

写在前面
本文基于 Golang 1.14
Go 提供了 channel 或 mutex 等内存同步机制,有助于解决不同的问题。在共享内存的情况下,mutex 可以保护内存不发生数据竞争(data race)。不过,虽然存在两个 mutex,但 Go 也通过 atomic 包提供了原子内存基元来提高性能。在深入研究解决方案之前,我们先回过头来看看数据竞争。
数据竞争
当两个或两个以上的 goroutine 同时访问同一块内存区域,并且其中至少有一个在写时,就会发生数据竞争。虽然 map 内部有一定的机制来防止数据竞争,但一个简单的结构体并没有任何的机制,因此容易发生数据竞争。
为了说明数据竞争,我以一个goroutine 持续更新的配置为例向大家展示一下。
package main
import (
"fmt"
"sync"
)
type Config struct {
a []int
}
func main() {
cfg := &Config{}
// 启动一个 writer goroutine,不断写入数据
go func() {
i := 0
for {
i++
cfg.a = []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}
}
}()
// 启动多个 reader goroutine,不断获取数据
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < 100; n++ {
fmt.Printf("%#v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
运行这段代码可以清楚地看到,原本期望是运行上述代码后,每一行的数字应该是连续的,但是由于数据竞争的存在,导致结果是非确定性的。
F:\hello>go run main.go
[...]
&main.Config{a:[]int{180954, 180962, 180967, 180972, 180977, 180983}}
&main.Config{a:[]int{181296, 181304, 181311, 181318, 181322, 181323}}
&main.Config{a:[]int{181607, 181617, 181624, 181631, 181636, 181643}}
我们可以在运行时加入参数 --race 看一下结果:
F:\hello>go run --race main.go
[...]
&main.Config{a:[]int(nil)}
==================
&main.Config{a:[]int(nil)}
WARNING: DATA RACE&main.Config{a:[]int(nil)}
Read at 0x00c00000c210 by Goroutine 9:
reflect.Value.Int()
D:/Go/src/reflect/value.go:988 +0x3584
fmt.(*pp).printValue()
D:/Go/src/fmt/print.go:749 +0x3590
fmt.(*pp).printValue()
D:/Go/src/fmt/print.go:860 +0x8f2
fmt.(*pp).printValue()
D:/Go/src/fmt/print.go:810 +0x289a
fmt.(*pp).printValue()
D:/Go/src/fmt/print.go:880 +0x261c
fmt.(*pp).printArg()
D:/Go/src/fmt/print.go:716 +0x26b
fmt.(*pp).doPrintf()
D:/Go/src/fmt/print.go:1030 +0x326
fmt.Fprintf()
D:/Go/src/fmt/print.go:204 +0x86
fmt.Printf()
D:/Go/src/fmt/print.go:213 +0xbc
main.main.func2()
F:/hello/main.go:31 +0x42
Previous write at 0x00c00000c210 by goroutine 7:
main.main.func1()
F:/hello/main.go:21 +0x66
goroutine 9 (running) created at:
main.main()
F:/hello/main.go:29 +0x124
goroutine 7 (running) created at:
main.main()
F:/hello/main.go:16 +0x95
==================
为了避免同时读写过程中产生的数据竞争最常采用的方法可能是使用 mutex 或 atomic 包。
Mutex?还是 Atomic?
标准库在 sync 包提供了两种互斥锁 :sync.Mutex 和 sync.RWMutex。后者在你的程序需要处理多个读操作和极少的写操作时进行了优化。
针对上面代码中产生的数据竞争问题,我们看一下,如何解决呢?
使用 sync.Mutex 解决数据竞争
package main
import (
"fmt"
"sync"
)
// Config 定义一个结构体用于模拟存放配置数据
type Config struct {
a []int
}
func main() {
cfg := &Config{}
var mux sync.RWMutex
// 启动一个 writer goroutine,不断写入数据
go func() {
i := 0
for {
i++
// 进行数据写入时,先通过锁进行锁定
mux.Lock()
cfg.a = []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}
mux.Unlock()
}
}()
// 启动多个 reader goroutine,不断获取数据
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < 100; n++ {
// 因为这里只是需要读取数据,所以只需要加一个读锁即可
mux.RLock()
fmt.Printf("%#v\n", cfg)
mux.RUnlock()
}
wg.Done()
}()
}
wg.Wait()
}
通过上面的代码,我们做了两处改动。第一处改动在写数据前通过 mux.Lock() 加了一把锁;第二处改动在读数据前通过 mux.RLock() 加了一把读锁。
运行上述代码看一下结果:
F:\hello>go run --race main.go
&main.Config{a:[]int{512, 513, 514, 515, 516, 517}}
&main.Config{a:[]int{512, 513, 514, 515, 516, 517}}
&main.Config{a:[]int{513, 514, 515, 516, 517, 518}}
&main.Config{a:[]int{513, 514, 515, 516, 517, 518}}
&main.Config{a:[]int{513, 514, 515, 516, 517, 518}}
&main.Config{a:[]int{513, 514, 515, 516, 517, 518}}
&main.Config{a:[]int{514, 515, 516, 517, 518, 519}}
[...]
