
性能分析和调优是一种很强大的技术,用来验证是否满足客户关注的性能要求。性能分析常常被用来分析一个程序将大部分时间花在哪里了,并通过一个科学的方法来测试调优实践的效果。这个帖子使用一个 Go 语言编写的 HTTP 服务作为一个例子来定义一种性能分析和调优的普遍方法。go 特别适合性能分析和调优,因为它在它的标准库中提供了 pprof 剖析工具链。
策略
我们先尝试建立一个简单的框架来构建对程序的分析。我们将要尝试做的是使用数据引导我们得出结论,而不是基于直觉或者预感做出决定。为此我们将要:
- 确定我们要优化的维度(要求)
- 创建一个测试代码(harness)将事务负载到这个系统上
- 执行一个测试——(生成数据)
- 观察
- 分析——是否满足要求?
- 调优——科学方法——形成一个假说
- 执行实验代码来测试这个假说
简单的 HTTP 服务器架构
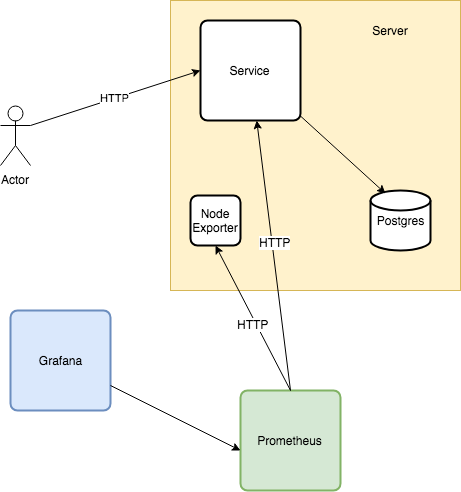
关于这个贴,我们将使用一个 Golang 编写的小型 HTTP 服务器。这个贴的所有代码都可以在 这里 找到。
我们将要分析的这个应用是一个每次请求都查询 PostgreSQL 的 HTTP 服务器。此外,通过 Prometheus, node_exporter, 和 Grafana 来收集和可视化应用和系统级的指标:
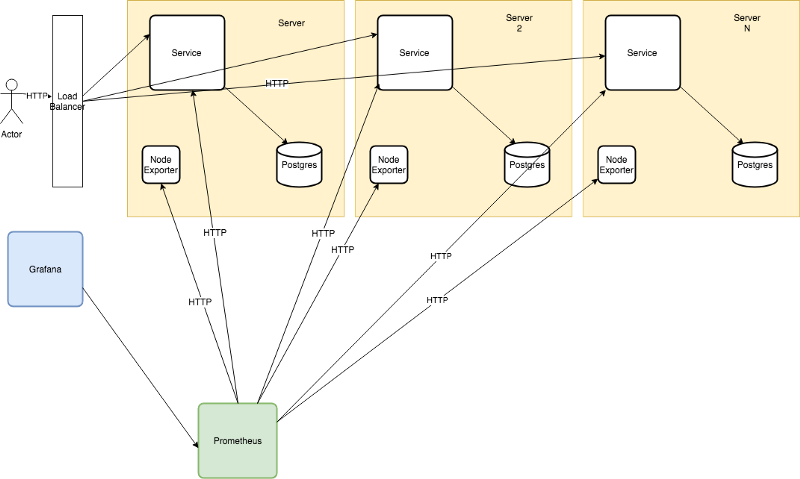
为简单起见,本文假设为了横向扩展(并简化我们的计算),每个 HTTP 服务和 Postgres 数据库将一起部署:
确定目标(维度)
这一步概述了特定的目标。我们将尝试分析什么?我们如何知道我们的努力已完成?
本文中,我们将假设客户端均衡在我们的服务上,每秒为 10000 请求量。
Google SRE Book 在如何选择和建模上有更深入的探讨。在 SRE 的精髓上,我们将建立我们的模型如下:
- 延迟—— 99% 的请求应该在 60 ms 内完成。
- 费用——这个服务应该在我们认为尽可能合理的最小费用内完成。为了达到这个目标,吞吐量应该最大化。
- 容量规划——对要求启动多少个实例和记录通常情况下的缩放能力的理解。我们需要满足预期初始负载要求并实现 n + 1 redundancy 的实例数量是多少?
延迟可能需要除了分析之外的优化,而吞吐量就只需要分析了。使用 SRE SLO 处理的延迟需求可能来自客户端或者产品拥有者所代表的事务。真正值得一说的是,我们的服务能够在一开始就满足这种承诺而不需要任何调整!
