到现在为止,我已经忘记了我在写什么,但我确定这篇文章是关于Go语言的。这主要是一篇,关于运行速度,而不是开发速度的文章——这两种速度是有区别的。
我曾经和很多聪明的人一起工作。我们很多人都对性能问题很痴迷,我们之前所做的是尝试逼近能够预期的(性能)的极限。应用引擎有一些非常严格的性能要求,所以我们才会做出改变。自从使用了Go语言之后,我们已经学习到了很多提升性能以及让Go在系统编程中正常运转的方法。
Go的简单和原生并发使其成为一门非常有吸引力的后端开发语言,但更大的问题是它如何应对延迟敏感的应用场景?是否值得牺牲语言的简洁性使其速度更快?让我们来一起看一下Go语言性能优化的几个方面:语言特性、内存管理、并发,并根据这些做出合适的优化决策。所有这里介绍的测试代码都在这里.
一、Channels
Channel在Go语言中受到了很多的关注,因为它是一个方便的并发工具,但是了解它对性能的影响也很重要。在大多数场景下它的性能已经“足够好”了,但是在某些延时敏感的场景中,它可能会成为瓶颈。Channel并不是什么黑魔法。在Channel的底层实现中,使用的还是锁。在没有锁竞争的单线程应用中,它能工作的很好,但是在多线程场景下,性能会急剧下降。我们可以很容易的使用无锁队列ring buffer来替代channel的功能。
第一个性能测试对比了单线程buffer channel和ring buffer(一个生产者和一个消费者)。先看看单核心的情况(GOMAXPROCS = 1)
BenchmarkChannel 3000000 512 ns/op
BenchmarkRingBuffer 20000000 80.9 ns/op
正如你所看到的,ring buffer大约能快6倍(如果你不熟悉Go的性能测试工具,中间的数字表示执行次数,最后一个数组表示每次执行花费的时间)。接下来,我们再看下调整GOMAXPROCS = 8的情况。
BenchmarkChannel-8 3000000 542 ns/op
BenchmarkRingBuffer-8 10000000 182 ns/op
ring buffer快了近三倍。
Channel通常用于给worker分配任务。在下面的测试中,我们对比一下多个reader读取同一个channel或者ring buffer的情况。设置GOMAXPROCS = 1 测试结果表明channel在单核程应用中性能表现尤其的好。
BenchmarkChannelReadContention 10000000 148 ns/op
BenchmarkRingBufferReadContention 10000 390195 ns/op
然而,ring buffer在多核心的情况下速度更快些:
BenchmarkChannelReadContention-8 1000000 3105 ns/op
BenchmarkRingBufferReadContention-8 3000000 411 ns/op
最后,我们来看看多个reader和多个writer的场景。从下面的对比同样能够看到ring buffer在多核心时更好些。
BenchmarkChannelContention 10000 160892 ns/op
BenchmarkRingBufferContention 2 806834344 ns/op
BenchmarkChannelContention-8 5000 314428 ns/op
BenchmarkRingBufferContention-8 10000 182557 ns/op
ring buffer只使用CAS操作达到线程安全。我们可以看到,在决定选择channel还是ring buffer时很大程度上取决于系统的核数。对于大多数系统, GOMAXPROCS> 1,所以无锁的ring buffer往往是一个更好的选择。Channel在多核心系统中则是一个比较糟糕的选择。
二、defer
defer是提高可读性和避免资源未释放的非常有用的关键字。例如,当我们打开一个文件进行读取时,我们需要在结束读取时关闭它。如果没有defer关键字,我们必须确保在函数的每个返回点之前关闭文件。
func findHelloWorld(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
scanner := bufio.NewScanner(file)
for scanner.Scan() {
if scanner.Text() == "hello, world!" {
file.Close()
return nil
}
}
file.Close()
if err := scanner.Err(); err != nil {
return err
}