这次达到了我们的预期并且也没有产生数据竞争。
使用 atomic 解决数据竞争
package main
import (
"fmt"
"sync"
"sync/atomic"
)
type Config struct {
a []int
}
func main() {
var v atomic.Value
// 写入数据
go func() {
var i int
for {
i++
cfg := Config{
a: []int{i, i + 1, i + 2, i + 3, i + 4, i + 5},
}
v.Store(cfg)
}
}()
// 读取数据
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < 100; n++ {
cfg := v.Load()
fmt.Printf("%#v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
这里我们使用了 atomic 包,通过运行我们发现,也同样达到了我们期望的结果:
[...]
main.Config{a:[]int{219142, 219143, 219144, 219145, 219146, 219147}}
main.Config{a:[]int{219491, 219492, 219493, 219494, 219495, 219496}}
main.Config{a:[]int{219826, 219827, 219828, 219829, 219830, 219831}}
main.Config{a:[]int{219948, 219949, 219950, 219951, 219952, 219953}}
从生成的输出结果而言,看起来使用 atomic 包的解决方案要快得多,因为它可以生成更高的数字序列。
为了更加严谨的证明这个结果,我们下面将对这两个程序进行基准测试。
性能分析
一个 benchmark 应该根据被测量的内容来解释。因此,我们假设之前的程序,有一个不断存储新配置的 数据写入器,同时也有多个不断读取配置的 数据读取器。为了涵盖更多潜在的场景,我们还将包括一个只有 数据读取器 的 benchmark,假设 Config 不经常改变。
下面是部分 benchmark 的代码:
func BenchmarkMutexMultipleReaders(b *testing.B) {
var lastValue uint64
var mux sync.RWMutex
var wg sync.WaitGroup
cfg := Config{
a: []int{0, 0, 0, 0, 0, 0},
}
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < b.N; n++ {
mux.RLock()
atomic.SwapUint64(&lastValue, uint64(cfg.a[0]))
mux.RUnlock()
}
wg.Done()
}()
}
wg.Wait()
}
执行上面的测试代码后我们可以得到如下的结果:
name time/op
AtomicOneWriterMultipleReaders-4 72.2ns ± 2%
AtomicMultipleReaders-4 65.8ns ± 2%
MutexOneWriterMultipleReaders-4 717ns ± 3%
MutexMultipleReaders-4 176ns ± 2%
基准测试证实了我们之前看到的性能情况。为了了解 mutex 的瓶颈到底在哪里,我们可以在启用 tracer 的情况下重新运行程序。
更多关于
tracer的内容,请参考trace这篇文章。
下图是使用 atomic 包时,使用 pprof 分析后得到 profile 结果:
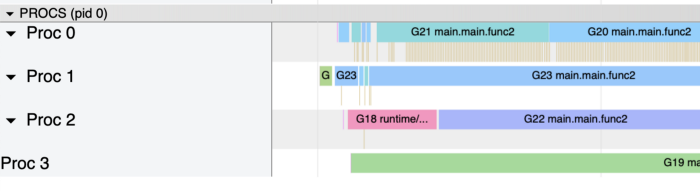
goroutines 运行时不间断,能够完成任务。对于带有 mutex 的程序的配置文件,得到的结果那是完全不同的。
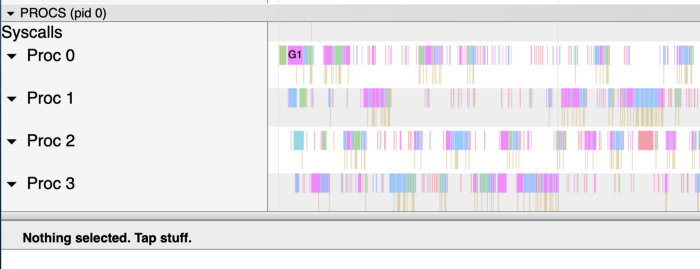
现在运行时间相当零碎,这是由于停放 goroutine 的 mutex 造成的。这一点可以从 goroutine 的概览中得到证实,其中显示了同步时被阻塞的时间(如下图)。
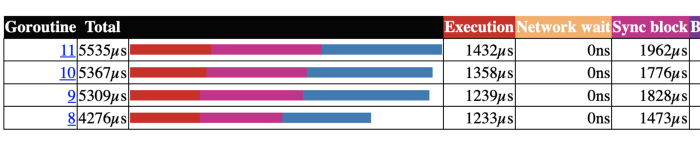
屏蔽时间大概占到三分之一的时间,这一点可以从下面的 block profile 的图中详细看到。
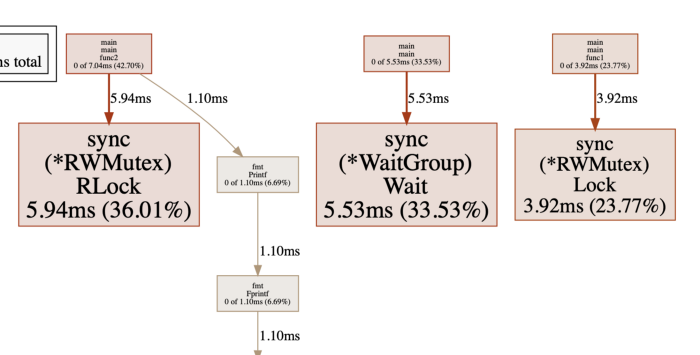
在这种情况下,atomic 包肯定会带来优势。但是,在某些方面可能会降低性能。例如,如果你要存储一张大地图,每次更新地图时都要复制它,这样效率就很低。
更多关于
mutex的内容可以参考Go: Mutex and Starvation
作者:Vincent Blanchon 译者:double12gzh 校对:lxbwolf
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))