设置测试代码(test harness)
这个测试代码将应用一个固定总数的负载到我们的系统。为了分析 HTTP 服务的性能,数据将需要它来生成。
交互负载(transactional load)
这个测试代码只使用了 Vegeta 以可配置的速率来产生 HTTP 请求直到停止:
$ make load-test LOAD_TEST_RATE=50
echo "POST http://localhost:8080" | vegeta attack -body tests/fixtures/age_no_match.json -rate=50 -duration=0 | tee results.bin | vegeta report
观察
在执行一个”无止境“的交互负载期间(负载测试)。除了应用(请求速率,请求延迟)和系统级(内存,CPU,IOPS)的指标外,这时将通过剖析应用来理解它将时间花费在哪里了。
剖析(profiling)
profiling 是度量中的一类,让我们了解应用将时间花费到哪里了。它能够报告应用将时间花费在哪。Profileing 能够用来确定哪个函数正在被调用,并且应用在每个函数上花费了多少时间:
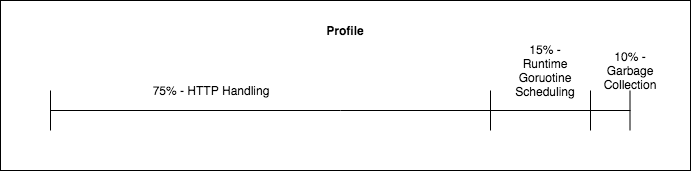
这个数据可以用来可视化分析程序将时间花在哪些不必要的工作上。Go(pprof)可以用来生成 profiles,并使用 标准工具链 将它们可视化为 火焰图 。在本文后面,我们将通过使用它们来引导调优的结论。
执行、观察、分析
我们开始执行这些实践。我们将执行,观察和分析直到我们的性能要求失效。先选择任意一个低的负载量来生成第一份观察报告和分析。如果每次的性能要求能够 hold 得住,我们就通过一个随机缩放因子(random-ish scaling factor)来增加负载。每次负载测试通过调整速率来执行:
make load-test LOAD_TEST_RATE=X
50 个请求 / 秒
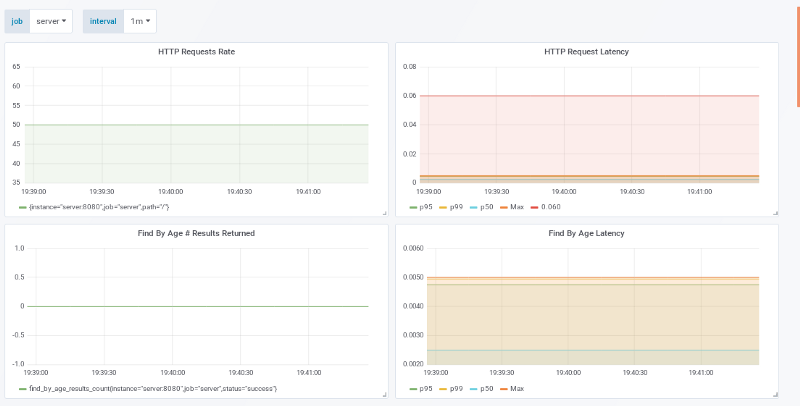
观察上面两张图。左上角的是我们的应用正在处理 50 个请求每秒,而右上角报告每个请求的延迟时间。将它们结合在一起来帮助我们观察和分析我们的性能要求是否满足。HTTP Request Latency 上的红线在 SLO 的 60ms 上。这个表示我们最大响应时间远远低于它。
在成本方面:
10k 请求量 / 秒 / 50 请求量 / 机器 = 200 台机器 + 1
我们就可以很好的支持了。
500 请求量 / 秒
当我们的请求数达到 500 请求量每秒时,事情开始变得有趣:
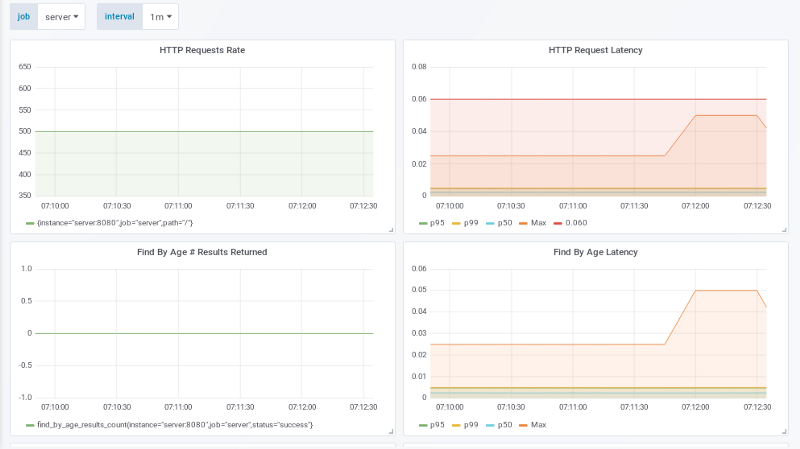
左上图再一次展示了应用的预期负载。如果它不是这样,它可能会在主机上判定是负载测试命令的问题或者是应用服务器的问题。右上角的延迟图展示了应对 500 请求量 / 秒时,每个 HTTP 请求的延迟时间在 25-40 ms 之间。99% 的请求仍然保持在 60 ms SLO 以下。
在成本方面:
10k 请求量 / 秒 / 500 请求量 / 机器 = 20 台机器 + 1
就可以很好的支持!
