
  上一篇文章我们介绍了GMP并发模型的基本概念,知道了M是线程,P是逻辑处理器,G是协程。也了解到每一个M线程都有一个调度协程g0,调度主逻辑由函数schedule实现;协程都有自己的协程栈,协程的切换其实就是协程栈的切换,其实就是若干寄存器的保存与恢复。本篇文章重点介绍协程的管理,包括协程创建,协程切换;但是,涉及到寄存器的更改,只能深入到汇编去理解,可能会比较枯燥难以理解,可以根据自己兴趣学习研究。
## 基础补充-栈桢结构
  我们一直说每一个线程都有一个线程栈,每一个协程也需要一个协程栈,这里说的栈其实就是函数调用栈桢,通常我们函数内声明的局部变量,函数的传参等,其实都在线程栈/协程栈上。为什么这里称之为栈呢?因为函数的调用与返回,刚好是先入后出,函数的调用伴随着函数栈桢的入栈,函数的返回伴随着函数栈桢的出栈。多个函数栈桢之间是通过BP以及SP寄存器维护的。
  另外,我们还需要知道,所有的高级语言,不管是PHP还是Java还是Go,最终机器上执行的都是一条一条汇编指令(应该说是二进制指令,汇编只是方便人们识别的助记符);函数调用指令是CALL,函数返回指令是RET。CALL以及RET与其他指令如MOVE有一些不同,背后还有一些稍微复杂的逻辑:
```
//PC寄存器指向的是下一条指令地址;CPU加载指令时,会自动PC + 1;所以可以通过修改PC寄存器的内容,实现程序跳转
//CALL fn
PUSH PC //PUSH将PC内容入栈(其实也就是 SP = PC;SP = SP - 8)
JMP fn //程序跳转到函数fn入口地址
//RET
POP PC //POP弹出栈顶内容,也就是之前PUSH的PC寄存器内容
JMP //程序跳转到PC执行的地址
```
  最后,寄存器BP以及SP的维护,查看编译后的汇编程序就能看到,比如:
```
"".fn STEXT
//SP栈顶向下移动(函数栈桢入栈),当前函数可能会定义一些局部变量等,所以预留一些内存
SUBQ $96, SP
//下一步需要更高BP寄存器内容,所以将BP寄存器保存在SP+88字节位置处
MOVQ BP, 88(SP)
//更改BP寄存器内容
LEAQ 88(SP), BP
//业务逻辑
//局部变量通常以XX(SP)形式访问,也就是在SP+XX字节位置处
//恢复原始BP寄存器内容
MOVQ 88(SP), BP
//SP栈顶向上移动(函数栈桢出栈)
ADDQ $96, SP
//函数返回
RET
```
  调用fn函数前后的栈桢结构如下图所示:
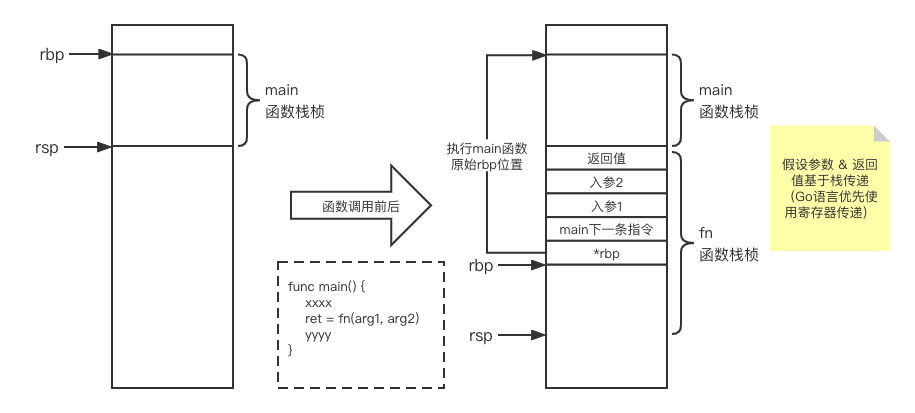
  这里需要我们重点理解CALL & RET指令的含义,以及调用fn函数前后的栈桢变化。因为Go语言在协程创建的时候,需要构造协程栈,也就是上图中的栈桢结构。
## 基础补充-线程本地存储
  线程本地存储(Thread Local Storage,简称TLS),其实就是线程私有全局变量。普通的全局变量,一个线程对其进行了修改,所有线程都可以看到这个修改;线程私有全局变量不同,每个线程都有自己的一份副本,某个线程对其所做的修改不会影响到其它线程的副本。
  Golang是多线程程序,当前线程正在执行的协程,显然每个线程都是不同的,这就维护在线程本地存储。所以在Go协程切换逻辑中,随处可见get_tls(CX),用于获取当前线程本地存储首地址。
  不同的架构以及操作系统,可以通过FS或者GS寄存器访问线程本地存储,如Go程序,386架构Linux操作系统时,通过如下方式访问:
```
//"386", "linux"
"#define get_tls(r) MOVL 8(GS), r\n"
//获取线程本地存储首地址
get_tls(CX)
//结构体G封装协程相关数据,DX存储着当前正在执行协程G的首地址
//协程调度时,保存当前协程G到线程本地存储
MOVQ DX, g(CX)
```
## 基础补充-汇编简介
  任何架构的计算机都会提供一组指令集合,汇编是二进制指令的文本形式。指令由操作码和操作数组成;操作码即操作类型,操作数可以是一个立即数或者一个存储地址(内存,寄存器)。寄存器是集成在CPU内部,访问非常快,但是数量有限的存储单元。Golang使用plan9汇编语法,汇编指令的写法以及寄存器的命名略有不同
  下面简单介绍一些常用的指令以及寄存器:
