
map又称为hash表、字典,存储键值对,其增删改查时间复杂度可以达到O(1)。map和切片是Go语言开发最常用的数据类型。
基本操作
map存储键值对,支持key-value键值对的插入,查找/修改/删除key对应的value,并且这些操作都可以在O(1)时间复杂度完成。
package main
import "fmt"
func main() {
//map声明初始化
score := make(map[string]int, 0)
//key-value键值对存储
score["zhangsan"] = 100
score["lisi"] = 90
//len返回map存储的键值对数目
fmt.Println(len(score), score) //2 map[lisi:90 zhangsan:100]
//查找key对应值,两种方式:1)返回值value,以及bool值表示key-value键值对是否存在;2)只返回值value
zhangsan, ok := score["zhangsan"]
zhangsan1 := score["zhangsan"]
fmt.Println(zhangsan, ok, zhangsan1) //100 true 100
//修改key对应值
score["zhangsan"] = 95
fmt.Println(score["zhangsan"]) //95
//删除map中键值对
delete(score,"zhangsan")
//这时候查找key对应值,返回value类型空值,int类型空值就是0
zhangsan, ok = score["zhangsan"]
fmt.Println(zhangsan, ok) //0 false
}
len函数可以获取map键值对数目,注意map在查找key对应的value时,有两种方式:1)返回一个变量,只返回值value;2)返回两个变量,第一个表示值value,第二个为bool类型表示key-value键值对是否存在。另外,key-value键值对不存在时,查找时返回的是值value类型对应空值,如整数0,空字符串,空切片,指针nil等。特别当值类型为指针时要注意,使用之前最好判断下查找的键值对是否存在,以防出现空指针异常panic。
map也支持for range遍历(迭代),熟悉PHP语言的都知道,PHP数组元素的遍历和插入顺序是一样的;要特别注意Go语言map遍历时,键值对的访问顺序和插入是不一致的,并且每次遍历的访问顺序都不同,如下面例子所示:
package main
import "fmt"
func main() {
//map声明初始化
score := make(map[string]int, 0)
//key-value键值对存储
for i := 0; i < 10; i ++ {
score[fmt.Sprintf("test-%v", i)] = i
}
for k, v := range score {
fmt.Printf("%v:%v ", k, v)
}
//test-4:4 test-8:8 test-2:2 test-3:3 test-5:5 test-6:6 test-7:7 test-9:9 test-0:0 test-1:1
fmt.Printf("\n")
for k, v := range score {
fmt.Printf("%v:%v ", k, v)
}
//test-9:9 test-0:0 test-1:1 test-5:5 test-6:6 test-7:7 test-2:2 test-3:3 test-4:4 test-8:8
fmt.Printf("\n")
//直接修改v是没有用的
for _, v := range score {
v += 100
}
//map[test-0:0 test-1:1 test-2:2 test-3:3 test-4:4 test-5:5 test-6:6 test-7:7 test-8:8 test-9:9]
fmt.Println(score)
//遍历过程中这样修改map键值对
for k, v := range score {
score[k] = v + 100
}
//map[test-0:100 test-1:101 test-2:102 test-3:103 test-4:104 test-5:105 test-6:106 test-7:107 test-8:108 test-9:109]
fmt.Println(score)
}
看到了吧,两次遍历输出结果都是不一样的,当然你在运行这段代码的时候,结果大概率与上面输出也是不同的。而且,遍历过程中,想修改键key对应的值value也要注意方式,变量k,v只是当前访问的键值对的拷贝,直接修改变量v没有任何意义。
看到上述代码,突然想到一个问题:如果遍历过程中,往map新增键值对,会怎么样?新增的键值对会再次被遍历访问到吗?遍历过程会无限持续吗?
package main
import "fmt"
func main() {
//map声明初始化
score := make(map[string]int, 0)
//key-value键值对存储
for i := 0; i < 3; i ++ {
score[fmt.Sprintf("test-%v", i)] = i
}
//map[test-0:0 test-1:1 test-2:2]
fmt.Println(score)
for k, v := range score {
score[fmt.Sprintf("%v-%v", k, v)] = v + 1
}
//8 map[test-0:0 test-0-0:1 test-0-0-1:2 test-1:1 test-1-1:2 test-1-1-2:3 test-2:2 test-2-2:3]
fmt.Println(len(score),score)
}
貌似遍历过程并没有无限持续。初始map键值对数目为3,遍历过程中新增键值对,如果新增的键值对不会再次被遍历访问到,理论上结束后map键值对数目应该为6,但是结果却显示8,键值对数目接近为原来的2倍多,而且观察输出结果,很明显,新增的键值对再次被遍历访问到了。为什么最终键值对数目为8呢?其实这也是一个随机现象,多次运行,你会发现map包含的键值对数据以及数目都是随机的。为什么呢?这里先保留一个疑问,后面会详细说明。
最后还有一个小小的问题,map作为函数输入参数时,函数中修改了map(修改/删除/新增键值对),在函数调用方,map会同步发生改变吗?len会改变吗?会和切片现象一样吗?