1000 请求量 / 秒
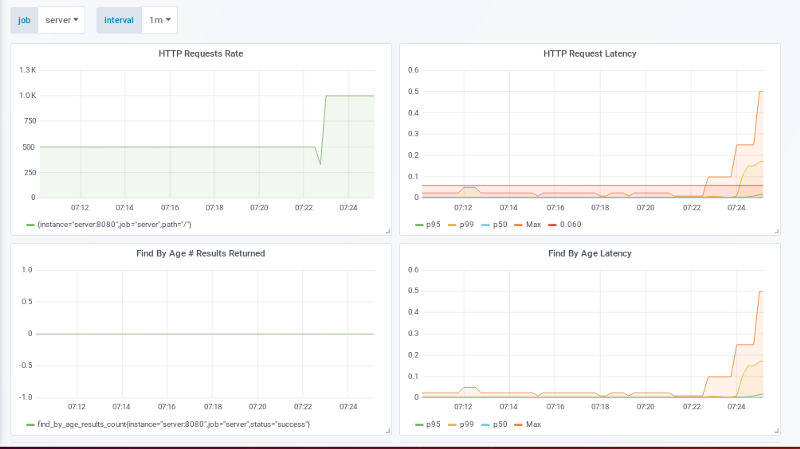
这个太大了!应用正在处理 1000 请求量 / 秒,但是延迟时间已经超过 SLO 的延迟量。这个可以看右上角(原文是左上角,可能打错了?)的图中的 P99 线。而尾部的 p100 max 远大于最大限制量的 60ms,P99 线也在 60ms 以上。是时候查看和剖析应用实际上正在做的事情了。
剖析(profile)
为了剖析,我们将使用 1000 请求量每秒的负载然后使用 pprof 来采样这些栈获得我们的程序将它的时间花费在哪些地方。这个可以在负载被使用时,通过 pprof 的 HTTP 端点,并用 curl 来跟踪:
$ curl http://localhost:8080/debug/pprof/profile?seconds=29 > CPU.1000_reqs_sec_no_optimizations.prof
这个跟踪可以被可视化:
$ Go tool pprof -http=:12345 CPU.1000_reqs_sec_no_optimizations.prof
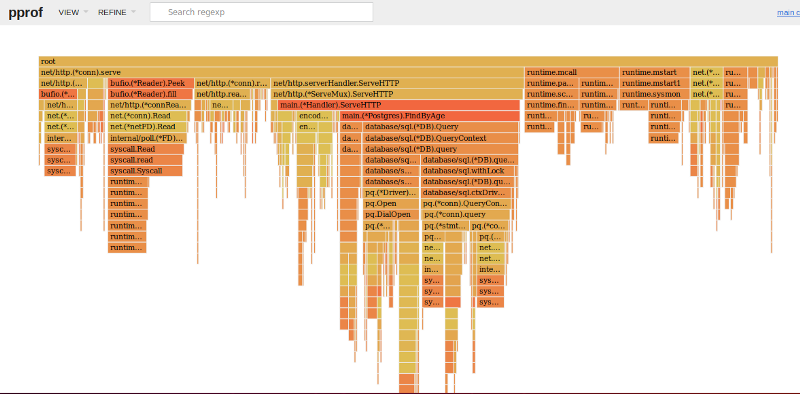
火焰图展示了应用在哪些地方花费时间和在那里花费了多少时间!来自 Brendan Gregg 的描述:
x 轴展示了栈的横截数量(profile population),按照字典序排列(注意,它不是通过调用时间长短排序的),y 轴表示栈的深度,从顶层以 0 开始计数。每个矩形表示一个栈帧。栈帧的宽度越宽,则它在栈中出现的次数越多。最底层显示的是正在 CPU 中运行的,在它上面的就是它的父函数。颜色通常没有意义,随机选择来区分不同的栈帧。
分析——假说
为了引导优化,我们将重点放在查找那些”无用功“。我们将尝试查找产生这些”无用功“的大部分源码,并删除它。因为剖析可以揭露出这个服务把时间花费在哪里了,这就需要从中找出潜在的重复工作,修改代码来改进它, 重新运行测试,并观察性能是否接近目标值。
