
在算法和大数据领域中,通过 DAG 图来编排业务算子是非常实用的一个方案。
比如大名鼎鼎的 Spark 就引入了 DAG 进行任务调度。
在学习了相关知识后,手痒之下,我在业余时间基于 Golang 开发了一个 DAG 图执行引擎,也算是实践知行合一了。
项目地址:symphony09/running: Golang DAG 图化执行引擎 (github.com)(求个 star 不过分吧)
这里分享一下实现过程中的心得,如有错误之处,还请不吝斧正。
DAG 是什么
DAG 的全称为 Directed Acyclic Graph ,即有向无环图,是图数据结构的一种。
举例来说,下图就是一个简单的 DAG 图:

可以看到,除了最基本的顶点和边,它还有两个特点:
- 边上带有方向箭头,这代表边是有向的,可以经过边从起点到达终点,但是不可以从终点回到起点
- 无法从任意顶点出发经过若干条边回到该点
正因为这两个特点,所以这种图结构被叫做有向无环图。
DAG 能做什么
首先 DAG 只是一种数据结构,它本身并没有什么作用。
但是如果把它作为具体事物间依赖关系的抽象描述,那么事情就会变得有意思起来。
比如有这么三件事:做饭,烧水,泡茶
只要知道泡茶依赖于烧水,那么就可以判断出可以边做饭边烧水,等烧完水就可以泡茶。
这其中蕴含了两个步骤:
- 分析依赖关系
- 解决依赖关系
对于人来说,我们可以通过经验和知识来分析依赖关系,而对于程序来说,就需要通过信息载体来分析依赖关系了。
DAG 因为有向无环的特点就很适合作为依赖信息的载体。
- 通过有向性,可以知道是谁依赖谁
- 通过无环性,保证所有依赖可以逐步解决
DAG 实现
通常,DAG 包含顶点集合和边集合,但是如果顶点包含了后继顶点的引用,也就隐含了边的信息。
这样的好处是可以快速查找到所有后继顶点信息,不用遍历所有的边。
running 中的 DAG 的数据结构:
type DAG struct {
// 部分字段未展示
Vertexes map[string]*Vertex // 顶点map,key为顶点名
}
type Vertex struct {
// 部分字段未展示
Prev int // 依赖计数,为 0 时表示所有依赖的顶点已解决
Traversed bool // 顶点解决后置为 true
Next []*Vertex // 顶点解决后,所有后继顶点依赖计数减一
}
图执行和环路检测
俗话说的好,没病走两步。环路检测最简单的方法就是执行图(拓扑排序),然后检测最后是否存在无法解决依赖的顶点。
下面的代码既可以获取执行步骤,也可以检查环路。
func (graph *DAG) Steps() ([][]string, []string) {
steps := make([][]string, 0)
// 省略部分代码
for {
var names []string
for name, vertex := range graph.Vertexes {
// vertex is never traversed and all prev vertex are done, so it can be processed
if !vertex.Traversed && vertex.Prev == 0 {
names = append(names, name)
}
}
if len(names) == 0 {
break
}
// set vertex status to traversed
