
Go语言天然具备并发特性,基于go关键字就能很方便的创建协程去执行一些并发任务,而且基于协程-管道的CSP并发编程模型,相比于传统的多线程同步方案,可以说简单太多了。从本篇文章开始,将为大家介绍Go语言的核心:并发编程;不仅包括协程/管道/锁等的基本使用,还会深入到协程实现原理,GMP协程调度模型等。
并发编程入门
设想下我们有这么一个服务/接口:需要从其他三个服务获取数据,处理后返回给客户端,并且这三个服务不互相依赖。这时候一般如何处理呢?如果PHP语言开发,一般可能就是顺序调用这些服务获取数据了;如果是Java之类的支持多线程的语言,为了提高接口性能,通常可能会开启多个线程并发获取这些服务的数据。Go语言使用多协程去执行多个可并行子任务非常简单,使用方式如下所示:
package main
import (
"fmt"
"sync"
)
func main() {
//WaitGroup用于协程并发控制
wg := sync.WaitGroup{}
//启动3个协程并发执行任务
for i := 0; i < 3; i ++ {
asyncWork(i, &wg)
}
//主协程等待任务结束
wg.Wait()
fmt.Println("main end")
}
func asyncWork(workId int, wg *sync.WaitGroup){
//开始异步任务
wg.Add(1)
go func() {
fmt.Println(fmt.Sprintf("work %d exec", workId))
//异步任务结束
wg.Done()
}()
}
main函数默认在主协程执行,而且一旦main函数执行结束,也意味这主协程执行协程,整个Go程序就会结束(与多线程程序比较类似)。主协程需要等待子协程任务执行结束,但是协程的调度执行确实随机的,go关键字只是创建协程,通常并不会立即调度执行该协程;所以如果没有一些同步手段,主协程可能以及执行完毕了,子协程还没有调度执行,也就是任务还没开始执行。sync.WaitGroup常用于多协程之间的并发控制,wg.Add标记一个异步任务的开始,主协程wg.Wait会一直阻塞,直到所有异步任务执行结束,所以我们再异步任务的最后调用了方法wg.Done,标记当前异步任务执行结束。这样当子协程全部执行完毕后,主协程就会解除阻塞。不过还有一个问题,主协程如何获取到子协程的返回数据呢?想想最简单的方式,函数asyncWork添加一个指针类型的输入参数,作为返回值呢?或者也能通过管道chan实现协程之间的数据传递。
管道chan用于协程直接的数据传递,想象一下,数据从管道一端写入,另外一端就能读取到该数据。设想我们有一个消息队列的消费脚本,获取到一条消息之后,需要执行比较复杂/耗时的处理,Go语言怎么处理比较好呢?拉取消息,处理,ack确认,如此循环吗?肯定不太合适,这样消费脚本的性能太低了。通常是启动一个协程专门用于从消息队列拉取消息,再将消息交给子协程异步处理,这样大大提升了消费脚本性能。而主协程就是通过管道chan将消息交给子协程去处理的。
package main
import (
"fmt"
"time"
)
func main() {
//声明管道chan,最多可以存储10条消息;该容量通常限制了异步任务的最大并发量
queue := make(chan int, 10)
//开启10个子协程异步处理
for i := 0; i < 10; i ++ {
go asyncWork(queue)
}
for j := 0; j < 1000; j++ {
//向管道写入消息
queue <- j
}
time.Sleep(time.Second)
}
func asyncWork(queue chan int){
//子协程死循环从管道chan读取消息,处理
for {
data := <- queue
fmt.Println(data)
}
}
管道chan可以声明多种类型,如chan int只能存储int类型数据;chan还有容量的改变,也就是最大能存储的数据量,如果chan容量已经满了,向chan写入数据会阻塞,所以通常可以通过容量限制异步任务的最大并发量。另外,如果chan没有数据,从chan读取数据也会阻塞。上面程序启动了10个子协程处理消息,而主协程循环向chan写入数据,模拟消息的消费过程。
在使用Go语言开发过程中,通过会有这样的需求:某些任务需要定时执行;Go语言标准库time提供了定时器相关功能,time.Ticker是定时向管道写入数据,我们可以通过监听/读取管道,实现定时功能:
package main
import (
"fmt"
"time"
)
func main() {
//定时器每秒向管道ticker.C写入数据
ticker := time.NewTicker(time.Second)
for {
//chan没有数据时,读取操作阻塞;所以循环内<- ticker.C一秒返回一次
<- ticker.C
fmt.Println(time.Now().String())
}
}
最后,我们再回顾一下讲解map的时候提到,并发写map会导致panic异常;假如确实有需求,需要多协程操作全局map呢?这时候可以用sync.map,这是并发安全的;另外也可以通过加锁方式实现map的并发访问:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
lock := sync.Mutex{}
var m = make(map[string]int, 0)
//创建10个协程
for i := 0; i <= 10; i ++ {
go func() {
//协程内,循环操作map
for j := 0; j <= 100; j ++ {
//操作之前加锁
lock.Lock()
m[fmt.Sprintf("test_%v", j)] = j
//操作之后释放锁
lock.Unlock()
}
}()
}
//主协程休眠3秒,否则主协程结束了,子协程没有机会执行
time.Sleep(time.Second * 3)
fmt.Println(m)
}
sync.Mutex是Go语言提供的排他锁,可以看到我们在操作map之前执行Lock方法加锁,操作map时候通过Unlock方法释放锁;这时候运行程序就不会出现panic异常了。不过要注意的是,锁可能会导致当前协程长时间阻塞,所以在C端高并发服务中,要慎用锁。
GMP调度模型基本概念
在介绍Go语言协程调度模型之前,我们先思考几个问题:
- 到底什么是协程呢?多协程为什么能并发执行呢?想想我们了解的线程,每一个线程都有一个栈桢,操作系统负责调度线程,线程切换必然伴随着栈桢的切换。协程有栈桢吗?协程的调度由谁维护呢?