- MOVQ $10, AX:数据移动指令,该指令表示将立即数10存储在寄存器AX;AX即通用寄存器,常用的通用寄存器还有BX,CX,DX等等;注意指令后缀『Q』表示数据长度为8字节;
- ADDQ AX, BX:加法指令,等价于 BX += AX;
- SUBQ AX, BX:减法指令,等价于 BX -= AX;
- JMP addr:跳转道addr地址处继续执行;
- JMP 2(PC):CPU如何加载指令并执行呢?其实有个专用寄存器PC(等价于%rip),他指向下一条待执行的指令。该语句含义是,以当前指令为基础,向后跳转2行;
- FP:伪寄存器,通过symbol+offset(FP)形式,引用函数的输入参数,例如 arg0+0(FP),arg1+8(FP);
- 硬件寄存器SP:等价于上面出现过的%rsp,执行函数栈帧顶部位置);
- CALL func:函数调用,包含两个步骤,1)将下一条指令的所在地址入栈(还需要恢复到这执行);2)将func地址,存储在指令寄存器PC;
- RET:函数返回,功能为,从栈上弹出指令到指令寄存器PC,恢复调用方函数的执行(CALL指令入栈);
  更多plan9知识参考:https://xargin.com/plan9-assembly
  下面写一个go程序,看看编译后的汇编代码:
```
package main
func addSub(a, b int) (int, int){
return a + b , a - b
}
func main() {
addSub(333, 222)
}
```
  汇编代码查看:go tool compile -S -N -l test.go
```
"".addSub STEXT nosplit size=49 args=0x20 locals=0x0
0x0000 00000 (test.go:3) MOVQ $0, "".~r2+24(SP)
0x0009 00009 (test.go:3) MOVQ $0, "".~r3+32(SP)
0x0012 00018 (test.go:4) MOVQ "".a+8(SP), AX
0x0017 00023 (test.go:4) ADDQ "".b+16(SP), AX
0x001c 00028 (test.go:4) MOVQ AX, "".~r2+24(SP)
0x0021 00033 (test.go:4) MOVQ "".a+8(SP), AX
0x0026 00038 (test.go:4) SUBQ "".b+16(SP), AX
0x002b 00043 (test.go:4) MOVQ AX, "".~r3+32(SP)
0x0030 00048 (test.go:4) RET
"".main STEXT size=68 args=0x0 locals=0x28
0x000f 00015 (test.go:7) SUBQ $40, SP
0x0013 00019 (test.go:7) MOVQ BP, 32(SP)
0x0018 00024 (test.go:7) LEAQ 32(SP), BP
0x001d 00029 (test.go:8) MOVQ $333, (SP)
0x0025 00037 (test.go:8) MOVQ $222, 8(SP)
0x002e 00046 (test.go:8) CALL "".addSub(SB)
0x0033 00051 (test.go:9) MOVQ 32(SP), BP
0x0038 00056 (test.go:9) ADDQ $40, SP
0x003c 00060 (test.go:9) RET
```
  分析main函数汇编代码:SUBQ $40, SP为自己分配栈帧区域,LEAQ 32(SP), BP,移动BP寄存器到自己栈帧结构的底部。MOVQ $333, (SP)以及MOVQ $222, 8(SP)在准备输入参数。
  分析addSub函数汇编代码:"".a+8(SP)即输入参数a,"".b+16(SP)即输入参数b。两个返回值分别在24(SP)以及32(SP)。
  注意:addSub函数,并没有通过SUBQ $xx, SP以,来为自己分配栈帧区域。因为addSub函数没有再调用其他函数,也就没有必要在为自己分配函数栈帧区域了。
  另外,注意main函数,addSub函数,是如何传递与引用输入参数以及返回值的。