for _, name := range names {
graph.Vertexes[name].Traversed = true
for _, vertex := range graph.Vertexes[name].Next {
vertex.Prev--
}
}
steps = append(steps, names)
}
// found vertexes which are never traversed
left := make([]string, 0)
for _, vertex := range graph.Vertexes {
if !vertex.Traversed {
left = append(left, vertex.RefRoot.NodeName)
}
}
// 省略部分代码
return steps, left
}
代码逻辑很简单:
找到所有未解决(Traversed == false)并且前置依赖已解决(Prev == 0)的点,
将状态置为已解决(Traversed == true),并将后继点的依赖计数减一(Next[i].Prev--)。
不断重复这个过程就能得到每一步前置依赖已解决的点,如果最后还有剩下的点,那么这些点中就存在着循环依赖。
因为此过程会修改图状态,所有在最后还应该进行重置。
func (graph *DAG) reset() {
for _, vertex := range graph.Vertexes {
vertex.Traversed = false
for _, nextVertex := range vertex.Next {
nextVertex.Prev++
}
}
}
此外考虑并发场景,应该加锁执行。
图执行优化(一)
上文提到方法虽然可以用来获取图执行步骤,但也有非常大的缺点,考虑下图的 DAG 执行:
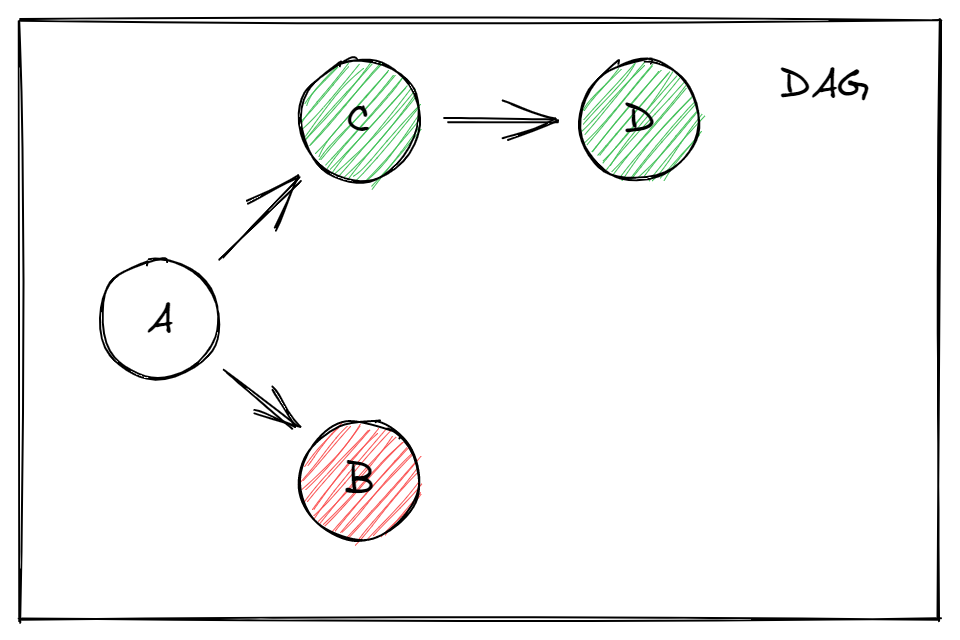
用上文的方法,这个图的执行会分为三步:
- 执行 A
- 并发执行 B,C
- 执行 D
从依赖的角度看,这么做没什么问题。但是在现实情况中,每个点执行的速度通常是不一样的。
假设 A、C 各需要 10 ms,B 需要 30 ms,D 需要 20 ms
那么三步总的执行时间就要 60 ms(10 + 30 + 20)。
但是实际上 C 执行完就可以马上执行 D,不必等 B 完成。
一般的优化方法是把 C、D 作为一个簇 E 来执行,簇 E 需要的时间就是 30 ms,和 B 相同。
这样一来,执行就步骤就缩减为 2 步:
- 执行 A
- 执行 B,E
两步总的执行时间只要 40 ms(10 + 30 )。
图优化执行(二)
上面两种图执行方法都是预先计算好执行步骤,但其实也可以进行实时求解。
用 Go 实现的思路如下:
开启一个监控协程和一个执行协程
监控协程查找可以执行的节点通过通道发送给执行协程,执行协程完成节点执行后也通过通道通知监控协程。
监控协程收到节点完成通知,修改节点状态,再查找可以执行的节点发送给执行协程。
如果没有查找到可执行节点,并且也没有正在执行中的节点,那么执行结束,进行清理和退出工作。
这部分代码稍微复杂一点,就不贴了。
具体实现可以参考 running/pool_worker.go at main · symphony09/running (github.com)
有疑问加站长微信联系(非本文作者))



