
这篇文章是 "Go: 通过例子学习 Map 的设计" 的下一篇,它从高层次上介绍了 map 的设计。为了理解下文讨论的概念,我强烈建议你从上一篇文章开始阅读。
map 的内部设计向我们展示了它如何优化性能和内存管理。让我们从 map 的内存分配开始。
map 初始化
Go 提供了两种初始化 map 和内部 bucket 的方式:
- 用户明确定义了容量
m := make(map[string]int, 10)
- 第一次更新 map 的请求时初始化
m := make(map[string]int)
m[`foo`] = 1
在第二个例子中,map 的容量未指定,因此当 map m 创建时,不会创建 bucket,Go 会等待直到 map 的第一次更新时才初始化 map。因此,第二行会创建 bucket。
在上述两个案例中,map 会根据我们的需要扩容。在第一个例子中,如果我们需要多于 10 个 key,预定义的容量不会阻止 map 的扩容,它只是帮助我们优化对 map 的使用,因为按需扩容会有性能损耗。
按需扩容的影响
Go 足够智能来对 map 进行按需扩容。然而,这种原生行为是有代价的。让我们运行一些基准测试,初始化两个 map,并创建 100/1000 个键值对。前两个基准测试使用初始化容量的 map,容量分别为 100 和 1000,另一个使用容量未定义,即按需增长的 map:
// 100 allocations
name time/op
LazyInitMap100Keys-8 6.67 µ s ± 0%
InitMap100Keys-8 3.57 µ s ± 0%
name alloc/op
LazyInitMap100Keys-8 5.59kB ± 0%
InitMap100Keys-8 2.97kB ± 0%
name allocs/op
LazyInitMap100Keys-8 18.0 ± 0%
InitMap100Keys-8 7.00 ± 0%
// 1000 allocations
name time/op
LazyInitMap1000Keys-8 77.8 µ s ± 0%
InitMap1000Keys-8 32.2 µ s ± 0%
name alloc/op
LazyInitMap1000Keys-8 86.8kB ± 0%
InitMap1000Keys-8 41.2kB ± 0%
name allocs/op
LazyInitMap1000Keys-8 66.0 ± 0%
InitMap1000Keys-8 7.00 ± 0%
在这里,我们很清晰的看到扩容和迁移 bucket 的代价,它多消耗了 80% 到 140% 的时间。内存消耗也受到了相同比例的影响。Go 对 map 进行了精妙的设计来减少内存消耗。
bucket 填充
正如之前看到的,每个 bucket 仅包含 8 个键值对。这里有一件有趣的事情值得注意,Go 先存储 key,后存储 value:
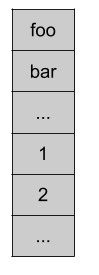
这避免了填充齐导致的内存浪费。事实上,由于 key 和 value 的大小可能不同,最终可能导致大量的内存填充。下面是两个 string / bool 对的例子,展示了 key 和 value 混在一起的情况:
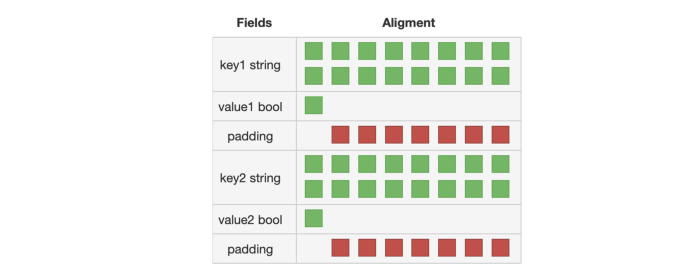
如果 key 和 value 分别分组存放:
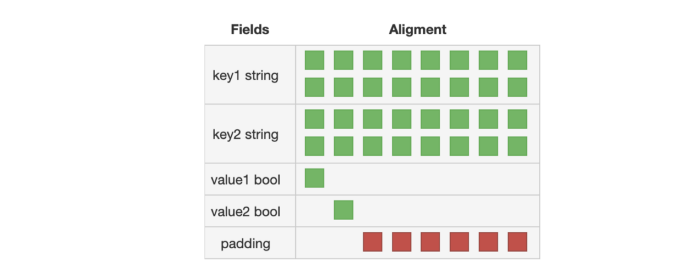
我们可以清楚的看到,填充被消除了很多。下面看一下如何访问这些值。
数据访问
Go 提供了两种访问 map 中数据的方式:
m := make(map[string]int)
v := m[`my_key`]
v, ok := m[`my_key`]
我们可以单独访问值,也可以携带一个布尔变量,用来表示是否在 map 中找到该值。我们可能会好奇,既然所有的返回值都应该明确的映射到一个变量,至少是 _,怎么可能会有两种访问方式。实际上,Go 生成的汇编代码 会给我们提示:
(main.go:3) CALL runtime.mapaccess1_faststr(SB)
(main.go:4) CALL runtime.mapaccess2_faststr(SB)
我们可以看到,根据你访问数据的方式,编译器将会使用拥有正确签名的两个不同的内部方法:
func mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer
func mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool)
编译器的这个小技巧非常有用,使我们可以灵活地访问数据。其实编译器甚至做的比这更好,它可以根据 map 的类型来选择数据访问方法。在这个例子中,我们的 map 使用 string 作为 key,编译器会选择 mapaccess1_faststr 作为数据访问方法。后缀 str 表明了它对于 string 作为 key 的 map 进行了优化。让我们尝试使用 integer:
m := make(map[int]int)
v := m[1]
v, ok := m[1]
汇编代码会为我们选择如下方法:
(main.go:3) CALL runtime.mapaccess1_fast64(SB)
(main.go:4) CALL runtime.mapaccess2_fast64(SB)
这次,编译器将会使用 int64(在 64 位机器上,是 int) 作为 key 的专用方法。每个方法都会针对哈希比较进行优化,如果开发人员在分配 map 时未指定容量,惰性初始化也会被优化。
下一篇,也就是这个系列的最后一篇文章 "Go: 并发访问 Map",将会讲解 map 在并发上下文中的表现。
via: https://medium.com/@blanchon.vincent/go-map-design-by-code-part-ii-50d111557c08
作者:blanchon.vincent 译者:DoubleLuck 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