## 协程创建
  go关键字在编译阶段会替换为函数runtime.newproc(fn * funcval),其中fn就是待创建协程的入口函数。协程创建肯定是需要分配协程栈内存的,执行过程稍微复杂,不适合在协程栈执行(协程栈比较小,Go语言默认2K字节,执行过于复杂的逻辑可能导致栈溢出),所以协程创建的逻辑都会切换到线程栈(即系统栈),协程创建完毕后,再切换到原来的栈。函数runtime.systemstack(fn func())切换到系统栈执行函数fn,完毕后再切换到原来的栈,使用方式如下:
```
func newproc(fn *funcval) {
systemstack(func() {
newg := newproc1(fn, gp, pc)
//将g添加到P的协程队列
_p_ := getg().m.p.ptr()
runqput(_p_, newg, true)
})
}
```
  可以看到,协程创建的主要逻辑,其实是由runtime.newproc1实现的,而通过函数runqput可以将当前协程g添加到当前M绑定P的协程队列。函数runtime.newproc1不仅仅要申请协程栈内存,还需要构造初始的栈桢结构,包括设置BP & SP栈寄存器,以及PC指令寄存器。
```
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
//_StackMin = 2048
newg = malg(_StackMin)
//sp指向栈顶(stack.hi为栈最高地址,预留totalSize)
sp := newg.stack.hi - totalSize
newg.sched.sp = sp
//goexit为协程退出函数
newg.sched.pc = goexit
//构造栈桢结构,fn为协程入口函数(省略了一层调用)
gostartcall(&newg.sched, fn)
//设置协程状态:可运行
casgstatus(newg, xxx, _Grunnable)
//协程ID
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
return newg
}
//申请栈内存,初始化g结构
func malg(stacksize int32) *g {
newg := new(g)
//申请内存
newg.stack = stackalloc(uint32(stacksize))
//stackguard0用于保护栈,避免栈溢出;函数调用过程中,sp不能小于stackguard0位置
newg.stackguard0 = newg.stack.lo + _StackGuard
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
return newg
}
//构造栈桢结构
func gostartcall(buf *gobuf, fn) {
//buf.pc即goexit,保存到栈顶
sp := buf.sp
sp -= goarch.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
//设置上下文sp pc
buf.sp = sp
buf.pc = uintptr(fn)
}
```
  可以看到,申请栈内存时最小2048=2K字节,目前linux系统线程栈默认大小一般为8M,也就是说协程占用的资源远小于线程,所以才会说协程是轻量级的线程。stackguard0是为了防止栈溢出的,编译阶段Go语言在函数入口会添加一些逻辑:判断SP寄存器是否小于stackguard0,如果小于说明栈即将溢出,此时可以直接抛异常,也可以触发栈扩容等。最后注意到,整个过程只是创建了协程,并没有立即运行该协程,而是将协程状态赋值为可运行Grunnable,随后添加将其添加到P的协程队列,等待M调度。
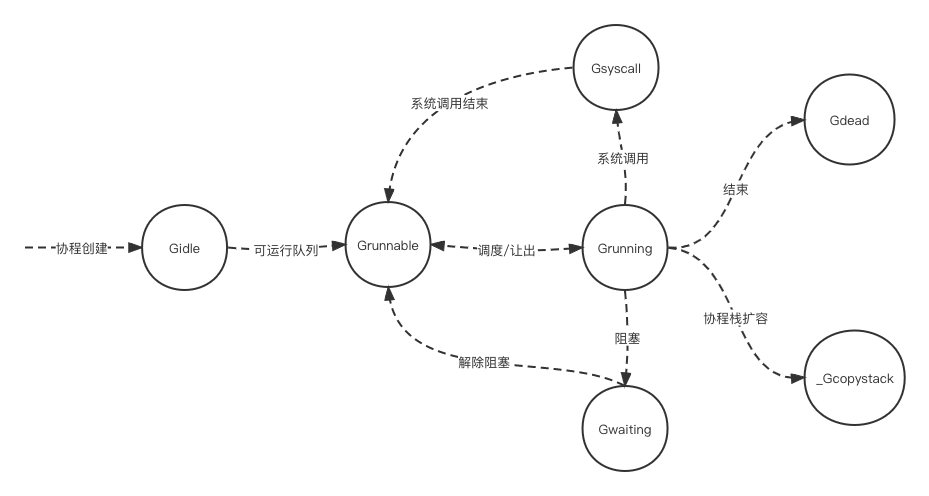
  协程可以在队列中等待调度,或者被M调度执行,或者因为获取锁等原因阻塞,或者执行完毕。协程与线程类似,有多个状态,可以在不同状态之间转移,Go语言定义的协程状态如下:
```
// _Gidle means this goroutine was just allocated and has not yet been initialized.