package main
import "fmt"
func main() {
score := make(map[string]int, 0)
score["zhangsan"] = 100
fmt.Println(len(score), score) //1 map[zhangsan:100]
testMap(score)
fmt.Println(len(score), score) //2 map[lisi:90 zhangsan:100]
}
func testMap(m map[string]int) {
m["lisi"] = 90
fmt.Println(len(m), m) //2 map[lisi:90 zhangsan:100]
}
map数据,len竟然都发生改变了!说好的Go语言函数按值传参呢,map存储的键值对会发生改变还能理解,参考切片,底层数组或者是什么结构可以共用,可是len为什么也会改变呢?这里先保留一个疑问,后面会详细说明。不过在讲解之前,可以先思考下,len应该改变吗?
实现原理
map也可以称为hash表,字典,其是如何实现O(1)的增删改查时间复杂度呢?学习过数据结构的读者应该都知道,一般有两种方式:开放寻址法和拉链法。最常用的当属拉链法了,基于数组+链表实现,先使用散列函数将键key映射到数组索引(如:计算hash值,并按数组长度取模),因为不同的键key可能映射到同一个数组索引,所以多个键值对形成链表。
Go语言map采取的就是拉链法,只是还做了一些小小的优化。原始方案链表节点存储键值对,每个节点还包含next指针,这样算下来内存利用率其实是较低的;Go语言将多个元素压缩到同一个链表节点(8个),相当于8个key-value键值对才需要一个next指针,内存利用率自然比原始方案高。另外,因为CPU高速缓存(L1、L2、L3)存在,连续内存访问的性能一般要高于分散内存访问,即8个key-value键值对连续存储的访问性能略好。
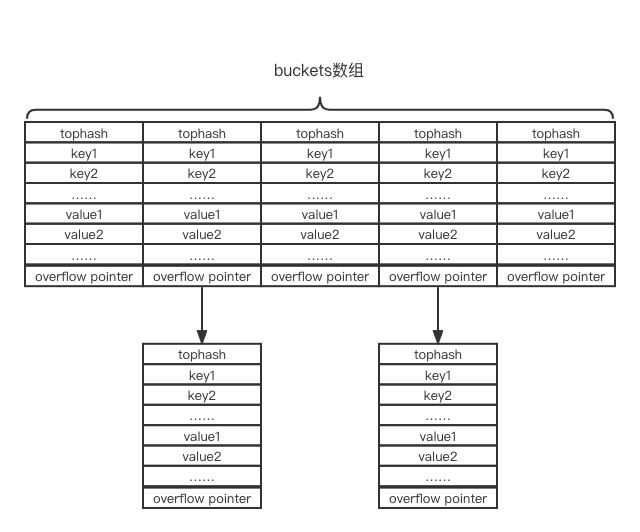
Go语言map结构如下图所示,buckets就是我们所说的数组,可以看到链表节点存储多个key-value键值对,并且多个key连续存储,再跟着多个value连续存储:
前面介绍的map初始化以及增删改查基本操作,底层都对应有函数实现,定义在文件runtime/map.go:
//make第二个参数,小于等于8对应makemap_small函数
func makemap_small() *hmap
func makemap(t *maptype, hint int, h *hmap) *hmap
//根据key查找对应value,只返回值;对应v = map[key]写法
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
//根据key查找对应value,返回两个变量:1)值;2)key是否存在。对应v, ok = map[key]写法
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
//新增或者修改键值对
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
//删除键值对
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)
在介绍这些基本操作之前,先了解下map相关结构的定义:
type hmap struct {
count int // 键值对数目,len返回的就是该值
B uint8 // 数组buckets长度为 2^B
buckets unsafe.Pointer // buckets数组
}
// bucketCnt = 8
type bmap struct {
// tophash generally contains the top byte of the hash value for each key in this bucket
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
buckets指向数组首地址,bmap就是链表节点的结构定义,但是其定义只有一个tophash字段,看不出什么多个key多个value连续存储。需要说明的是,实际怎么访问bmap内容就看你的代码怎么写了,其实与结构定义没有太大关系,毕竟变量访问无非只需要地址+长度就行了。读者可以阅读这里的注释了,详细说明了tophash字段后面还跟着多个key,多个value,以及overflow指针(就是next指针)。而变量dataOffset就是第一个键key首地址相对于结构体bmap首地址的偏移量。
注意tophash字段,uint8数组,注释解释到,其存储的是键key的hash值的高字节;hash值类型为int64,占8字节,而最高字节内容就存储在tophash数组。tophash用于快速比较键key的hash值是否相等,计算方式如下:
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8)) //PtrSize为8字节
if top < minTopHash { //minTopHash = 5,强制tophash值大于minTopHash