- 都说协程是用户态线程,用户态是什么意思呢?协程与线程又有什么关系呢?协程的创建以及切换不需要陷入内核态吗?
- Go语言是如何管理以及调度这些成千上万个协程呢?和操作系统一样,维护着可运行队列和阻塞队列吗,有没有所谓的按照时间片或者是优先级或者是抢占式调度呢?
- 用户程序读写socket的时候,可能阻塞当前协程,难道读写socket都是阻塞式调用吗?Go语言是如何实现高性能网络IO呢?有没有用传说中的epoll呢?
- Go程序如何执行系统调用呢?要知道操作系统只能感知到线程,而系统调用可能会阻塞当前线程,线程阻塞了,那么协程呢?
这些问题你可能了解一些,可能不了解,不了解也不用担心,从本篇文章开始,将为你详细介绍Go语言的协程调度模型,看完之后,这些问题将不在话下。
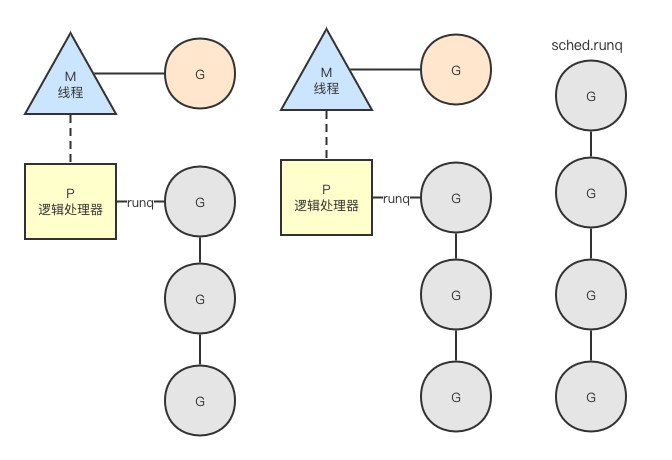
说起GMP,可能都或多或少了解一些,G是协(goroutine)程,M是线程(machine),P是逻辑处理器(processor);那么为什么要这么设计呢?
想想之前我们所熟知的线程,其由操作系统调度;现在我们需要创建协程,协程由谁调度呢?当然是我们的线程在执行调度逻辑了。那这么说,我只需要维护一个协程队列,再有个线程就能调度这些协程了呗,还需要P干什么?Go语言v1.0确实就是这么设计的。但是要知道Go语言服务通常会有多个线程,多个线程从全局协程队列获取可运行协程时候,是不是就需要加锁呢?加锁就意味着低效。
所以后面引入了P(P就只是一个由很多字段的数据结构而已,可以将P理解成为一种资源),一般P的数目会和系统CPU核数保持一致,;M想要调度协程,需要获取并绑定P,P只能被一个M占有,每个P都维护有协程队列,那这时候线程M调度协程,是不是只需要从当前绑定的P获取即可,也就不需要加锁了。后续很多设计都采取了这种思想,包括定时器,内存分配等逻辑,都是通过将共享数据关联到P上来避免加锁。另外,为了避免多个P负载分配不均衡,还有一个全局队列sched.runq(协程有些情况会添加到全局队列),如果当前P的协程队列为空,M还可以从全局队列查找可运行G,当然这时候就需要加锁了。
此时,GMP调度模型如下所示:
对GMP概念有了简单的了解后,该深究下我们的重点G了。协程到底是什么呢?创建一个协程只是创建了一个结构体变量吗?还需要其他什么吗?