return errors.New("Didn't find hello world")
}这样很容易出错,因为很容易在任何一个return语句前忘记关闭文件。defer则通过一行代码解决了这个问题。
func findHelloWorld(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
if scanner.Text() == "hello, world!" {
return nil
}
}
if err := scanner.Err(); err != nil {
return err
}
return errors.New("Didn't find hello world")
}
view rawdefer.go hosted with ❤ by GitHub乍一看,人们会认为defer明可能会被编译器完全优化掉。如果我只是在函数的开头使用了defer语句,编译器确实可以通过在每一个return语句之前插入defer内容来实现。但是实际情况往往更复杂。比如,我们可以在条件语句或者循环中添加defer。第一种情况可能需要编译器找到应用defer语句的条件分支. 编译器还需要检查panic的情况,因为这也是函数退出执行的一种情况。通过静态编译提供这个功能(defer)似乎(至少从表面上看)是不太可能的。
derfer并不是一个零成本的关键字,我们可以通过性能测试来看一下。在下面的测试中,我们对比了一个互斥锁在循环体中加锁后,直接解锁以及使用defer语句解锁的情况。
BenchmarkMutexDeferUnlock-8 20000000 96.6 ns/op
BenchmarkMutexUnlock-8 100000000 19.5 ns/op
使用defer几乎慢了5倍。平心而论,77ns也许并不那么重要,但是在一个循环中它确实对性能产生了影响。通常要由开发者在性能和代码的易读性上做权衡。优化从来都是需要成本的。
三、Refection与JSON
Reflection通常是缓慢的,应当避免在延迟敏感的服务中使用。JSON是一种常用的数据交换格式,但Go的encoding/json库依赖于反射来对json进行序列化和反序列化。使用ffjson(译者注:easyjson会更快),我们可以通过使用代码生成的方式来避免反射的使用,下面是性能对比。
BenchmarkJSONReflectionMarshal-8 200000 7063 ns/op
BenchmarkJSONMarshal-8 500000 3981 ns/opBenchmarkJSONReflectionUnmarshal-8 200000 9362 ns/op
BenchmarkJSONUnmarshal-8 300000 5839 ns/op
(ffjson)生成的JSON序列化和反序列化比基于反射的标准库速度快38%左右。当然,如果我们对编解码的性能要求真的很高,我们应该避免使用JSON。MessagePack是序列化代码一个更好的选择。在这次测试中我们使用msgp库跟JSON的做了对比。
BenchmarkMsgpackMarshal-8 3000000 555 ns/op
BenchmarkJSONReflectionMarshal-8 200000 7063 ns/op
BenchmarkJSONMarshal-8 500000 3981 ns/opBenchmarkMsgpackUnmarshal-8 20000000 94.6 ns/op
BenchmarkJSONReflectionUnmarshal-8 200000 9362 ns/op
BenchmarkJSONUnmarshal-8 300000 5839 ns/op
这里的差异是显着的。即使是跟(ffjson)生成的代码相比,MessagePack仍然快很多。
如果我们真的很在意微小的优化,我们还应该避免使用interface类型, 它需要在序列化和反序列化时做一些额外的处理。在一些动态调用的场景中,运行时调用也会增加一些额外 开销。编译器无法将这些调用替换为内联调用。
BenchmarkJSONReflectionUnmarshal-8 200000 9362 ns/op
BenchmarkJSONReflectionUnmarshalIface-8 200000 10099 ns/op
我们再看看调用查找,即把一个interface变量转换为它真实的类型。这个测试调用了同一个struct的同一个方法。区别在于第二个变量是一个指向结构体的一个指针。
BenchmarkStructMethodCall-8 2000000000 0.44 ns/op
BenchmarkIfaceMethodCall-8 1000000000 2.97 ns/op