top += minTopHash
}
return top
}
为什么tophash值必须大于minTopHash呢?因为小于minTopHash的值有特殊标识,用于提升键key查找效率。比如:
//当前位置没有存储键值对,且当前桶后续位置也都没有存储键值对
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
//当前位置没有存储键值对
emptyOne = 1 // this cell is empty
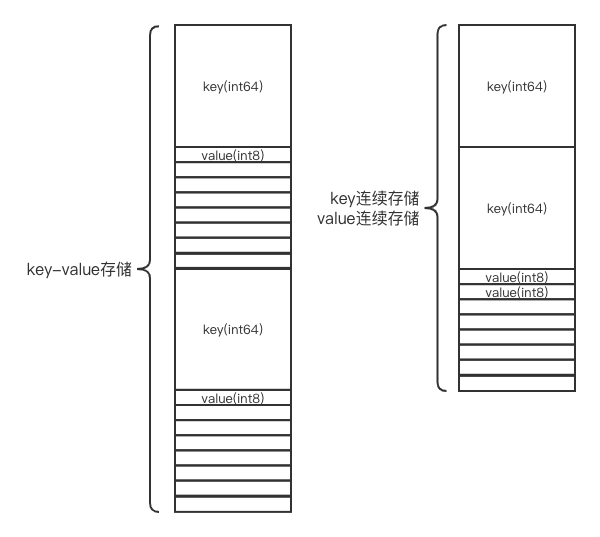
另外,思考下为什么要连续存储多个key,再跟着连续存储多个value呢?为什么不能按key-value键值对对存储呢?这就涉及都内存对齐了,不同类型的变量有内存对齐要求,比如int64首地址必须按8字节对齐(首地址是8的倍数),int32首地址必须按照4字节对齐,int8无要求。所以针对map[int64]int8,两种存储方式很明显会有如下区别:
好了,我们了解到map底层结构为hmap,其包含底层buckets数组,键值对数目等,再观察上面介绍的基本操作函数声明,map初始化函数makemap返回hmap指针,map新增/修改键值对函数mapassign输入参数为hmap指针,删除键值对函数mapdelete输入参数为hmap指针。那么当map作为参数传递呢?其传递的也是hmap指针,那么函数内部修改了map数据,调用方是否同步改变呢?len是否改变呢?答案很明显了。
最后,基于这两个结构,map是如何实现增删改查等基本操作呢?我们已新增/修改键值对为例,其实现函数为mapassign。该函数查找map,如果找到对应key,则替换值value;如果没有找到对应key,需要找到一个空的bmap位置,存储该键值对。注意学习下面代码时,结合buckets与bmap示意图更容易理解。
//省略了部分代码
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//计算数组索引
bucket := t.hasher(key, uintptr(h.hash0)) & bucketMask(h.B)
//buckets桶数组存储的其实就是bmap结构,该结构大小为bucketsize
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
//计算tophash值
top := tophash(hash)
//记录查找到的可存储键值对位置
var inserti *uint8 //该位置可存储tophash值
var insertk unsafe.Pointer //该位置可存储键key
var elem unsafe.Pointer //该位置可存储值value
bucketloop:
for {
//遍历该bmap 8个位置;比较tophash值,比较key
for i := uintptr(0); i < bucketCnt; i++ {
//如果tophash值不相等,说明键key肯定不想等
if b.tophash[i] != top {
//如果当前位置没有存储键值对,且inserti为空,首次记录该位置可存储键值对
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
//bmap首地址偏移dataOffset就是第一个键key存储位置,第i个键key,再偏移i个键key即可。
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//计算第i个值value地址,bmap首地址偏移dataOffset,再偏移8个键key,再偏移i个值value即可。
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
//emptyRest说明当前桶后续位置也都没有存储键值对,即map中不存在该键key;则新插入键值对到inserti位置。
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//获取键key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//判断查找到的键和输入key是否相等
if !t.key.equal(key, k) {
continue
}
//key相等,则更新对应的值value
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
goto done
}
//该bmap没有找到对应key,但是如果overflow不为空,则查找链表下一个bmap
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
//没有查找到对应key,需要新增键值对
//没有找到一个新位置,则需要申请新的bmap
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
//剩下就是保存新增键值数据到inserti,insertk,elem
}