_Gidle = iota // 0
// _Grunnable means this goroutine is on a run queue
_Grunnable // 1
// _Grunning means this goroutine may execute user code
_Grunning // 2
// _Gsyscall means this goroutine is executing a system call.
_Gsyscall // 3
// _Gwaiting means this goroutine is blocked in the runtime.
_Gwaiting // 4
// _Gdead means this goroutine is currently unused. It may be just exited, on a free list
_Gdead // 6
// _Gcopystack means this goroutine's stack is being moved.
_Gcopystack // 8
```
  各状态转移图如下:
## 协程(栈)切换
  协程调度主函数为runtime.schedule,查找到可运行协程之后,通过runtime.gogo函数切换到协程栈,这个函数就只能看到汇编代码了,因为要操作寄存器:
```
// func gogo(buf *gobuf)
TEXT runtime·gogo(SB), NOSPLIT, $0-8
MOVQ buf+0(FP), BX // gobuf包含协程上下文:栈寄存器BP、SP,指令寄存器PC
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
JMP gogo<>(SB)
TEXT gogo<>(SB), NOSPLIT, $0
get_tls(CX) //线程本地存储
MOVQ DX, g(CX) //存储待执行协程g到线程本地存储
MOVQ DX, R14 //存储待执行协程g到R14寄存器(其他地方会用到R14寄存器)
MOVQ gobuf_sp(BX), SP //根据gobuf上下文,设置各寄存器
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
MOVQ $0, gobuf_sp(BX) // 清空gobuf各字段内容,以减轻垃圾回收负担(指针字段不为空时,垃圾回收需要扫描)
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
MOVQ gobuf_pc(BX), BX
JMP BX
```
  协程g.gobuf存储了协程上下文数据,包括栈桢寄存器BP、SP,以及指令寄存器PC,所以runtime.gogo只需要根据gobuf恢复各寄存器即可。为了在各函数中能快速获取当前执行协程,将当前执行协程g存储在了线程本地存储(也就是M的私有存储);另外,当前执行协程还保存到了R14寄存器,协程因为某些原因阻塞换出的时候,就用到了R14寄存器。
  需要特别注意,gobuf_sp、gobuf_bp之类的,并不是汇编语法,其实是宏定义,编译阶段自动生成这些宏定义。gobuf_sp的含义是:sp字段在gobuf结构的偏移量,即offset(gobuf,sp)。
  协程换出是通过runtime.gopark函数实现的,最终是通过runtime.mcall函数保存当前函数上下文,同时切换到系统栈执行调度算法。
```
// func mcall(fn func(*g))
// Switch to m->g0's stack, call fn(g).
// Fn must never return. It should gogo(&g->sched)
// to keep running g.
TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8
MOVQ AX, DX // DX = fn
// 保存协程上下文,R14寄存器就是当前协程g
MOVQ 0(SP), BX // caller's PC
MOVQ BX, (g_sched+gobuf_pc)(R14)
LEAQ fn+0(FP), BX // caller's SP
MOVQ BX, (g_sched+gobuf_sp)(R14)
MOVQ BP, (g_sched+gobuf_bp)(R14)
//要求当前协程g != m->g0
// switch to m->g0 & its stack, call fn
MOVQ g_m(R14), BX
MOVQ m_g0(BX), SI // SI = g.m.g0
CMPQ SI, R14 // if g == m->g0 call badmcall
JNE goodm
JMP runtime·badmcall(SB)
goodm:
MOVQ R14, AX // AX (and arg 0) = g
MOVQ SI, R14 // g = g.m.g0
get_tls(CX) // Set G in TLS
MOVQ R14, g(CX)
MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp;设置栈顶寄存器SP
PUSHQ AX // open up space for fn's arg spill slot;设置fn参数,也就是即将换出的协程g
MOVQ 0(DX), R12
CALL R12 // fn(g);调用fn
POPQ AX
JMP runtime·badmcall2(SB)
RET
```
  runtime.mcall函数用于切换到系统栈,执行函数fn,runtime.systemstack函数也是切换到系统栈,执行函数fn。不同的是:systemstack执行完fn,返回;而mcall要求fn函数永远不能返回,否则抛出panic异常。
## 协程栈会溢出吗
  协程就是轻量级的线程,创建协程时申请的协程栈大小只有2K,这挺好的。不过,你有没有想过,如果协程比较复杂,函数调用层级过深,会出现什么情况,比如你运行下面的程序:
```
package main
import "fmt"
func main() {
r := fn(100000)
fmt.Println(r)
}
func fn(n int) int {
var arr [100000]int
for i := 0; i < 10; i ++ {
arr[i] = i
}
return fn(n-1) + 1
}
```
  这个程序没有任何意义,只是为了模拟深层次的函数调用。执行后,你会发现,程序异常终止了:"runtime: goroutine stack exceeds 1000000000-byte limit"。协程栈超过1000000000-byte大小限制了,也就是栈溢出了。初始协程栈不是只有2K吗,大小限制怎么能是1000000000-byte呢?