排序是一个更加实际的例子,很好的显示了性能差异。在这个测试中,我们比较排序1,000,000个结构体和1,000,000个指向相同结构体的interface。对结构体进行排序比对interface进行排序快92%。
BenchmarkSortStruct-8 10 105276994 ns/op
BenchmarkSortIface-8 5 286123558 ns/op
总之,如果可能的话避免使用JSON。如果确实需要用JSON,生成序列化和反序列化代码。一般来说,最好避免依靠反射和interface,而是编写使用的具体类型。不幸的是,这往往导致很多重复的代码,所以最好以抽象的这个代码生成。再次,权衡得失。
四、内存管理
Go实际上不暴露堆或直接堆栈分配给用户。事实上,“heap”和“stack”这两个词没有出现在Go语言规范的任何地方。这意味着有关栈和堆东西只在技术上实现相关。实际上,每个goroutine确实有着自己堆和栈。编译器确实难逃分析,以确定对象是在栈上还是在堆中分配。
不出所料的,避免堆分配可以成为优化的主要方向。通过在栈中分配空间(即多使用A{}的方式创建对象,而不是使用new(A)的方式),我们避免了昂贵的malloc调用,如下面所示的测试。
BenchmarkAllocateHeap-8 20000000 62.3 ns/op 96 B/op 1 allocs/op
BenchmarkAllocateStack-8 100000000 11.6 ns/op 0 B/op 0 allocs/op
自然,通过指针传值比通过对象传世要快,因为前者需要复制唯一的一个指针,而后者需要复制整个对象。下面测试结果中的差异几乎是可以忽略的,因为这个差异很大程度上取决于被拷贝的对象的类型。注意,可能有一些编译器对对这个测试进行一些编译优化。
BenchmarkPassByReference-8 1000000000 2.35 ns/op
BenchmarkPassByValue-8 200000000 6.36 ns/op
然而,heap空间分配的最大的问题在于GC(垃圾回收)。如果我们生成了很多生命周期很短的对象,我们会触发GC工作。在这种场景中对象池就派上用场了。在下面的测试用,我们比较了使用堆分配与使用sync.Pool的情况。对象池提升了5倍的性能。
BenchmarkConcurrentStructAllocate-8 5000000 337 ns/op
BenchmarkConcurrentStructPool-8 20000000 65.5 ns/op
需要指出的是,Go的sysc.Pool在垃圾回收过程中也会被回收。使用sync.Pool的作用是复用垃圾回收操作之间的内存。我们也可以维护自己的空闲对象列表使对象不被回收,但这样可能就让垃圾回收失去了应有的作用。Go的pprof工具在分析内存使用情况时非常有用的。在盲目做内存优化之前一定要使用它来进行分析。
五、False Sharing
当性能真的很重要时,你必须开始硬件层次的思考。著名的一级方程式车手杰基·斯图尔特曾经说过,“要成为一个赛车手你不必成为一名工程师,但你必须有机械知识。”深刻理解一辆汽车的内部工作原理可以让你成为一个更好的驾驶员。同样,理解计算机如何工作可以使你成为一个更好的程序员。例如,内存如何布局的?CPU缓存如何工作的?硬盘如何工作的?
内存带宽仍然是现代CPU的有限资源,因此缓存就显得极为重要,以防止性能瓶颈。现在的多核处理器把数据缓存在cache line中,大小通常为64个字节,以减少开销较大的主存访问。为了保证cache的一致性,对内存的一个小小的写入都会让cache line被淘汰。对相邻地址的读操作就无法命中对应的cache line。这种现象叫做false sharing。 当多个线程访问同一个cache line中的不同数据时这个问题就会变得很明显。
想象一下,Go语言中的一个struct是如何在内存中存储的,我们用之前的ring buffer 作为一个示例,结构体可能是下面这样:
type RingBuffer struct {
queue uint64
dequeue uint64
mask, disposed uint64
nodes nodes
}queue和dequeue字段分别用于确定生产者和消费者的位置。这些字段的大小都是8byte,同时被多个线程并发访问和修改来实现队列的插入和删除操作,因为这些字段在内存中是连续存放的,它们仅仅使用了16byte的内存,它们很可能被存放在同一个cache line中。因此修改其中的任何一个字段都会导致其它字段缓存被淘汰,也就意味着接下来的读取操作将会变慢。也就是说,在ring buffer中添加和删除元素会导致很多的CPU缓存失效。
我们可以给结构体的字段直接增加padding.每一个padding都跟一个CPU cache line一样大,这样就能确保ring buffer的字段被缓存在不同的cache line中。下面是修改后的结构体:
