
这篇文章登上了 Golang 在 Reddit subreddit 板块的顶部,并在 Hacker News 首页排名到第二名。欢迎各位来阅读讨论,并在 Github 上面给我们一个小星星。
每个数据库都需要一个智能的缓存系统。缓存需要保存最近最频繁访问的内容,并且支持配置一些限制上的配置。
作为一个图形数据库,Dgraph 可以在每次查询中,访问数千甚至数百万的 key。这个功能主要依赖于他中间结果的数量。由于通过键值对访问数据库会导致磁盘上的查询操作,出于对性能方面的考虑 ( 磁盘访问速度不及内存 ),我们希望优化这块的性能。
通常的访问模式都遵循 ZipFian 分布,访问频率最高的 key,比其他的 key 访问次数要多很多。从 Dgraph 中也能看到这一点 ( 热点 Key 的问题 )。
我们非常高兴能用 Go 语言来实现我们的 Dgraph 组件,关于为什么 Go 语言适合做后端开发,这个内容太多了,在这里不赘述了。尽管 Go 的生态还不够健全,但不能否认 Go 是一个很不错的编程语言,而且我们也不会用别的语言来替代 Go。
关于 Go 生态缺失的怨言随处可见。但是我觉得 Go 是成熟的,他已经实现了对机器内核的快速编译,执行和利用内核完成工作。但是作为一个致力于构建高并发的编程语言,对于性能上仍然有一些缺陷,并发库可以很好地扩展内核数量。对于并发的数组和字典,用户可以自由的使用和练习。对于串行语言来说,这样是合理的,但是对于以并行构建的编程语言,这点上似乎有一些缺陷。
特别的是,Go 缺少并发的 LRU/LFU 缓存,这两者可以很好地扩展到全局缓存中。在这片博客里面,我会带你一起来了解一下通常情况下的各种处理方式,包括在我的的 Dgraph 中进行的一些测试。Aman 同时也会展示一些目前 Go 生态中的设计理念,性能,命令率等的一些实践内容。
缓存框架的必备需求
- 并发
- 内存限制 ( 限制最大的可使用空间 )
- 在多核和多 Goroutines 之间更好的扩展
- 在非随机密钥的情况下,很好地扩展 (eg. Zipf)
- 更高的缓存命中率
Go map 与 sync.Mutex 的结合使用
Go map 结合 sync.Mutex 是应对缓存的常见形式(独占锁)。但这也确实会导致所有的 goroutines 同时在一个地方锁住,产生严重的锁竞争问题。而且也不能对内存的使用量做限制。所以对于有内存限制要求的场景,这个方案不适用。
不满足 上面的 2,3,4 条
Go maps 与 lock striping
这个方式的原理与上面的一样,但是锁的粒度更小 (详见这里), 很多程序员错误的认为,降低锁的粒度可以很好地避免竞争,特别是在分片数超过程序的线程数时 (GOMAXPROCS)
在我们尝试编写一个简单的内存限制缓存的时候,我们也是这样做的。为了保证内存可以在释放之后还给操作系统。我们定期扫描我们的分片,然后释放掉创建的 map,方便以后被再次使用。这种粗浅的方式却很有效,并且性能优于 LRU( 后面会解释 ), 但是也有很多不足。
- Go 请求内存很容易,但释放给操作系统却很难。当碎片被清空的同时,goroutines 去访问 key 的时候,会开始分配内存空间,此时之前的内存空间并没有被完全释放,这导致内存的激增,甚至会出发 OOM 错误。
- 我们没有意识到,访问的模式还受 Zipf 定律的束缚。最常访问的几个 key 仍然存在几个锁,因此产生 Goroutines 的竞争问题。这种方式不满足多核之间的扩展的需求。
不满足 上面的 2,4 条
LRU 缓存