同样的想想我们所熟知的线程,创建一个线程,操作系统会分配对应的线程栈,线程切换时候,操作系统会保存线程上下文,同时恢复另一个线程上下文。协程需要协程栈吗?要回答这个问题,先要说清楚线程栈是什么?如下图所示:
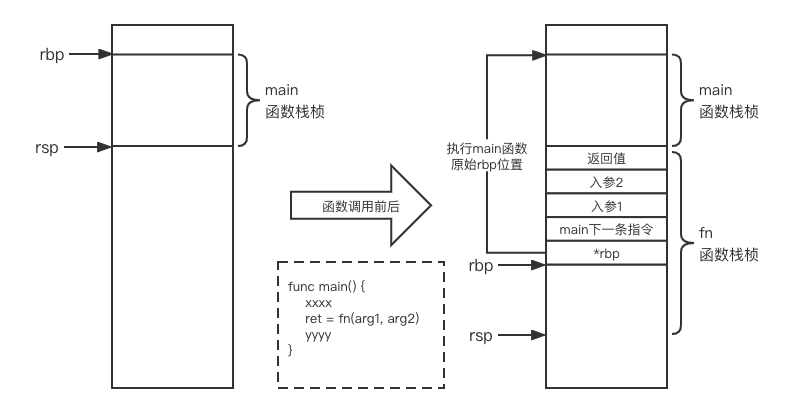
函数调用或者返回过程中,就伴随着函数栈桢的入栈以及出栈,我们函数中的局部变量,以及入参,返回值等,很多时候都是分配在栈上的。函数调用栈是有链接关系的,非常类似于单向链表结构。多个线程是需要并发执行的,那必然就存在多个函数调用栈。
协程需要并发执行吗?肯定需要。那协程肯定也需要协程栈,不然多个协程的函数调用栈不就混了。只是,线程创建后,操作系统自动分配线程栈,而操作系统压根不知道协程,怎么为其分配协程栈呢?
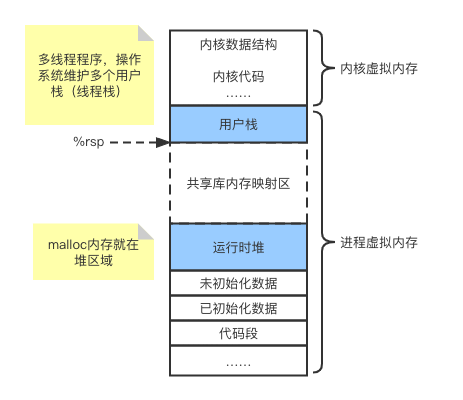
虚拟内存结构了解吗?如上图所示,虚拟内存被划分为代码段,数据段,堆,共享区,栈,内核区域。malloc分配的内存通常就在堆区,既然操作系统没办法为我们维护协程栈,那我们自己malloc一块内存,将其用作协程栈不就行了。可是,这明明是堆啊,函数栈桢的入栈时,怎么能入到这块堆内存呢?其实很简单,再回顾下上面的结构图,是不是有两个%rbp和%rsp指针?分别指向了当前函数栈桢的栈底和栈顶。%rbp和%rsp是两个寄存器,我们程序是可以改变它们的,只需要将其指向我们申请的堆内存,那么对操作系统而言,这块内存就是栈了,函数调用时新的函数栈桢就会从这块内存往下分配(寄存器%rsp向下移动),函数执行结束就会从这块内存回收函数栈桢(寄存器%rsp向上移动)。而协程间的切换,对Go语言来说,也不过是寄存器%rbp和%rsp的保存以及恢复了。
这下我们明白了,协程就是堆当栈用而已,每一个协程都对应一个协程栈;那么,调度程序呢?肯定也需要一个执行栈吧,创建协程M时,操作系统本身就帮我们维护了线程栈,而我们的调度程序直接使用这个线程栈就行了,Go语言将运行在这个线程栈的调度逻辑,称为g0协程。
GMP调度模型深入理解
协程创建/调度相关函数基本都定义在runtime/proc.go文件,go关键字在编译阶段会替换为函数runtime.newproc(fn * funcval),其中fn就是待创建协程的入口函数;协程调度主函数为runtime.schedule,该函数查询可运行协程并执行。另外,GMP模型中的G对应着结构 struct g,M对应着结构struct m,P对应着结构struct p。GMP定一如下
type m struct {
//g0就是调度"协程"
g0 *g // goroutine with scheduling stack
//当前正在调度执行的协程
curg *g // current running goroutine
//当前绑定的P
p puintptr // attached p for executing go code (nil if not executing go code)
}
type g struct {
//协程id
goid int64
//协程栈
stack stack // stack describes the actual stack memory: [stack.lo, stack.hi)
//当前协程在哪个M
m *m // current m;
//协程上下文,保存着当前协程栈的bp(%rbp)、sp(%rsp),pc(下一条指令地址)
sched gobuf
}
type p struct {
//状态:如空闲,正在运行(已经绑定在M上)等等
status uint32 // one of pidle/prunning/...