type RingBuffer struct {
_padding0 [8]uint64
queue uint64
_padding1 [8]uint64
dequeue uint64
_padding2 [8]uint64
mask, disposed uint64
_padding3 [8]uint64
nodes nodes
}
实际运行时会有多少区别呢?跟其他的优化一样,优化效果取决于实际场景。它跟CPU的核数、资源竞争的数量、内存的布局有关。虽然有很多的因素要考虑,我们还是要用数据来说话。我们可以用添加过padding和没有padding的ring buffer来做一个对比。
首先,我们测试一个生产者和一个消费者的情况,它们分别运行在一个gorouting中.在这个测试中,两者的差别非常小,只有不到15%的性能提升:
BenchmarkRingBufferSPSC-8 10000000 156 ns/op
BenchmarkRingBufferPaddedSPSC-8 10000000 132 ns/op
但是,当我们有多个生产者和多个消费者时,比如各100个,区别就会得更加明显。在这种情况下,填充的版本快了约36%。
BenchmarkRingBufferMPMC-8 100000 27763 ns/op
BenchmarkRingBufferPaddedMPMC-8 100000 17860 ns/op
False sharing是一个非常现实的问题。根据并发和内存争的情况,添加Padding以减轻其影响。这些数字可能看起来微不足道的,但它已经起到优化作用了,特别是在考虑到在时钟周期的情况下。
六、无锁共享
无锁的数据结构对充分利用多核心是非常重要的。考虑到Go致力于高并发的使用场景,它不鼓励使用锁。它鼓励更多的使用channel而不是互斥锁。
这就是说,标准库确实提供了常用的内存级别的原子操作, 如atomic包。它提供了原子比较并交换,原子指针访问。然而,使用原子包在很大程度上是不被鼓励的:
We generally don’t want sync/atomic to be used at all…Experience has shown us again and again that very very few people are capable of writing correct code that uses atomic operations…If we had thought of internal packages when we added the sync/atomic package, perhaps we would have used that. Now we can’t remove the package because of the Go 1 guarantee.
实现无锁有多困难?是不是只要用一些CAS实现就可以了?在了解了足够多的知识后,我认识到这绝对是一把双刃剑。无锁的代码实现起来可能会非常复杂。atomic和unsafe包并不易用。而且,编写线程安全的无锁代码非常有技巧性并且很容易出错。像ring buffer这样简单的无锁的数据结构维护起来还相对简单,但是其它场景下就很容易出问题了。
Ctrie是我写的一篇无锁的数据结构实现,这里有详细介绍尽管理论上很容易理解,但事实上实现起来非常复杂。复杂实现最主要的原因就是缺乏双重CAS,它可以帮助我们自动比较节点(去检测tree上的节点突变),也可以帮助我们生成节点快照。因为没有硬件提供这样的操作,需要我们自己去模拟。
第一个版本的Ctrie实现是非常失败的,不是因为我错误的使用了Go的同步机制,而是因为对Go语言做了错误的假设。Ctrie中的每个节点都有一个和它相关联的同伴节点,当进行快照时,root节点都会被拷贝到一个新的节点,当树中的节点被访问时,也会被惰性拷贝到新的节点(持久化数据结构),这样的快照操作是常数耗时的。为了避免整数溢出,我们使用了在堆上分配对象来区分新老节点。在Go语言中,我们使用了空的struct。在Java中,两个新生成的空object是不同的,因为它们的内存地址不同,所以我假定了Go的规则也是一样的。但是,结果是残酷的,可以参考下面的文档:
A struct or array type has size zero if it contains no fields (or elements, respectively) that have a size greater than zero. Two distinct zero-size variables may have the same address in memory.