根据 Bredan Gregg 的描述,go pprof 的火焰图是从上往下读的。每一行代表一个栈帧(函数调用)。第一行是这个程序的入口点,它是所有其他调用的父亲(即,所有其他调用的栈中都有第一行这个函数地址)。后面的行从这里分支出去:

在火焰图中的函数名上面停留会显示在跟踪期间,这个函数在栈中的时间总数。HTTPServe 在栈中占时为剖析时间的 65%,而各种 Go 运行时方法 runtime.mcall, mstart, gc 构成了剩下的剖析时间。一个有趣的事情是程序总运行时间的 5% 被花费在 DNS 的查询中:
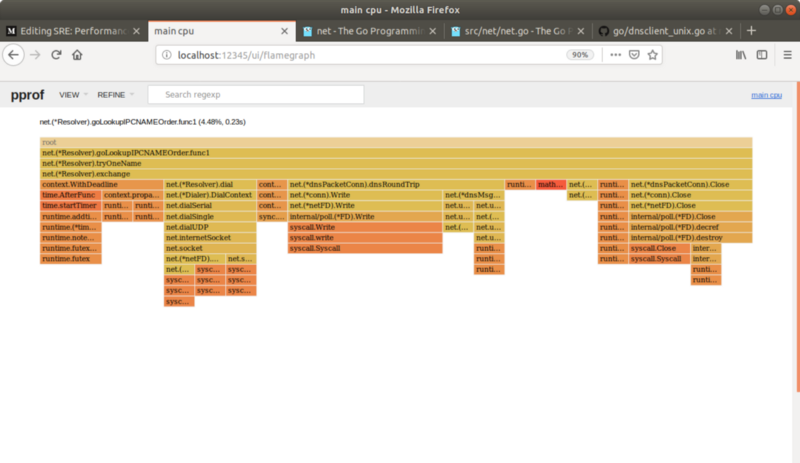
唯一的 IP 地址需要程序解析的是 Postgres 的地址。点击 FindByAge 显示:
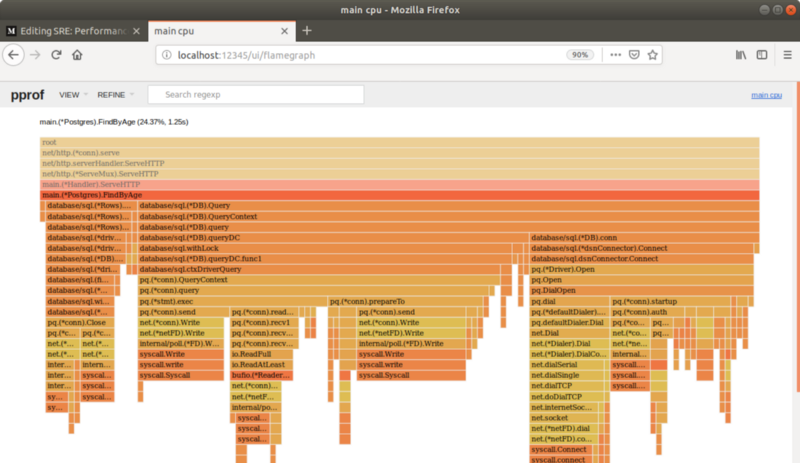
有趣的是,这个图显示了 main 源码有 3 点造成了这个延迟:关闭 / 释放连接,查询数据,和连接。基于这个火焰图, DNS 查询和连接的关闭、打开数量大概占了总的服务时间的 13%。
假说:使用连接池来重用连接可以减少 HTTP 交互时间,从而有更高的吞吐量和更低的延迟。
应用优化——实践
更新这个应用,避免每次 postgres 请求都重建连接。一个解决方法是使用应用级的 连接池 。这个实践将使用 Go sql 驱动的池配置选项 来配置一个连接池:
db, err := sql.Open("postgres", dbConnectionString)
db.SetMaxOpenConns(8)
if err != nil {
return nil, err
}
执行、观察、分析
重新运行 1000 测试负载,显示 99% 的 HTTP 请求延迟都在 60ms SLO 以下!