  想想要是协程栈大小真的最多只有2K大小,是不是太小了,也太容易出现栈溢出情况了。可是创建协程时申请的协程栈大小只有2K啊,难道函数调用过程中,协程栈扩容了?你猜对了。协程栈只有发生函数调用时,才有可能需要扩容,所以Go语言编译阶段,在所有用户函数,都加了一点代码逻辑,判断栈顶指针SP小于某个位置时,说明栈空间不足,需要扩容了;这个位置就是stackguard0。我们看看main函数的汇编代码:
```
"".main STEXT
0x0000 00000 (test.go:5) CMPQ SP, 16(R14)
0x0004 00004 (test.go:5) JLS 176
0x00b0 00176 (test.go:5) CALL runtime.morestack_noctxt(SB)
0x00e0 00224 (test.go:10) JMP 0
```
  R14寄存器就是当前协程g,想想结构体g的第一个字段stack占16字节,第二个字段就是stackguard0,所以这里比较栈顶SP寄存器与16(R14)地址大小;如果小于说明栈空间不足,调用runtime.morestack_noctxt。函数morestack_noctxt也是汇编写的,一系列判断之后,最终调用了函数runtime.newstack执行扩容等操作。待扩容之后,又跳转到该函数第一条指令执行。
  扩容一般按照2倍大小扩容,如果扩容后大小超过maxstacksize限制(64位机器就是1000000000-byte),则抛异常。
  栈扩容并没有我们想的那么简单,只需要申请内存,拷贝数据就行了。想想万一某些指针变量指向了栈地址呢?栈扩容拷贝之后,指针变量还需要特殊处理(根据新的栈首地址与老的栈首地址偏移量重新计算)。另外,其实还有一些其他你想不到的"数据"也是需要处理的。可以参考runtime.copystack函数:
```
func copystack(gp *g, newsize uintptr) {
//拷贝数据
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
//调整特殊数据
adjustsudogs(gp, &adjinfo)
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
adjustframe()
}
```
## 协程结束
  想象下,如果某协程的处理函数为funcA,funcA执行完毕,相当于该协程的结束。这之后该怎么办?肯定需要执行特定的回收工作。注意到上面协程创建的时候有一个函数,runtime·goexit,看名字协程结束时候应该执行这个函数。如何在funcA执行完毕后,调用runtime·goexit呢?
  思考下函数调用过程,函数funcA执行完毕时候,存在一个RET指令,该指令会弹出下一条待执行指令到指令寄存器PC,从而实现指令的跳转。我们再回顾协程创建的实现逻辑:
```
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
//goexit为协程退出函数
newg.sched.pc = goexit
//构造栈桢结构,fn为协程入口函数(省略了一层调用)
gostartcall(&newg.sched, fn)
return newg
}
//构造栈桢结构
func gostartcall(buf *gobuf, fn) {
//buf.pc即goexit,保存到栈顶
sp := buf.sp
sp -= goarch.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
}
```
  函数gostartcall首先将runtime·goexit首地址入栈,此后执行fn的时候才是fn函数栈桢入栈。因此协程fn执行结束后,RET弹出的指令就是函数runtime·goexit首地址,从而开始了协程回收工作。而函数runtime·goexit,则标记协程状态为Gmoribund,开始新一次的协程调度(会切换到g0调度)
```
void runtime·goexit(void)
{
mcall(goexit0)
}
//已经在系统栈了
func goexit0(gp *g) {
//设置协程状态,执行回收操作
casgstatus(gp, _Grunning, _Gdead)
//调度
schedule()
}
```
## 总结
  这一篇文章确实比较难,需要熟悉汇编,熟悉函数调用栈桢结构,否则肯定会看的云里雾里的。本篇文章重点介绍了协程创建,协程切换,协程结束,协程栈扩充等的简单实现原理,相信这下你能明白为什么说协程是轻量级的、用户态的线程了。
有疑问加站长微信联系(非本文作者))