//当前绑定的m
m muintptr // back-link to associated m (nil if idle)
//协程队列(循环队列)
runq [256]guintptr
}
我们一直强调,M必须绑定P,才能调度协程。Go语言定义了多种P的状态,如被M绑定,如正在执行系统调用等等:
const (
// _Pidle means a P is not being used to run user code or the scheduler.
_Pidle = iota
// _Prunning means a P is owned by an M and is being used to run user code or the scheduler.
_Prunning
// _Psyscall means a P is not running user code.
_Psyscall //正在执行系统调用
// _Pgcstop means a P is halted for STW and owned by the M that stopped the world.
_Pgcstop //垃圾回收可能需要暂停所有用户代码,暂停所有的P
// _Pdead means a P is no longer used (GOMAXPROCS shrank)
_Pdead
)
结合GMP结构的定义,以及我们对协程栈的理解,可以得到下面的示意图:
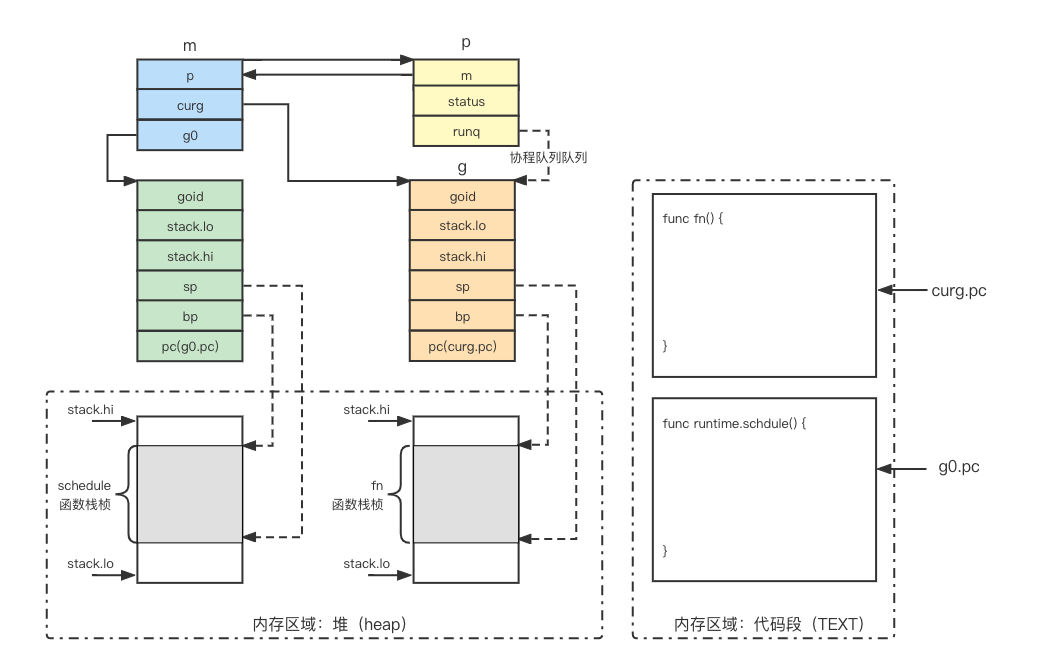
每一个M线程都有一个调度协程g0,调度协程执行schedule函数查询可运行协程并执行。每一个协程都有一个协程栈,这个栈不是操作系统维护的,而是Go语言在堆(heap)上申请的一块内存。gobuf定义了协程上下文结构,包括寄存器bp、sp(指向协程栈),以及寄存器pc(指向下一条指令地址,即代码段)。
现在应该理解了,为什么我们说协程是用户态线程。因为协程和线程一样可以并发执行,协程和线程一样拥有自己的栈桢;但是,操作系统只知道线程,协程是由Go语言也就是用户态代码调度执行的,并且协程的调度切换不需要陷入内核态(其实就是协程栈的切换),只需要在用户态保存以及恢复若干寄存器就行了。另外,我们常说的调度器其实可以理解为schedule函数,该函数运行在线程栈(Go语言中称之为调度栈)。
总结
本篇文章是并发编程的入门,简单介绍了协程、管道,锁等的基本使用;针对GMP并发模型,重点介绍了其基本概念,以及GMP的结构定义。为了掌握GMP概念,一定要重点理解虚拟内存结构,线程栈桢结构。
有疑问加站长微信联系(非本文作者))



