
## 背景
>两年多前的一天(2018年的某天),我们的产品经理突然找到我,说我们的广告业务上线后效果不错,但是需要做敏感词过滤处理,需要接入一个模糊词词典和一个精确词词典。然后我拿到了这两份词典,两份违禁词加起来总量近100w条。
>
>这个需求简单来说就是如果用户的查询词中命中了违禁词的话是不能出广告的。如:用户query=怎么去故宫博物院,因为命中了故宫博物院,所以不能出广告。
>最终我合并了这两份词表,并写了一个高效的实现。
>
>今天打算就其中的模糊匹配部分单独抽出来讨论一下其实现方案,并开源了一个我自己用go写的开箱即用的高性能匹配方案[仓库地址](https://github.com/TheFutureIsOurs/ahocorasick)。
>
## 理论基础
对于一个web应用来说,这种大量的字符串,一个一个匹配肯定是不行的。
肯定是需要高性能的匹配方案。
使用字典树(trie树)进行匹配是一个方案,
但是达不到高性能。
因为对于模糊匹配来说,使用字典树需要不断回退。
如:我们的字典里有下面这两个词:
怎么去天安门
故宫博物院
query=怎么去故宫博物院。
字典树匹配过程如下:
第一次匹配:q=怎么去故宫博物院
怎->么->去->故(fail)
到 故 这个词失败后进行回退,回退到第二个词进行匹配
第二次匹配:q=么去故宫博物院
么(fail)
回退到第三个词
第三次匹配:q=去故宫博物院
去(fail)
回退到第四个词
第四次匹配:q=故宫博物院
故->宫->博->物->院(success)
匹配完成。
可以看到如果对于查询词比较多的情况下,不断回退导致了性能下降。如果刚好又遇到跟字典中命中了大量前缀,更是一个灾难。
那如何做到高性能呢?这时需要用到[Aho–Corasick算法](https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm)
该算法在1975年产生于贝尔实验室,是著名的多模匹配算法。其本质是一个自动机,下面我们称为AC自动机。
我们先看下其特点。
#### AC自动机:
1.高速完成多模式匹配而不用回溯,与模式串的数量和长度无关,只与查询文本长度有关,时间复杂度O(n)。
2.基础结构为trie树。
3.KMP的思想:为trie树所有节点建立fail指针。与KMP不同的是:AC的fail指针是指向最长后缀。
##### 基本构造:
goto表:成功转移到另一个状态
failure表:不可成功转移时,则使用该表转移到下一个状态
output表:命中的模式串
##### 查询:
在goto表里查找,如果不能成功转移到下个状态,就通过failure表转移,在每步转移的同时,判断output是否可输出
##### 构建方法:
goto表:trie树
output表:trie树叶子节点+在fail表构建时的可输出节点
failure表:逐层构建
1)根节点的fail为0,深度为1的节点所有的fail=0
2)深度>=2的节点N,从其父节点Pn转移到N需要接收字符C,则测试goto(fail(Pn),C),如果成功,则fail(N)=goto(fail(Pn),C)
3)如果失败,则测试goto(fail(fail(Pn)),C),如此反复,肯定可以找到一个有效状态(最终往上到根节点时,如果转移失败,则fail(N)=0)。
以经典的ushers为例,模式串是he/ she/ his /hers。构建的自动机如图:
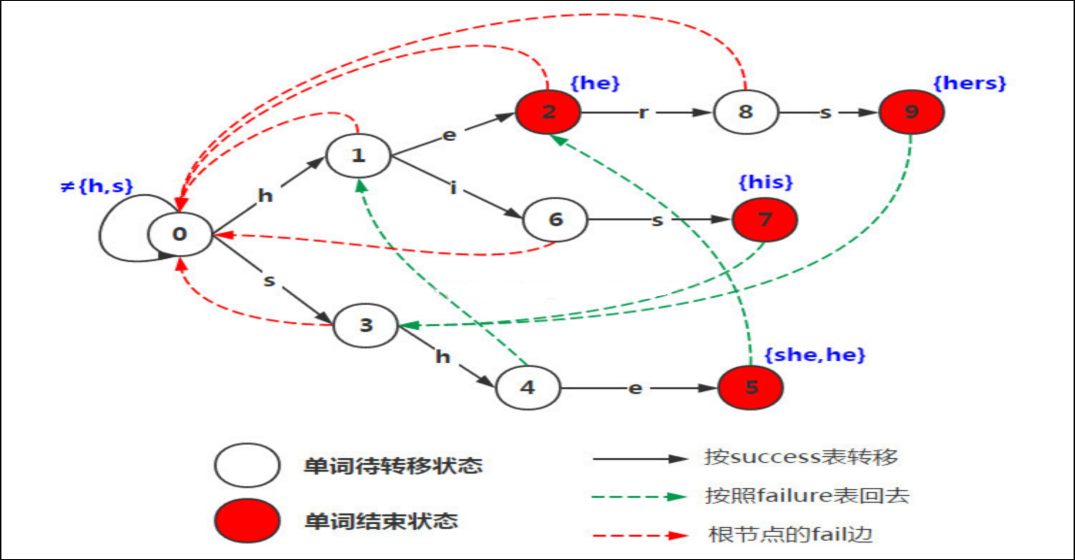
AC自动机的基础是trie树,trie树的实现决定了AC自动机的效率高低,
我们看下常用的两种实现。
Hash trie树 VS Double Array Trie树