而成本方面:
10k 请求量 / 秒 / 1000 请求量 / 机器 = 10 台机器 + 1
我们继续尝试,看能不能更好!
2000 请求量 / 秒
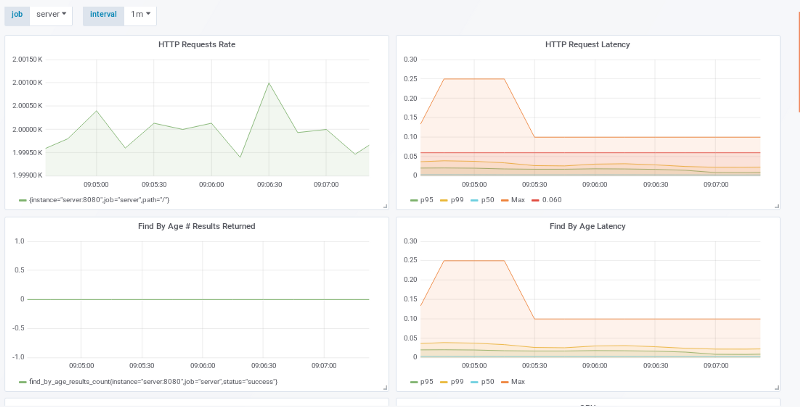
双倍请求显示也一样。左上角的图显示应用正在接收每秒 2000 的请求量,而 p100 max 客户端延迟在 60 ms 以上,p99 线却一直在 SLO 以内。
这次成本为:
10k 请求量 / 秒 / 2000 请求量 / 机器 = 5 台机器 + 1
3000 请求量 / 秒
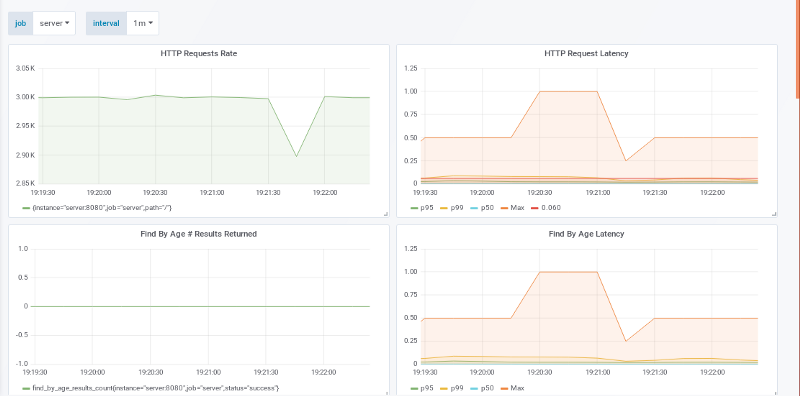
此时,这个服务能够在 3000 请求量 / 秒 的速率下,p99 延迟 < 60ms,而 p100 从 2000 请求量 / 秒 时的 100-250 ms 到此时的 250-1000 ms。这个 SLO 没有被违背,可被接受的成本为:
10k 请求量 / 秒 / 3000 请求量 / 机器 = 4 台机器 + 1
尝试更进一步的分析。
分析——假说
生成并可视化 3000 请求量 / 秒 下应用的剖析情况如下:
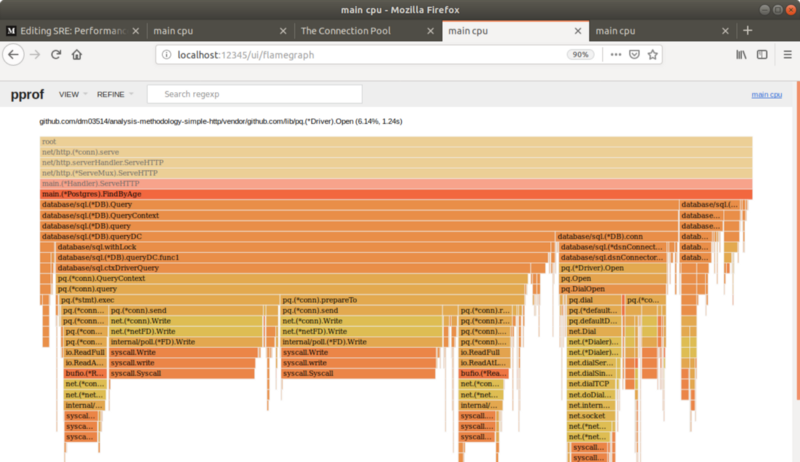
可以看出,FindByAge 6% 的交互时间是由 Dialing 连接造成的!!建立一个连接池提高了性能,但是可以观察到应用还是继续做创建新的数据库连接的重复工作!
