经知道我们的请求是被周期性的路由到每台后端机器上的。我们要做的就是跳过挂掉的机器。
`GetNext()` 返回的一定是 0 与 切片长度之间的值。每次我们要转发请求到后端某台机器时,如果它挂掉了,我们必须循环地查找整个切片。
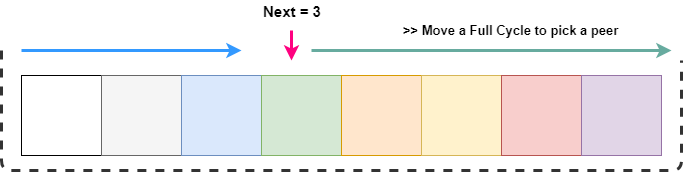
从上图可以看出,我们要想从 next 开始遍历整个 list,只需要遍历 `next + length`。但是我们要覆盖整个切片的长度才能选中一个 index。我们可以用取模操作很容易地实现。
当我们通过搜索找到了一台正常工作的后端机器时,我们把它标记为 current。
下面是对应上面操作的代码。
```go
// GetNextPeer returns next active peer to take a connection
func (s *ServerPool) GetNextPeer() *Backend {
// loop entire backends to find out an Alive backend
next := s.NextIndex()
l := len(s.backends) + next // start from next and move a full cycle
for i := next; i < l; i++ {
idx := i % len(s.backends) // take an index by modding with length
// if we have an alive backend, use it and store if its not the original one
if s.backends[idx].IsAlive() {
if i != next {
atomic.StoreUint64(&s.current, uint64(idx)) // mark the current one
}
return s.backends[idx]
}
}
return nil
}
```
## 在 Backend 结构体中避免竞争条件
我们需要考虑一个很严重的问题。我们的 `Backend` 结构体有一个可能被不同协程同时修改或访问的变量。
我们知道读的协程数比写的多。因此我们用 `RWMutex` 来串行化对 `Alive` 的读写。
```go
// SetAlive for this backend
func (b *Backend) SetAlive(alive bool) {
b.mux.Lock()
b.Alive = alive
b.mux.Unlock()
}
// IsAlive returns true when backend is alive
func (b *Backend) IsAlive() (alive bool) {
b.mux.RLock()
alive = b.Alive
b.mux.RUnlock()
return
}
```
## 让负载均衡器发请求
所有的准备工作都做完了,我们可以用下面的方法对我们的请求实现负载均衡。只有在所有的后端机器都离线后它才会返回失败。
```go
// lb load balances the incoming request
func lb(w http.ResponseWriter, r *http.Request) {
peer := serverPool.GetNextPeer()
if peer != nil {
peer.ReverseProxy.ServeHTTP(w, r)
return
}
http.Error(w, "Service not available", http.StatusServiceUnavailable)
}
```
这个方法可以简单地作为一个 `HandleFunc` 传给 http server。
```go
server := http.Server{
Addr: fmt.Sprintf(":%d", port),
Handler: http.HandlerFunc(lb),
}
```
## 仅把流量路由到健康的后端机器
现在我们的 `lb` 有个严重的问题。我们不知道后端某台机器是否健康。我们必须向后端机器发送请求再检查它是否存活才能知道。
我们可以用两种方法实现:
- **主动:**在处理当前的请求时,选中的某台机器没有响应,我们把它标记为挂掉。
- **被动:**我们可以以固定的周期 ping 后端机器,检查其状态
## 主动检查后端健康机器
`ReverseProxy` 在有错误时会触发一个回调函数 `ErrorHandler`。我们可以用它来检测失败。下面是其实现:
```go
proxy.ErrorHandler = func(writer http.ResponseWriter, request *http.Request, e error) {
log.Printf("[%s] %s\n", serverUrl.Host, e.Error())
retries := GetRetryFromContext(request)
if retries < 3 {
select {
case <-time.After(10 * time.Millisecond):
ctx := context.WithValue(request.Context(), Retry, retries+1)
proxy.ServeHTTP(writer, request.WithContext(ctx))
}
return
}
// after 3 retries, mark this backend as down
serverPool.MarkBackendStatus(serverUrl, false)
// if the same request routing for few attempts with different backends, increase the count
attempts := GetAttemptsFromContext(request)
log.Printf("%s(%s) Attempting retry %d\n", request.RemoteAddr, request.URL.Path, attempts)
ctx := context.WithValue(request.Context(), Attempts, attempts+1)
lb(writer, request.WithContext(ctx))
}
```
这里我们利用闭包的特性来设计这个错误 handler。我们能把 serverUrl 等外部的变量捕获到方法内。它会检查已存在的重试次数,如果小于 3,就会再发送同样的请求到同一台机器。这么做的原因是可能会有临时的错误,服务器可能暂时拒绝你的请求而在短暂的延迟之后又变得可用了(可能服务器为了接受更多的客户端耗尽了 socket)。因此我们加了一个定时器,延迟 10 毫秒左右进行重试。每次请求都会加一次重试次数的计数。