Hash trie
实现起来相对简单
理想状态下取词复杂度O(1)
hash空间占用量大,hash函数也有性能消耗,数据量很大的情况下很难保证O(1)
另外含有大量指针,对于有gc的语言来说,不利于gc
用go来定义就是:
type node struct {
val rune
term bool
depth int
children map[rune]*node
}
Double Array trie
实现起来较复杂
取词复杂度O(1)
完全压缩到两个数组里,去掉了指针,结构比较简单,兼顾了查询效率和空间存储
用go来定义就是:
type doubleArrayTrie struct {
base []int
check []int
}
我们着重说下双数组trie树。
Double Array Trie
核心:
Base数组:维持链路关系,存储转义基数(即子节点的索引)。
Check数组:和base数组等长,用来确认转移的正确性。存储上一个状态。
对于一个字符串s,当前字符状态为t,增加一个字符c转义到状态tc。则:
base[t]+c = base[tc]
check[tc] = t
构建方式:
>1.依次处理每个词的每个字来构建
>2.按每个词的首字,然后依次处理构建
避免冲突移动的方法
排序,边构建树边构建双数组,对于一群兄弟节点寻找一个插入点,使得这些节点未被占用。
如果进行排序后,构建起来就会快很多。使用第二种方式构建会减少冲突次数及数组长度,加快构建时间,且更易于构建。在构建Double Array trie时,受到了[darts-java](https://github.com/komiya-atsushi/darts-java)开源项目的启发,在此深表感谢
DFS生成树。
type Node struct {
Code rune
Left, Right, Depth, Base int
Children []*Node
}
Code:字符编码
Left,Right为这个节点在字典中索引范围
Depth表示深度
Base为该节点的转移基数,叶子节点为-1
base[begin+code]=子节点的begin
check[begin+code]=begin
构建过程:
1.令base[0]=1;check[0]=0,排序,对根节点获取子节点
2.对每一群兄弟节点,寻找一个begin值使得数组未被占用,则每个兄弟节点的check[begin+code]=begin;
3.对兄弟节点的每个节点,如果没有孩子,则令base为负值,否则为该节点的子节点的begin值
双数组树和hash树构建完成后,进行对比。
运行机器:2 Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
Dict:61w条(黑名单);字数:5872778
待匹配:96330条(用户请求query); 字数:887790
| --| hash| dat|
| -------- |-----:| -----:|
|词典构建时间|2062ms|50118ms|
|内存占用|76M|45M|
|查询性能(Benchmark)|41.540684ms|34.492564ms|
可以看到,使用dfs生成树相比hash树,词典构建时间增加到50s,但内存使用降低40.79%,查询效率提升16.97%。
问题:
1.现在实现的双数组trie树build时间有些长,能否缩短构建时间?
2.AC自动机的构建是BFS,这需要我们构建完trie树后再构建AC自动机,这一步也会增加时间,能否边构建双数组trie树的时候边构建AC自动机?
3.查询效率确实比hash trie高,这个查询时间能否再度优化?