函数mapassign的注意逻辑都写清楚了注释。当然还有一些细节暂时省略了,比如新增键值对的时候还需要判断是否需要扩容,否则链表越来越长,map的时间复杂度将退化为O(N)。map的其他操作,如访问mapaccess1,删除mapdelete与新增/修改mapassign比较类似,核心都是找到bmap,遍历匹配键key,这里就不再介绍了。
迭代/遍历
还记得我们遗留的两个问题吗,1)for range遍历map时,多次遍历的访问顺序为什么不同呢?2)for range遍历过程中,新增键值对,最终的键值对数目为什么也是随机的呢?针对问题1,其实这是Go语言专门设计的,本身map的遍历顺序就与插入顺序不一致,Go语言设计者,为了让开发人员不要依赖map的遍历顺序,更是将map的遍历顺序设计为随机的。
如何遍历map每一个键值对呢?我们知道hmap结构维护有一个buckets数组,数组元素类型为bmap,bmap又通过overflow指针形成链表。那么,我们只需要遍历buckets数组,遍历bmap链表,也就能完成map所有键值对的遍历访问。map迭代/遍历依赖两个函数,其中hiter维护当前访问到的位置,以及键值对信息:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)
type hiter struct {
//键值对
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
//当前遍历的bmap
bptr *bmap // current bucket
//当前map已遍历了几个键值对
i uint8
//开始遍历的bucket位置
startBucket uintptr // bucket iteration started at
//偏移量,每一个bmap从该偏移量开始遍历
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
//当前遍历的bucket位置
bucket uintptr
}
函数mapiterinit初始化迭代器hiter,包括开始遍历的bucket位置(随机),每一个bmap开始遍历的偏移量(随机)。正因为这两个值的随机性,才导致map的遍历顺序随机。
func mapiterinit(t *maptype, h *hmap, it *hiter) {
//随机
r := uintptr(fastrand())
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
//获取第一个键值对
mapiternext(it)
}
函数mapiternext用于访问下一个键值对,只需要从当前bmap(hiter.bptr),当前偏移位置(hiter.i + hiter.offset)开始查找下一个键值对即可。如果当前bmap遍历完毕,通过overflow获取下一个bmap;如果当前bucket所有bmap都已遍历完毕,bucket++;而最终再次遍历到hiter.startBucket时,说明当前map已遍历完毕。这里就不再详述,有兴趣的读者可以自己研究下函数mapiternext实现。
所以for range遍历map的伪代码应该如下:
iter := &hiter{}
mapiterinit(map, iter)
for {
if iter.key == nil {
//遍历结束
break
}
k, v := iter.key, iter.elem
//用户代码
//访问下一个键值对
mapiternext(iter)
}
map的遍历过程我们都很清楚了,现在是否能回答上面遗留的问题呢:遍历过程中,新增键值对,遍历过程并没有无限持续,map最终的键值对数目竟然是随机的!其实不难理解,新增的键值对会存储在哪一个bucket呢?不知道,由键key的hash值决定;每次遍历从哪一个bucket开始呢?不知道,完全随机。那这就对了,如果新增的键值对,刚好存储在未遍历过的位置;那么就会再次访问到,如果刚好存储在已遍历过的位置,那么就不会再次访问到。所以,新增的键值对能否再次被访问到也是随机的,所以,map最终的键值对数目也是随机的。
扩容
扩容是什么?map为什么需要扩容呢?想想假如初始化时,map的buckets数组长度为8,一直往map新增键值对,会出现什么情况?buckets数组上挂的bmap链表越来越长,这时候map的时间复杂度还是O(1)吗?已经退化为O(N)了!所以,map需要扩容,需要更大的buckets数组。
那么map什么时候需要扩容呢?这里有一个概念叫负载因子,其表示最大可存储的键值对数目除以buckets数组长度。当map存储的键值对数目超过buckets数组长度乘以负载因子时,触发扩容操作。那么负载因子应该是多少呢?要知道,当buckets数组长度固定时,负载因子越小,可存储的键值对越少,而一个bmap就能存储8个键值对,键值对过少会浪费bmap内存空间;负载因子越大,可存储的键值对越多,键值对过多bmap链表越长时间复杂度又越高。Go语言作者通过简单的程序,测试不同负载因子下,map的一些指标:
// loadFactor %overflow bytes/entry hitprobe missprobe
// 4.00 2.13 20.77 3.00 4.00
// 4.50 4.05 17.30 3.25 4.50