Go 里面,groupcache 实现了一个基本的 LRU 缓存,在通过 lock striping 实现失败之后,我们通过引入 lock 的方式优化了 LRU 的这部分内容,使它支持了并发。虽然这样解决了上面描述的内存激增的问题,但是我们意识到他同样地会引入竞争的问题。
这个缓存的大小同样也依赖于缓存的条数,而不是他们消耗的内存量。在 Go 的堆上面计算复杂的数据结构所消耗的内存大小是非常麻烦的,几乎不可能实现。我们尝试了很多方式,但是都无法奏效。缓存被放入之后,大小也在不停地变化 ( 我们计划之后避免这种情况 )
我们无法预估缓存会引起多少的竞争。在使用了近一年的情况下,我们意识到缓存上面的竞争有多严重,删除掉这块之后,我们的缓存效率提高了 10 倍。
在这块的实现上,每次读取缓存会更新链表中的相对位置。因此每个访问都在等待一个互斥锁。此外 LRU 的速度比 Map 要慢,而且在反复的进行指针的释放,维护一个 map 和一个双向链表。尽管我们在惰性加载上面不断地优化,但依然遭受到严重竞争的影响。
不满足 3,4
分片 LRU 缓存
我们没有实际的去尝试,但是依据我们的经验,这只会是一个暂时的解决方法,而且并不能很好地扩展。( 不过在下面的测试里面,我们依然实现了这个解决方案 )
不满足 4
流行的缓存实现方式
许多方法的优化点是节省 GC 在 map 碎片上花费的时间。GC 的时间会随着 map 存数数量的增加而增大。减少的方案就是分配更少的数量,单位空间更大的区域,在每个空间上存储更多的内容。这确实是一个有效地方法,我们在 Badger 里面大量的使用了这个方法 (Skiplist,Table builder 等 )。 很多 Go 流行的缓存框架也是这么做的。
BigCache 的缓存
BigCache 会通过 Hash 的方式进行分片。 每个分片都包含一个 map 和一个 ring buffer。无论如何添加元素,都会将它放置在对应的 ring buffer 中,并将位置保存在 map 中。如果多次设置相同的元素,则 ring buffer 中的旧值则会被标记为无效,如果 ring buffer 太小,则会进行扩容。
每个 map 的 key 都是一个 uint32 的 hash 值,每个值对应一个存储着元数据的 ring buffer。如果 hash 值碰撞了,BigCache 会忽略旧 key,然后把新的值存储到 map 中。预先分配更少,更大的 ring buffer,使用 map [uint32] uint32 是避免支付 GC 扫描成本的好方法
FreeCache
FreeCache 将缓存分成了 256 段,每段包括 256 个槽和一个 ring buffer 存储数据。当一个新的元素被添加进来的时候,使用 hash 值下 8 位作为标识 id,通过使用 LSB 9-16 的值作为槽 ID。将数据分配到多个槽里面,有助于优化查询的时间 ( 分治策略 )。
数据被存储在 ring buffer 中,位置被保存在一个排序的数组里面。如果 ring buffer 内存不足,则会利用 LRU 的策略在 ring buffer 逐个扫描,如果缓存的最后访问时间小于平均访问的时间,就会被删掉。要找到一个缓存内容,在槽中是通过二分查找法对一个已经排好的数据进行查询。
GroupCache
GroupCache 使用链表和 Map 实现了一个精准的 LRU 删除策略的缓存。为了进行公平的比较,我们在 GroupCache 的基础上,实现了一个包括 256 个分片的切片结构。
性能对比