问题关键点:
1.转移基数存储的子节点的索引,如果改为BFS构建,如何保证AC自动机的Fail状态和双数组Trie树状态对应,同步构建如何保证构建过程可控
2.dfs构建时增加了一个单独的叶子节点,这个节点能否省掉?如果可以不但能减少一次查询,同时也会减少构建时间,降低内存占用,提升查询效率。
解决办法:
1.bfs生成树
2.叶子节点压缩
1)缩短了为孩子节点寻找未被占用空间的时间,减少构建时间
2)缩小了数组占用的空间
3)提升了查询速度
type Node struct {
Code rune
Depth, Base, Index, Left, Right int
Term bool
Children []*Node
}
Term标识当前节点是否叶子节点
Index标识当前节点在双数组中的索引
BFS生成树构建步骤:
1.令base[0]=1;check[0]=0; 获取根节点的子节点
2.为每个子节点和其孩子节点设置base&check:
对每个子节点获取孩子节点,为孩子节点寻找空闲插入点begin,如果当前节点为叶子节点,则该节点base取反,同时设置孩子节点的Base[pos]=begin。Check[pos]=parent.Index
优化后,再来看下对比:
运行机器:2 Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
Dict:61w条(黑名单);字数:5872778
待匹配:96330条(用户请求query); 字数:887790
| --| hash| 优化前双数组|优化后双数组|
| -------- |-----:| -----:| -----:|
|词典构建时间|2062ms|50118ms|4306ms|
|内存占用|76M|45M|40M|
|查询性能(Benchmark)|41.540684ms|34.492564ms|30.199722ms|
可以看到构建时间大幅下降,内存占用下降11.11%,查询效率提升12.4%。
## AC自动机的一个极速实现
有了上面的基础后,实现ac自动机就容易了。但是理论谁都会讲几句,真正实现起来并不那么容易。
下面介绍下笔者用go写的一个非常快速的实现。[仓库地址](https://github.com/TheFutureIsOurs/ahocorasick)
基于双数组Trie树的一种极速实现。可用于模糊匹配,违禁词标记。
常用使用场景为:
>1.聊天时,对用户输入的query进行命中违禁词时进行屏蔽。
>
>2.判断用户输入词是否命中了违禁词黑名单,然后就行后续逻辑处理。
等需要高性能模糊匹配的场景。
### 优化
本算法除了基于双数组进行构建外,还做有额外的优化,保证更高的效率:
1.在构造算法时,双数组和fail指针及输出项会同时构建,大幅度提升构建速度,减少字典构建时间。
2.压缩输出项,减少构建时长及内存占用及gc。
3.压缩了叶子节点,减少内存占用,提升检索效率。
对压缩输出项的解释:
如:违禁词词典为:
he
she
输入为: ushe,则返回的命中项为:she.
解释:如果不做输出项压缩,则命中项为:he,she;其最长输出项为she。
考虑到在实际业务中,不管是对违禁词做屏蔽(如上文中的ushe,屏蔽违禁词后为u***),还是只判断是否命中了违禁词,都不需要冗余的输出项,对输出项做压缩,不仅可以减少构建时长,还能减少内存占用,对于go来说,还可以减少gc扫描。
### 性能
对比一个star数较多的[cloudflare/ahocorasick](https://github.com/cloudflare/ahocorasick)
并返回相同的结果(使用api:MultiPatternIndexes(content []rune) []int)进行对比(对比代码见test文件)。
字典:dictionary.txt 字符串个数:153151。字符数:401552 (平均每条2.6个字符)
待检索文件:text.txt 字符数:815006
(字典和待检索文件已在仓库内)
运行机器:联想小新pro13 Ryzen 5 3550H
对待检索文件匹配100遍
go版本:1.15
待匹配前先进行一次gc(runtime.Gc())
| 仓库 |字典构建时间(ms)| 一次gc时间(ms)| 100遍全文匹配(ms) |inuse_space|inuse_objects|
| -------- |-----:| -----: | :----: | :----: |:----:|
| cloudflare/ahocorasick |59| 686 | 14910 |4.67G| 360455|
| TheFutureIsOurs/ahocorasick|2431| 0 | 5341 |14.2M| 4 |
可以看出,性能比cloudflare/ahocorasick快64%(检索一遍81.5w的字符仅需54ms),得益于双数组实现和对输出项的优化,执行一次gc的时间可以忽略不记(持有的指针仅为四个数组header)。另外占用内存仅为14.2M。
但得益于上面的各种优化,使得构建时间优化到2.4s,虽然仍较cloudflare/ahocorasick长,但是考虑到构建时较复杂,而且大部分应用只需在启动时构建一次,秒级对于感官时间较短,构建时长可控(笔者用一个业务的61w行黑名单词测试,构建时间3.5s),但带来的更高的可量化的各项指标收益,这个是值得的。
[仓库地址](https://github.com/TheFutureIsOurs/ahocorasick)
有疑问加站长微信联系(非本文作者))