假说:即使连接被放到池里了,但是他们一直被回收并清理导致应用必须重新连接。调整空闲连接数等于池的大小应该可以帮助减少延迟时间,最小化应用花在创建数据库连接的总时间。
应用优化——实践
我们尝试设置 MaxIdleConns 等于池的大小(或者在 这里 查看):
db, err := sql.Open("postgres", dbConnectionString)
db.SetMaxOpenConns(8)
db.SetMaxIdleConns(8)
if err != nil {
return nil, err
}
执行、观察、分析
3000 请求量 / 秒
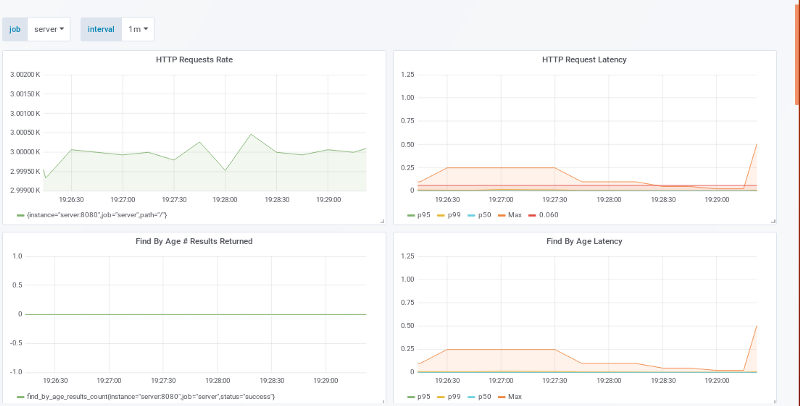
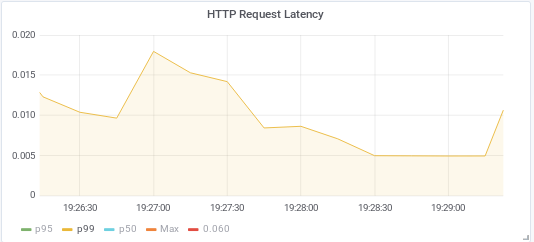
p99 总是 < 60ms !而 3000 请求量每秒也有更低的 p100 了!
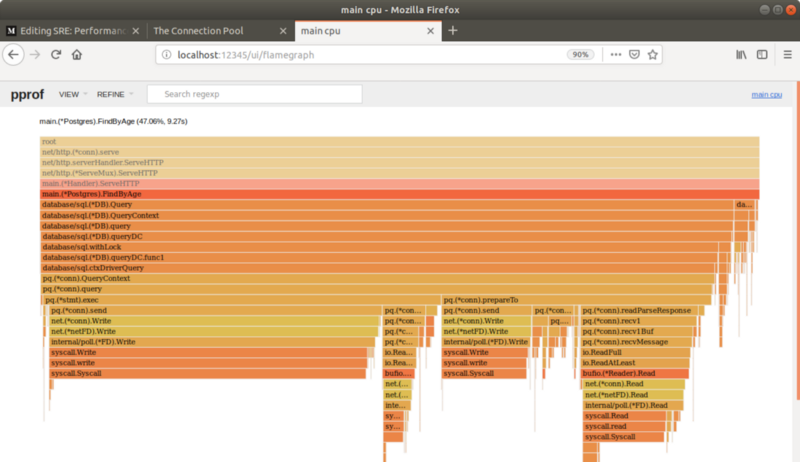
仔细观察下面的火焰图,连接的 dial 不再出现了!仔细看 pg(*conn).query 那行,整个 dialing 不再存在了:
结论
性能分析是理解是否满足客户期望和非功能需求的至关重要的手段。通过符合客户期望的审查分析性能能够帮助我们决定哪些是性能可接受的,哪些是不可接受的。Go 在标准库中提供了强大的组件,让这个分析的一系列方法变得简单易用。
我对你阅读本文表示感谢,并希望你能反馈!
作者:dm03514 译者:daliny 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