为了比较各种缓存的性能,我们生成了一个 zipf 分布式工作负载,并使用 n1-highcpu-32 机器运行基准测试。下表比较了三个缓存库在只读工作负载下的性能。
只读情况
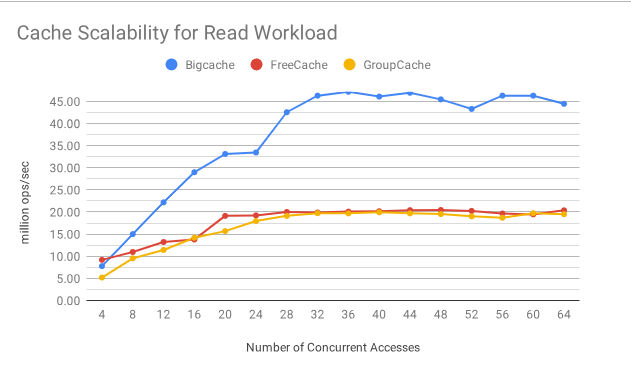
我们可以看到,由于读锁是无消耗的,所以 BigCache 的伸缩性更好。FreeCache 和 GroupCache 读锁是有消耗的,并且在并发数达到 20 的时候,伸缩性下降了。(Y 轴越大越好 )
只写情况
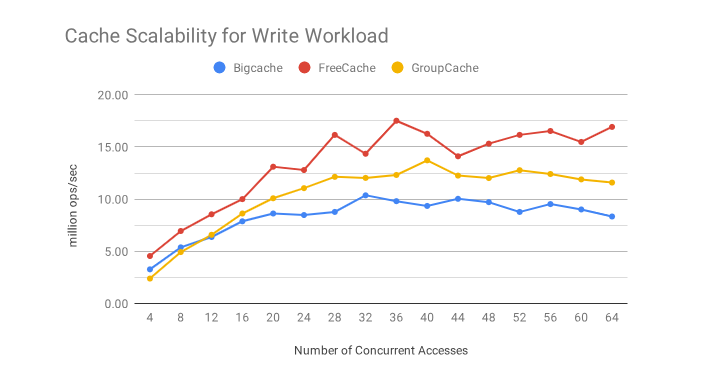
在只写的情况下,三者的性能表现比较接近,FreeCache 比另两个的情况,稍微好一点。
读写情况 (25% 写,75% 读 )
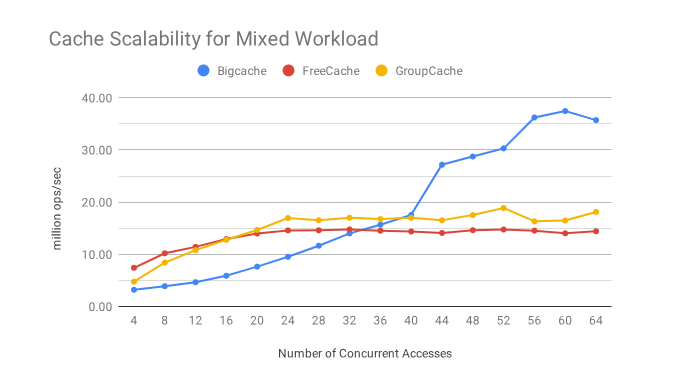
两者混合的情况下,BigCache 看起来是唯一一个在伸缩性上表现完美的,正如下一节所解释的那样,命中率对于 Zipf 工作负载是不利的。
命中率比较
下面的表格中展示了三个框架的命中率。FreeCache 非常接近 GroupCache 实现的 LRU 策略。然而,BigCache 在 zipf 分布式工作负载下表现不佳,原因如下:
- BigCache 不能有效地利用缓冲区,并且可能会在缓冲区中为同一个键存储多个条目。
- BigCache 不更新访问 ( 读 ) 条目,因此会导致最近访问的键被删除。
| CACHE SIZE (# OF ELEM) | 10000 | 100000 | 1000000 | 10000000 |
|---|---|---|---|---|
| BigCache | - | 37% | 52% | 55% |
| FreeCache | - | 38% | 55% | 90% |
| GroupCache | 29% | 40% | 54% | 90% |
所以说,没有哪个框架能满足所有缓存的需求。
那还有什么没说的么?
其实也没什么了,Go 中并没有一个能满足所有场景的智能缓存框架,如果你发现了有这种,请快快联系我。
与此同时,我们遇到了Caffeine, 一个 Java 的库,被用于 Cassandra, Finagle 和一些其他的数据库系统。他使用的是TinyLFU, 一个高效 的缓存接纳策略,并使用各种技术来扩展和执行,随着线程和内核数量的增长,同时提供接近最佳命中率。您可以在这篇文章 中了解它是如何工作的。
Caffeine 满足了我开始提到的所有的 5 个需求,所以我正在考虑构建一个 Go 版本的 Caffeine。他不仅能满足我们的需求,同时也可能填补 Go 语言中并发,高性能,内存限制的缓存框架的空白。如果你也想参与或者你已经有类似的成果了,请联系我。
感谢
我们想要感谢 Benjamin Manes 帮助我们对 Caffeine 进行一些 Go 版本的性能测试 (Code here), 我们还要感谢Damian Gryski 为我们提供了基准缓存命中率的基本框架 (这里),我们还修改了它 , 来满足我们的需要。他已经接受了我们对于他代码库 (GitHub) 的修改。
感谢阅读,如果方便的话,给我们 Github 点个星星吧。
via: https://blog.dgraph.io/post/caching-in-go/
作者:Manish Rai Jain 译者:JYSDeveloper 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





nice