// 5.00 6.85 14.77 3.50 5.00
// 5.50 10.55 12.94 3.75 5.50
// 6.00 15.27 11.67 4.00 6.00
// 6.50 20.90 10.79 4.25 6.50
// 7.00 27.14 10.15 4.50 7.00
// 7.50 34.03 9.73 4.75 7.50
// 8.00 41.10 9.40 5.00 8.00
//
// %overflow = percentage of buckets which have an overflow bucket
// bytes/entry = overhead bytes used per key/elem pair
// hitprobe = # of entries to check when looking up a present key
// missprobe = # of entries to check when looking up an absent key
最终,选取的负载因子是6.5。扩容的时候,一般buckets数组长度扩大2倍,申请新的buckets数组,同时需要将老的buckets数组所有键值对迁移到新的buckets数组,这就需要重新计算hash值,计算buckets数组索引,重新查找bmap空闲位置。要注意,扩容也不是一次性完成的,即键值对的搬迁是逐步分批次完成的,所以在这期间,同时存在两个buckets数组,这时候,map的增删改查该访问哪个buckets数组呢?
其实也是有迹可循的:1)新增/删除/修改键值对,如果当前map正在扩容,计算键key在oldbuckets数组索引,迁移该bucket所有键值对到新buckets数组,继续执行原有新增/删除/修改键值对逻辑;2)键值对查找,如果当前map正在扩容,计算键key在oldbuckets数组b索引,该bucket即为需要查找的bmap。问题来了,如何计算键key在oldbuckets数组索引呢?上面说了,扩容时,buckets数组长度是扩大两倍的,有键key的hash值,有数组长度,计算数组索引还不容易吗?键值对迁移逻辑可以参照下面两个函数:
//oldbucket是需要迁移的oldbuckets数组索引,逻辑省略
func evacuate(t *maptype, h *hmap, oldbucket uintptr)
//判断该bucket键值对是否已经迁移
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > emptyOne && h < minTopHash
}
//判断是否生在扩容
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
所以,假如需要频繁操作map时,并且已经知道需要存储的键值对数目,比如转化切片到map,这时候使用make初始化map,可以指定初始buckets数组长度,避免不必要的扩容。
并发问题
我们都知道Go语言具有天然的并发优势,go func可以很方便的创建一个并发协程。那么,假如有一个全局的map,在多个协程中并发操作map呢?可以这么操作吗?我们写个小程序测试一下:
package main
import (
"fmt"
"time"
)
func main() {
var m = make(map[string]int, 0)
//创建10个协程
for i := 0; i <= 10; i ++ {
go func() {
//协程内,循环操作map
for j := 0; j <= 100; j ++ {
m[fmt.Sprintf("test_%v", j)] = j
}
}()
}
//主协程休眠3秒,否则主协程结束了,子协程没有机会执行
time.Sleep(time.Second * 3)
fmt.Println(m)
}
运行之前可以猜一下执行结果。程序panic了,异常信息为:"fatal error: concurrent map writes"。很明确,并发写map导致的panic,也就是说,我们不能在多个协程并发执行map写操作,这一点要特别注意,初次写Go语言很容易犯这个错。
其实在函数mapassign很容易找到这些逻辑:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//如果并发写map,报错
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
//记录当前map正在执行写操作
h.flags ^= hashWriting
//执行结束后,再次判断
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
}
那假如确实想在多个协程并发操作map怎么办?这就需要采取其他方案了,比如加锁,比如使用并发安全map(sync.Map),这些将在后面章节并发编程详细介绍。
总结
map就介绍到这里了,要好好理解Go语言map基本结构,包括buckets数组,bmap结构。map在函数传参时的一些现象也不同于slice,map遍历的随机性也需要注意,而map并发访问panic记得千万要避免。
有疑问加站长微信联系(非本文作者))