3 次请求都失败后,我们把这台后端机器标记为挂掉。
下一步要做的是,把这个请求发送到另外一台后端机器。我们通过使用 context 包来维护一个尝试次数的计数来实现。增加了尝试次数的计数后,我们把它返回给 `lb`,寻找下一台可用的后端机器来处理这个请求。
我们不能无限地重复这个过程,因此我们需要在 `lb` 中检查在继续处理该请求之前是否已达到了最大尝试次数。
我们可以简单地从请求中取得尝试次数,如果它超过了最大数,取消这次请求。
```go
// lb load balances the incoming request
func lb(w http.ResponseWriter, r *http.Request) {
attempts := GetAttemptsFromContext(r)
if attempts > 3 {
log.Printf("%s(%s) Max attempts reached, terminating\n", r.RemoteAddr, r.URL.Path)
http.Error(w, "Service not available", http.StatusServiceUnavailable)
return
}
peer := serverPool.GetNextPeer()
if peer != nil {
peer.ReverseProxy.ServeHTTP(w, r)
return
}
http.Error(w, "Service not available", http.StatusServiceUnavailable)
}
```
这个实现是递归的。
## context 的使用
`context` 包能让你保存 HTTP 请求中有用的数据。我们大量地使用了它来跟踪请求中特定的数据,如尝试次数和重试次数。
首先,我们需要指定 context 的 key。推荐用不重复的整型而不是字符串作为 key。Go 提供了 `iota` 关键字实现常量的增加,每个 `iota` 含有一个独一无二的值。这是一个定义整型 key 的完美解决方案。
```go
const (
Attempts int = iota
Retry
)
```
然后我们可以像在 HashMap 中检索值一样检索定义的值。返回的默认值随实际用例的不同而不同。
```go
// GetAttemptsFromContext returns the attempts for request
func GetRetryFromContext(r *http.Request) int {
if retry, ok := r.Context().Value(Retry).(int); ok {
return retry
}
return 0
}
```
## 被动健康检查
通过被动健康检查我们可以恢复挂掉的后端机器或识别它们。我们以固定的时间周期 ping 后端机器来检查它们的状态。
我们尝试建立 TCP 连接来 ping 机器。如果后端机器有响应,我们把它比较为存活的。如果你愿意,这种方法可以修改为请求一个类似 `/status` 的特定的服务终端。建立连接之后不要忘记关闭连接,以免对服务器造成额外的负载。否则,它会尝试一直维持连接最终耗尽资源。
```go
// isAlive checks whether a backend is Alive by establishing a TCP connection
func isBackendAlive(u *url.URL) bool {
timeout := 2 * time.Second
conn, err := net.DialTimeout("tcp", u.Host, timeout)
if err != nil {
log.Println("Site unreachable, error: ", err)
return false
}
_ = conn.Close() // close it, we dont need to maintain this connection
return true
}
```
现在我们可以像下面这样遍历服务器并标记它们的状态。
```go
// HealthCheck pings the backends and update the status
func (s *ServerPool) HealthCheck() {
for _, b := range s.backends {
status := "up"
alive := isBackendAlive(b.URL)
b.SetAlive(alive)
if !alive {
status = "down"
}
log.Printf("%s [%s]\n", b.URL, status)
}
}
```
在 Go 中,我们可以起一个定时器来周期性地运行它。当定时器创建后,你可以用通道监听事件。
```go
// healthCheck runs a routine for check status of the backends every 20 secs
func healthCheck() {
t := time.NewTicker(time.Second * 20)
for {
select {
case <-t.C:
log.Println("Starting health check...")
serverPool.HealthCheck()
log.Println("Health check completed")
}
}
}
```
在上一段中,`<-t.C` 通道会每 20 秒接收一次数据。`select` 探测这个事件。如果没有 `default` 分支,`select` 会一直等待,直到至少一个分支执行。
最后,在一个单独的协程中运行。
## 总结
本文讲了很多
- 轮询选择
- 标准库中的 ReverseProxy
- Mutex
- 原子操作
- 闭包
- 回调
- select 操作
还有很多可以做的来改进我们的简易负载均衡器。
例如:
- 用堆来对后端机器进行排序,减少搜索范围
- 采集统计信息
- 实现加权轮询/最少连接
- 支持配置文件
等等。
你可以在[这里](https://github.com/kasvith/simplelb/)找到代码库。
感谢阅读????
via: https://kasvith.me/posts/lets-create-a-simple-lb-go/
作者:Vincent Blanchon 译者:lxbwolf 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