所以悲剧的事情发生了,两个新生成的节点在比较的时候是相等的,所以双重CAS总是成功的。这个BUG很有趣,但是在高并发、无锁环境下跟踪这个bug简直就是地狱。如果在使用这些方法的时候,第一次就没有正确的使用,那么后面会需要大量的时间去解决隐藏的问题,而且也不是你第一次做对了,后面就一直是对的。
但是显而易见,编写复杂的无锁算法是有意义的,否则为什么还会有人这么做呢?Ctrie跟同步map或者跳跃表比起来,插入操作更耗时一些,因为寻址操作变多了。Ctrie真正的优势是内存消耗,跟大多的Hash表不同,它总是一系列在tree中的keys。另一个性能优势就是它可以在常量时间内完成线性快照。我们对比了在100个并发的条件下对synchronized map 和Ctrie进行快照:
BenchmarkConcurrentSnapshotMap-8 1000 9941784 ns/op
BenchmarkConcurrentSnapshotCtrie-8 20000 90412 ns/op
在特定的访问模式下,无锁数据结构可以在多线程系统中提供更好的性能。例如,NATS消息队列使用基于synchronized map的数据结构来完成订阅匹配。如果使用无锁的Ctrie,吞吐量会提升很多。下图中的耗时中,蓝线表示使用基于锁的数据结构的实现,红线表示无锁的数据结构的实现
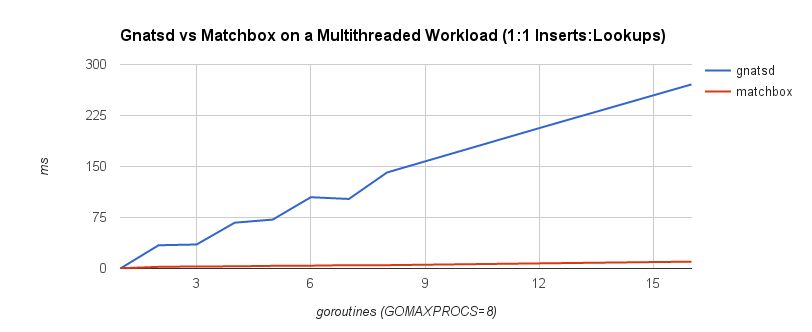
在特定的场景中避免使用锁可以带来很好的性能提升。从ring buffer和channel的对比中就可以看出无锁结构的明显优势。然而,我们需要在编码的复杂程度以及获得的好处之间进行权衡。事实上,有时候无锁结构并不能提供任何实质的好处。
七、优化的注意事项
正如我们从上面的讨论所看到的,性能优化总是有成本的。认识和理解优化方法仅仅是第一步。更重要的是理解应该在何时何处取使用它们。引用 C. A. R. Hoare的一句名言,它已经成为了适用所有编程人员的经典格言:
The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.
但这句话的观点不是反对优化,而是让我们学会在速度之间进行权衡——算法的速度、响应速度、维护速度以及系统速度。这是一个很主观的话题,而且没有一个简单的标准。过早进行优化是错误的根源吗?我是不是应该先实现功能,然后再优化?或者是不是根本就不需要优化?没有标准答案。有时候先实现功能再提升速度也是可以的。
不过,我的建议是只对关键的路径进行优化。你在关键路径上走的越远,你优化的回报就会越低以至于近乎是在浪费时间。能够对性能是否达标做出正确的判断是很重要的。不要在此之外浪费时间。要用数据驱动——用经验说话,而不是出于一时兴起。还有就是要注重实际。给一段时间不是很敏感的代码优化掉几十纳秒是没有意义的。比起这个还有更多需要优化的地方。
八、总结
如果你已经读到了这里,恭喜你,但你可能还有一些问题搞错了。我们已经了解到在软件中我们实际上有两种速度——响应速度和执行速度。用户想要的是第一种,而开发者追求的是第二种,CTO则两者都要。目前第一种速度是最重要的,只要你想让用户用你的产品。第二种速度则是需要你排期和迭代来实现的。它们经常彼此冲突。
也许更耐人寻味的是,我们讨论了一些可以让Go提升一些性能并让它在低延时系统中更可用的方法。Go语言是为简洁而生的,但是这种简洁有时候是有代价的。就跟前面两种速度的权衡一样,在代码的可维护性以及代码性能上也需要权衡。速度往往意味着牺牲代码的简洁性、更多的开发时间和后期维护成本。要明智的做出选择。



